
[Udemy] AWS Certified Data Analytics Specialty - 4.Analysis
Kinesis Data Analytics
Analytics 可以和 Lambda集成

RANDOM_CUT_FOREST, 异常检测算法
OpenSearch = ElasticSearch
OpenSearch 包含了ES生态里的ElasticSearch+Kibaba, 分别叫OpenSearch+Dashboard, ES生态里的Beats/LogStach用Kinesis替代了。

OpenSearch 是Fully-managed, 但不是serverless的,我理解serverless 是说啥也不用管,AWS会根据用户使用情况auto scale, fully-managed还是需要用户指定需要多少Node、跑什么软件在上面,等等,好像Glue就是serverless的,EMR就是fully-managed.

OpenSearch Security

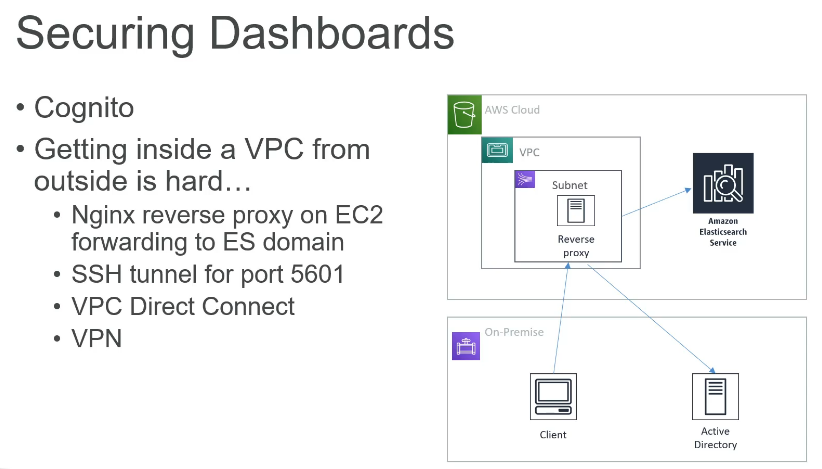
OpenSearch放在VPC里面就不能拿出来了,所有怎么从public访问OpenSearch呢?






Athena

Athena我理解是从给数据(结构、非结构、半结构) 提供一层SQL接口,操作Athena后面的数据就像操作一个数据库一样。具体比如非结构数据,Athena需要下层的Glue Catalog支持。

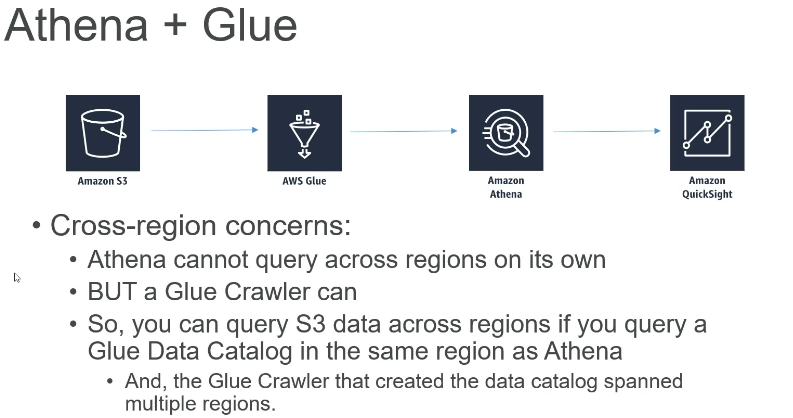
Athena+Glue
Glue 的 Crawler 查看S3里面的非结构化数据,尝试建立table definition, 如果生成的不合适,可以在Glue console里面refine. Glue Data Catalog生成后,Athena能自动发现, 并自动生成一个table





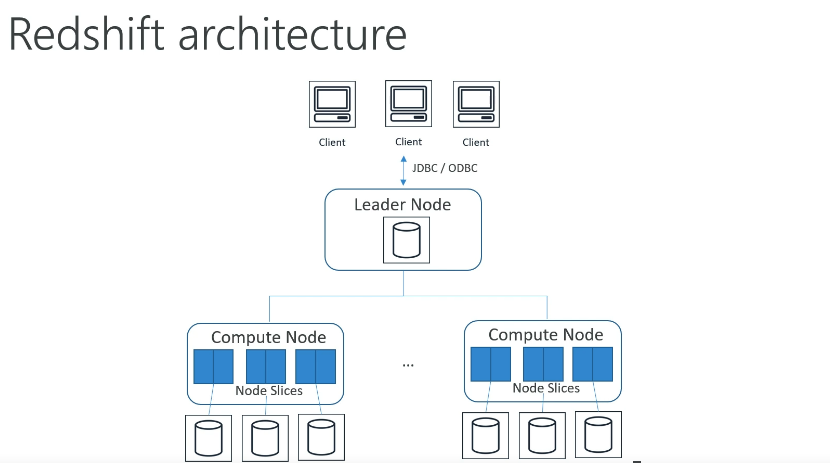
RedShift
Scale up or down 很简单,但是不是自动的

Compute Node 有 DS(Dense Stroage) 和 DC(Dense Compute) 型
支持压缩


如果是drive坏了,能自动恢复,因为cluster上有其他盘的replica数据,功能不受影响,指示重建新的drive时候性能有影响;
如果是node 坏了,也能自动恢复,但是功能不能用了,只能等恢复好了再用
如果所在的AZ坏了,因为Redshift 只在一个AZ有,那就只有等好了,或者是在这个region里其他AZ里用snapshot恢复


按照什么规则往slices上放:
Even - round robin规则,把每行数据轮流放在slices里
Key - 就是根据某列数据值hash过后的key,然后放到对应的slices。
ALL - 好像是数据在每个node上都有保存一份

Sort Key 和关系型数据库的index类似,有 single, compound, interleaved 3种
single 就是单列
compound 是多列, 默认类型,但是查询时候也要按照定义好的顺序来,help improve compression
interleaved 也是多列,每列权重一样,可以任意选某列query, 不像compound有顺序



建立一个带KMS key 的 copy grant 作为目标,可以把KMS加密的 Redshift snapshot 跨region的拷贝过去



query的优先级管理

可以有不同的queue, 由WLM管理,哪个queue支持concurrency scaling cluster, 哪个queue不支持

WLM 中的一种是 Automatic WLM. Large queries 和 Small queries 分别用不同queue提高资源利用率
下面queue 的 concurrency scaling mode 就是可以对接 concurrency scaling cluster的

WLM的另一种是manual WLM

SQA是WLM的可替代品. 自动把short query优先级提升

VACUUM 恢复删除rows后的空间,重新排序。 Full就是两个事情都做,Delete Only 就是只做回收deleted rows后的空间;Sort Only 只re-sort; Reindex是先reanalyze distributes of value然后 Full


如果 concurrency scaling 还不行的时候, 就需要 Resize Redshift Cluster了.


