
AWS Data Analytics Fundamentals 官方课程笔记 - Intro, Volumn, Velocity
Intro
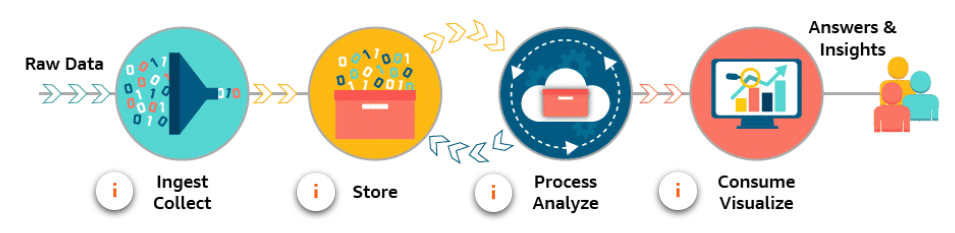
process 就是 The process component is where services manipulate data into needed forms. 比如补齐 null value, make data more consumable.
analyze 比如排序、聚合、Join 及更负责的机器学习算法等,Extract key information from the data
challedges :
5 V's - Volume, Velocity, Variaty, Veracity, Value
Volumn
1. intro to S3 可以存大量数据
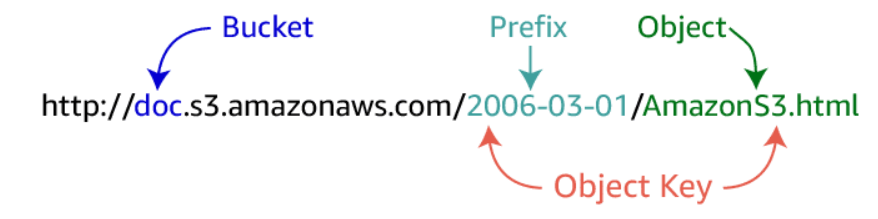
"bucket + key + version" 唯一的确定了一个object
2. data lake
S3 data lake 感觉就是一个统一管理s3 buckets的工具,这样就不用单独管理各个buckets了.
streaming data 可以通过Kinesis 流入data lake, on-premise data 也就是传统数据可以通过 Snowball 放入data lake. Glue可以用来catalog 数据湖里面的数据,一旦catalog以后就可以检索数据了.
Lake Formation 是AWS的数据湖服务, 感觉是更像一个管理 data lake 的封装层 AWS Lake Formation is a service that organizes and curates data within Amazon S3 data lakes
3. data storage methods, 主要讲 data warehouse的,和data lake 对应的一个概念,warehouse存的结构化数据,一般用来做BI分析. AWS 的warehouse服务叫 Amazon Redshift. 那么问题来了,我们有了 S3 data lake 又有了Redshift warehouse, 可以从两个地方同时取数据吗? 答案是肯定的,用 Amazon Redshift Spectrum 服务,感觉是把 data lake 和 warehouse 装在一起像一个数据源一样.
还讲了 Amazon EMR, 就是Amazon自己的数据处理产品,包含有(Hadoop, Spark, HBase, Presto, and Flink等 )和 S3 storage 无缝集成
Amazon除了支持HDFS, 还支持一种自己的 EMRFS 文件系统。 EMRFS文件系统能直接识别S3, 相比copy到HDFS再处理,可以省去copy的过程, 大大提高了性能.
Velocity
batch/streaming
Kinesis 是用来处理流数据的. 下图的细分的区别还不了解

batch data processing
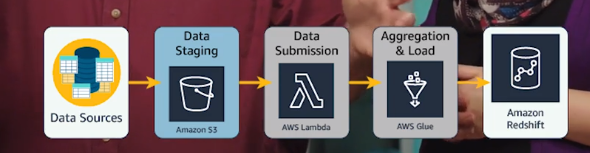
使用Amazon EMR的一个简单方案: 最后一步看不清是Redshift

EMR 需要配置的比较多,有没有更少配置项的. 那就是 Glue. 原文如下:
This is where AWS Glue come in. AWS Glue is a fully managed ETL service that categorizes, cleans, enriches, and moves your data reliably between various data stores. AWS Glue simplifies and automates difficult and time-consuming data discovery, conversion, mapping, and job-scheduling tasks. In other words, it simplifies data processing.
如果用Glue, 方案改成下面的,就是直接替换 EMR.
Stream data processing
Kinesis 包含了收集和处理流数据的功能,主要有以下组件 Kinesis Data Firehose, Kinesis Data Streams, and Kinesis Data Analytics, Amazon Kinesis Video Streams
流处理架构, Firehose收集流数据,Data Analytics 过滤数据然后又发到下一个Firehose, 然后发到S3, Athena是个交互式SQL工具,query到结果放到 QuickInsight BI 工具展示.
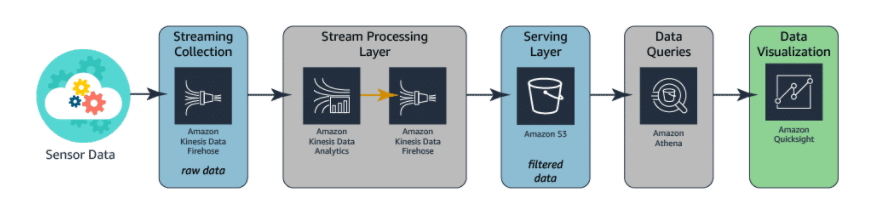

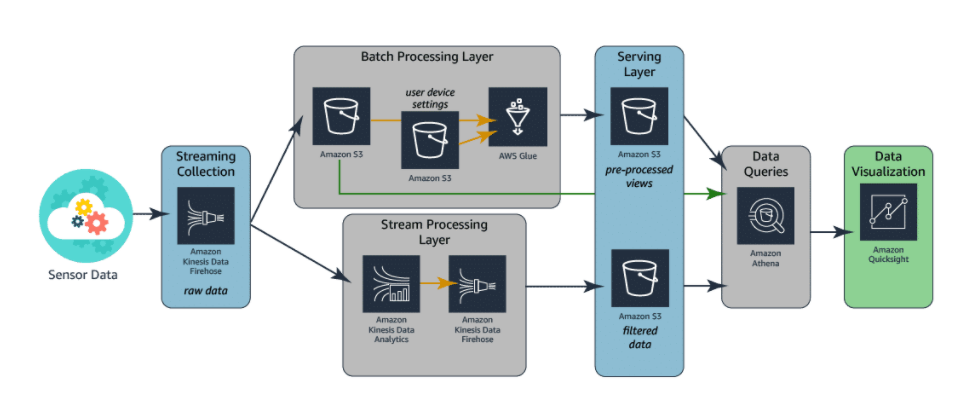
Glue ? Within AWS, Hadoop frameworks are implemented using Amazon EMR and AWS Glue
Amazon Athena - is an interactive query service that makes it easy to analyze data in Amazon S3 using the standard structured query language (SQL). Athena is serverless, so there is no infrastructure to manage, and you pay only for data scanned by the queries you run. You can then use the results of these queries to produce insightful dashboards and reports using Amazon QuickSight (BI 工具).

