
spark 先groupby 再从每个group里面选top n
import spark.implicits._ val simpleData = Seq(("James","Sales","NY",90000,34,10000), ("Michael","Sales","NY",86000,56,20000), ("Robert","Sales","CA",81000,30,23000), ("Maria","Finance","CA",90000,24,23000), ("Raman","Finance","CA",99000,40,24000), ("Scott","Finance","NY",83000,36,19000), ("Jen","Finance","NY",79000,53,15000), ("Jeff","Marketing","CA",80000,25,18000), ("Kumar","Marketing","NY",91000,50,21000) ) val df = simpleData.toDF("employee_name","department","state","salary","age","bonus") df.show()
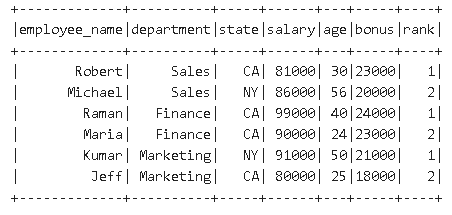
import org.apache.spark.sql.functions._ import org.apache.spark.sql.expressions.Window // Window definition val w = Window.partitionBy($"department").orderBy(desc("bonus")) // Filter var df_1 = df.withColumn("rank", rank.over(w)).where($"rank" <= 2) df_1.show()
转载请注明出处 http://www.cnblogs.com/mashuai-191/

