
[Udemy] ES 7 and Elastic Stack - part 1
Section 1 基本概念:
Index(indices) 相当于 关系型数据库的 table, document 相当于关系型数据库的 row, 还有一个type的概念(可以理解为table的schema)是属于 index的,一个index 只能有一种type,

ES怎么扩展? 用shards, 一个shard 就是整个文档的一个part, 可以分布在cluster内部的不同机器上

Section 2 Mapping and Indexing Data
mapping: 相当于schema定义
field 就是列名
field type 数据类型,field index 要不要被full-text 检索, field analyzer 定义语言

Analyzer主要做3件事情:

有以下几种 analyzer可选:

创建mapping, 就是给movies 整个Index 创建schema

创建了以后get一下

insert 一个movie document(row)

get 刚刚insert 的 document

批量Insert documents:
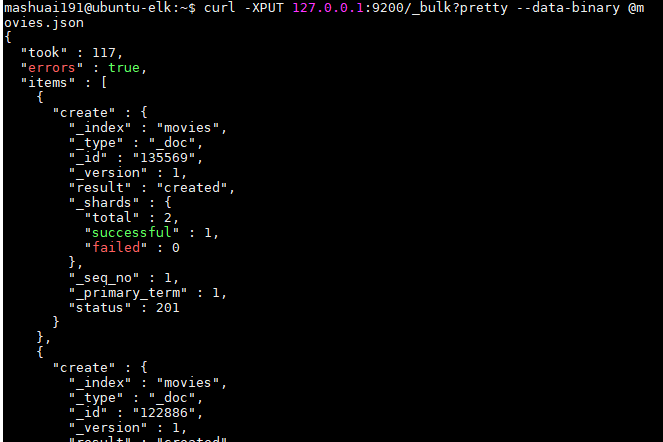
可以get 刚才批量插入的documents
curl -XGET 127.0.0.1:9200/movies/_search?pretty
update document
下面是update API,还可以用-XPUT 加上所有的field 来update.

Delete document
curl -XDELETE 127.0.0.1:9200/movies/_doc/58559
full text search
有精确匹配("type": keyword)和模糊匹配("type": text)两种
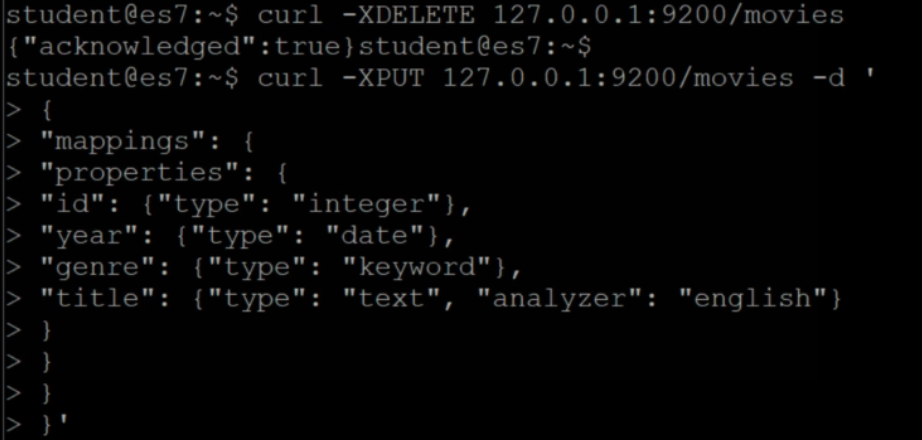
改一下schema, 体会一下 keyword 和 text
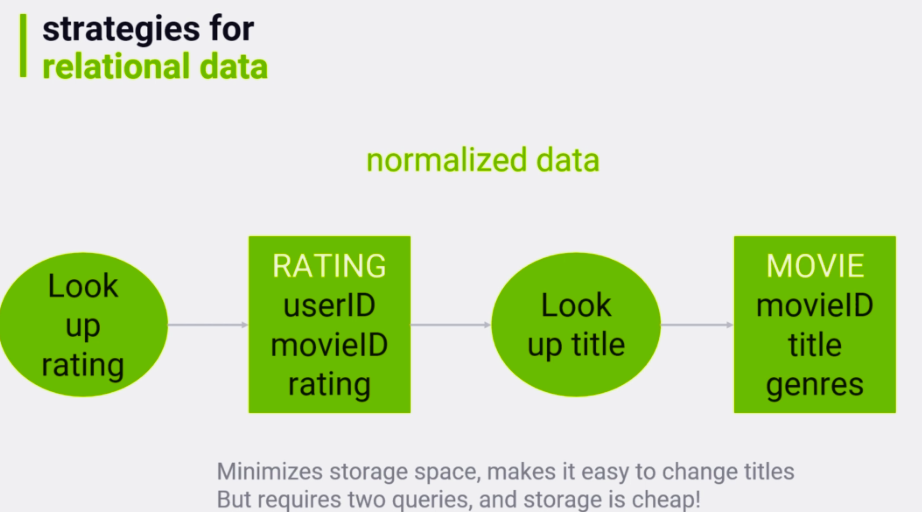
Modeling:
normalized data:
denormalized data

parent / child relationship
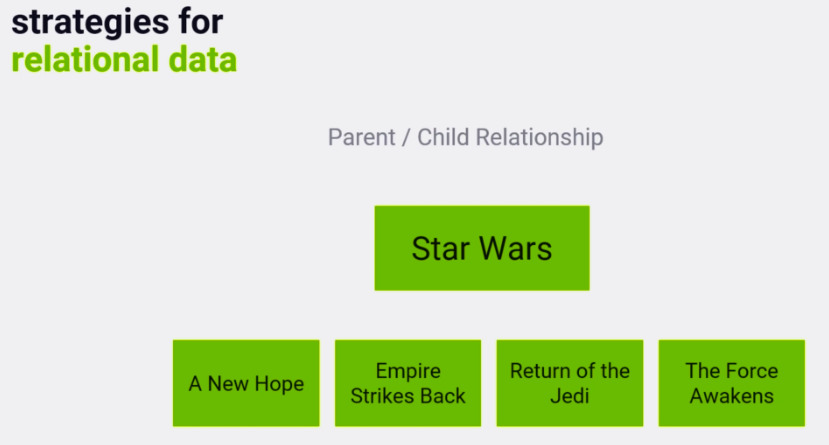
Ref:
ElasticStack7 note book http://media.sundog-soft.com/es7/ElasticStack7.pdf

