HIVE 学习
HIVE 安装
安装完成的测试

用 hive 客户端前要先起 hive服务: hive --service metastore , 后来测试 hiveserver2 的 beeline客户端也可以用这个服务. 那么问题是 hiveserver2本身的service start起来不能用不知道为什么?
- How to Install Apache Hive with Hadoop on CentOS, Ubuntu and LinuxMint https://tecadmin.net/install-apache-hive-on-centos-rhel/
- GettingStarted
结合Zeppelin使用时候观察到的一些现象
- 在zeppelin notebook里,没有设置spark.sql.catalogImplementation = hive, 设置 spark.sql.warehouse.dir = file:///nfs/test_spark_houseware,结果是
- 可以registerTempTable(), 可以show tables, 没有看到 metastore_db目录,restart interpreter没有以前创建的 tables
- 可以saveAsTable(), 可以show tables, 没有看到 metastore_db目录, restart interpreter没有以前创建的 tables. 虽然不能show tables, 但是因为以前创建的table还在 spark.sql.warehouse.dir 里面,所有无法创建同名table.
- 总结是:zeppelin 模式下derby 数据库的metastore_db 在内存里,重启interpreter就消失了.
- 单独使用spark-shell https://www.tutorialspoint.com/spark_sql/spark_sql_hive_tables.htm
- 在当前目录下会自动生成 metastore_db, spark_warehouse 目录
- 杀掉以前的spark-shell, 新起一个去show tables, 报已经被其他instance占用,这是因为derby 只支持一个spark session,

- 删除掉 metastore_db下面的 db.lck, dbex.lck 就可以show tables了
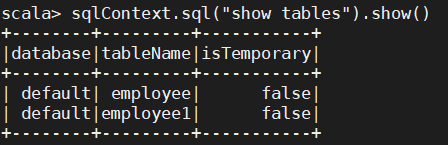
3. 在zeppelin notebook里,设置spark.sql.catalogImplementation = hive, spark.sql.catalogImplementation = hive, 结果是在当前目前生成 metastore_db, 重启interpreter 也可以show tables.
怎么配置hive 使用mysql 数据库而不是默认的derby
Ref:
转载请注明出处 http://www.cnblogs.com/mashuai-191/
