


Coursera, Big Data 1, Introduction (week 3)
什么是分布式文件系统?为什么需要分布式文件系统?
如果文件系统可以管理用网络连接的很多个存储单元,叫分布式文件系统. 分布式文件系统提供了数据可扩展性,容错性,高并发. 这些是传统文件系统不具有的.
Hadoop getting started
为什么用Hadoop? Hadoop 的 4 个What 和 How.

Hadoop 的主要Goal:
1. 可扩展来增加 node
2. 容错,Node down 可以很容易recover
3. 可以读取各种格式的数据(structured, unstructured)
4. 把task 分配到不同node,具有并行计算能力
Hadoop 生态系统:
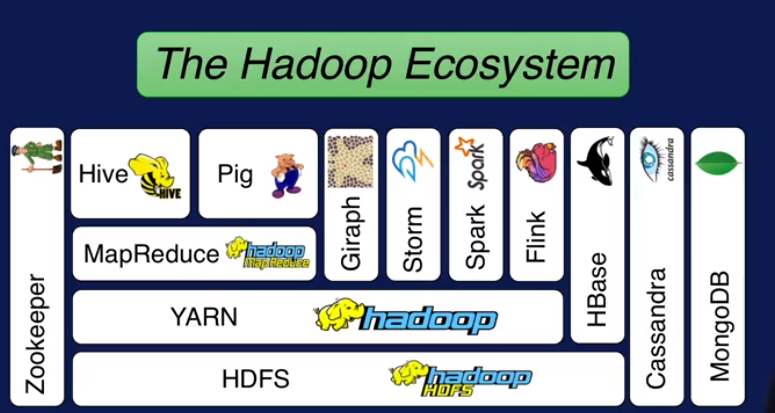
接下来先将整个Hadoop 生态系统,然后讲主要模块(HDFS分布式存储, YARN提供调度和资源管理, MapReduce并行计算) ,最后讲云计算(IaaS, PaaS, SaaS), 此外还有什么时候不适用 Hadoop.
zhihu 上找到的一个包含了很多新模块的图 (https://www.zhihu.com/question/27974418)

Hadoop生态系统:
前面已经提到了HDFS 是管理分布式存储的, YARN 是负责调度和管理资源的,MapReduce 是做分布式计算的,用户只需要写两个函数就可以实现分布式计算了.
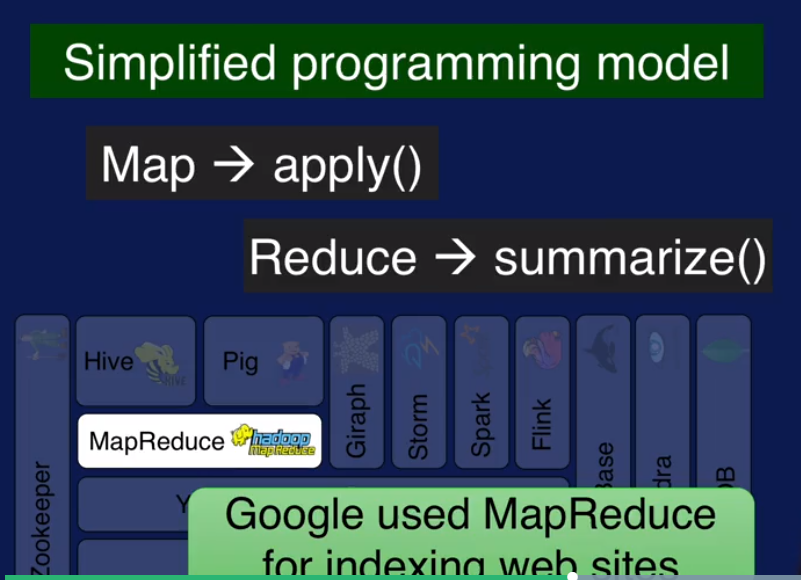
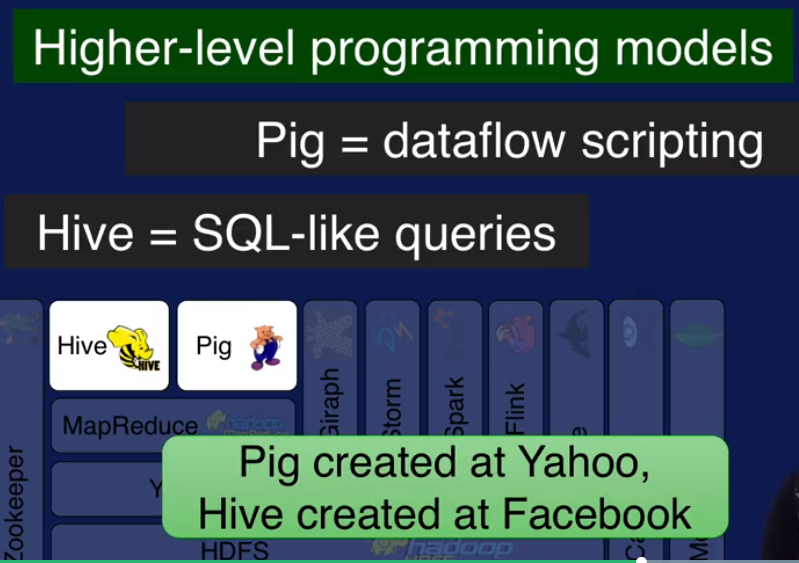
MapReduce 支持的数据model 有限,Hive 和 Pig 是分别针对 SQL-Like query 和 dataflow 类型数据的,可以理解为对MapReduce的扩展.
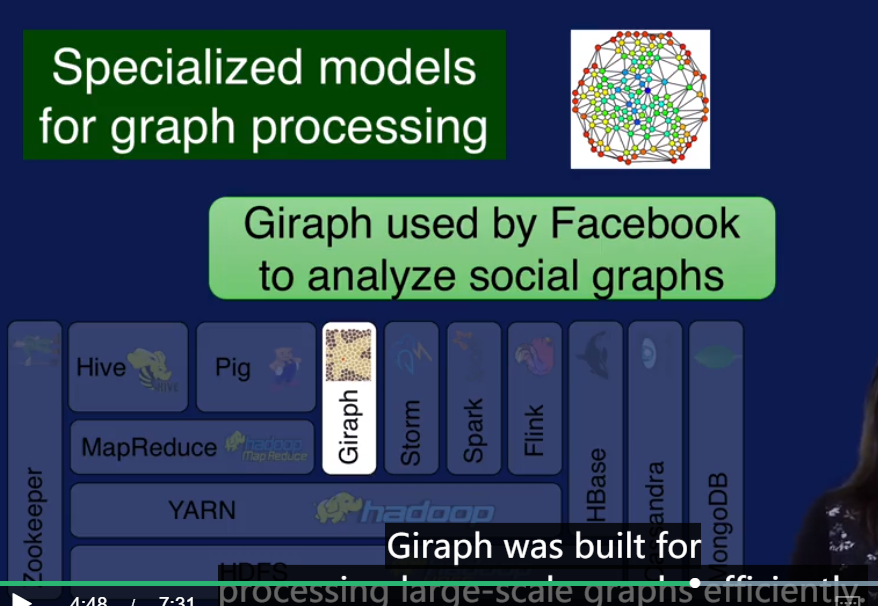
Giraph 用来处理大规模图表.
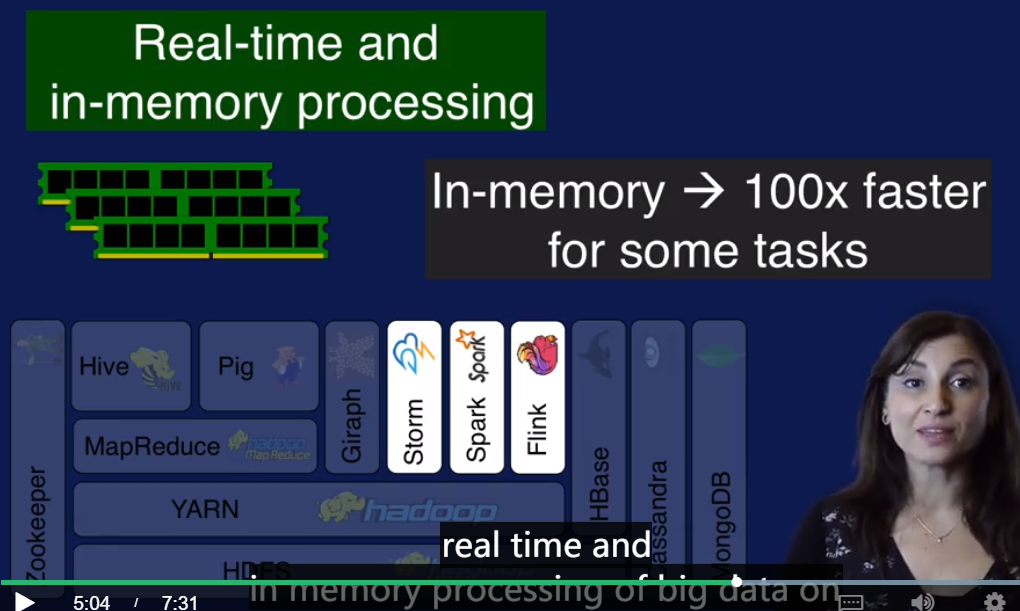
Storm, Spark, Flink 是内存处理大数据的技术.
Strom for streaming data analysis. Spark for in-memory data analysis.
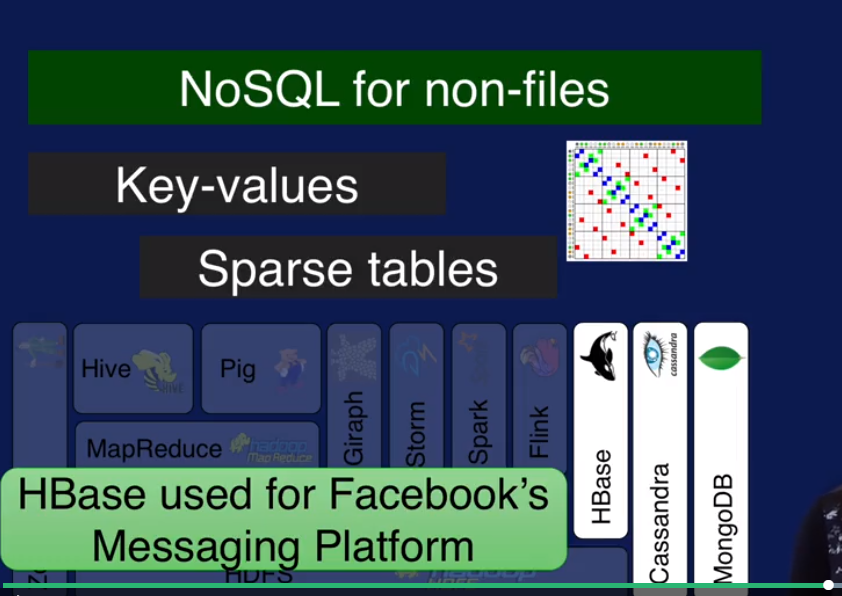
HBase, Cassandra, MongoDB 来处理一些不适合放在关系型数据库的数据,比如 key-value 数据,Sparse tables 数据. 这些都属于 NoSQL 数据库.
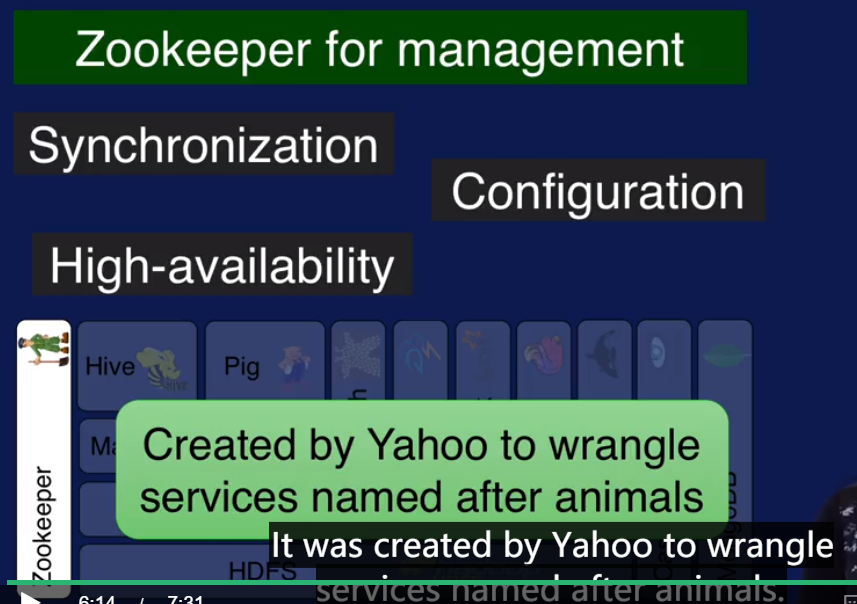
有了上面介绍的这么多模块,需要一个统一的集中管理工具来管理,就是Zookeeper.
这么多工具,如果自己来安排配置其实挺麻烦的,所有就有一些公司提供了集成的预装好的core工具集合,并对production env提供Support. 比如 Cloudera, MAPR, Hortonworks.

讲完了整个生态系统,接下来分别讲模块.
HDFS:
HDFS 怎么提供扩张性和可靠性? 以及它的两个关键模块 NameNode 和 DataNode.

HDFS 默认每一块数据放三份拷贝来提供可靠性. HDFS支持多种数据类型, 读和写时都需要提供数据类型.
HDFS由两种node 组成, Name Node (一般一个cluster就一个)和 Data Node (每个machine都是一个 data node).
YARN: Resource manager for Hadoop
1. Resource manager and node manager
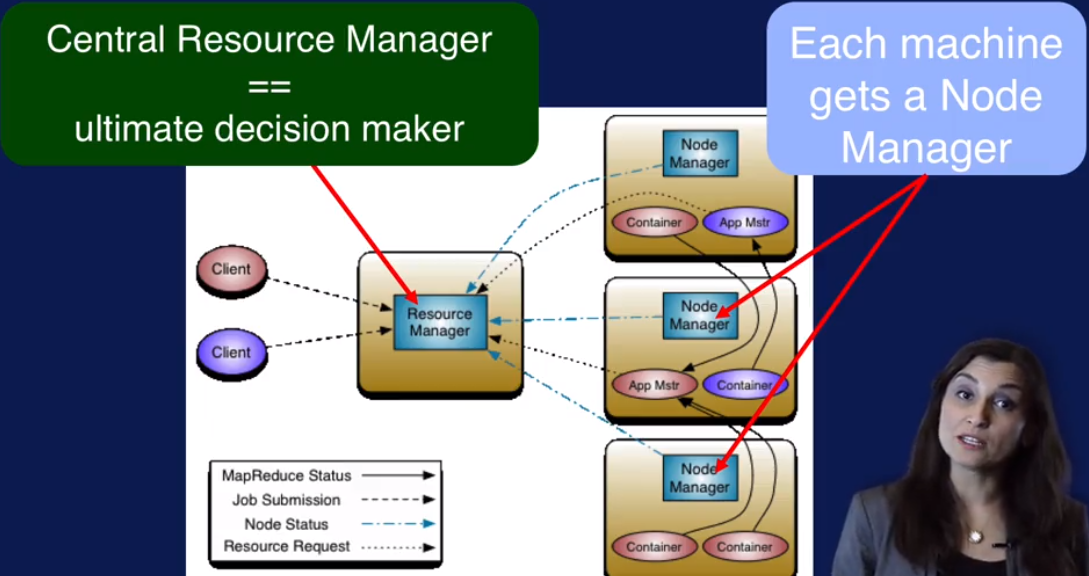
2. Appliacation Master 就像一个谈判人员, 从resource manager 协调资源,让node manager 来负责执行。
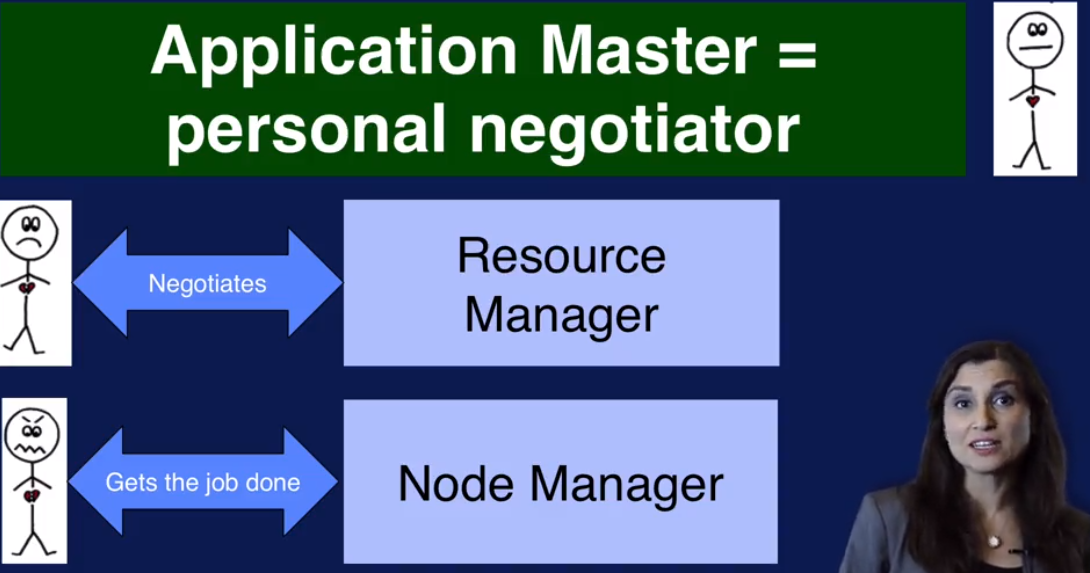
3. Container: 可以把它看做资源的抽象.
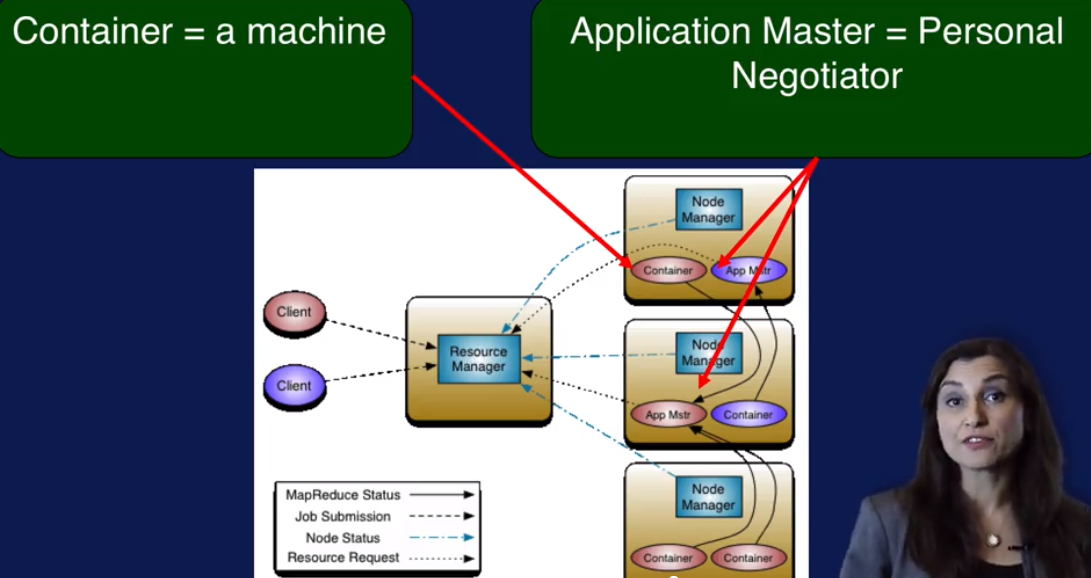
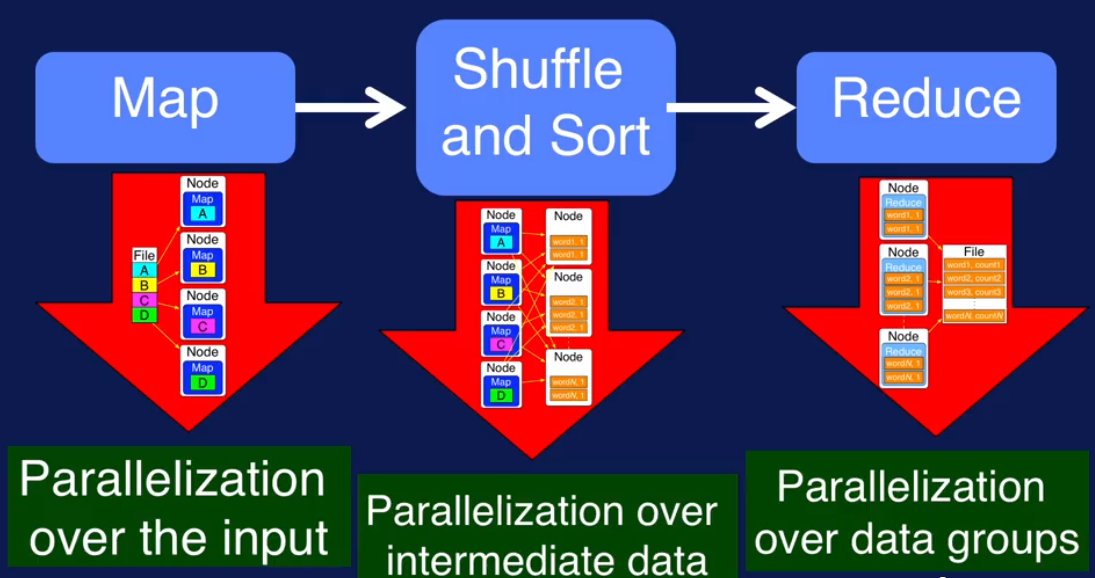
MapReduce:
计算分三步:Map -> Shuffle and Sort -> Reduce
下面图片用了WordCount 例子来显示这三个步骤



全局图
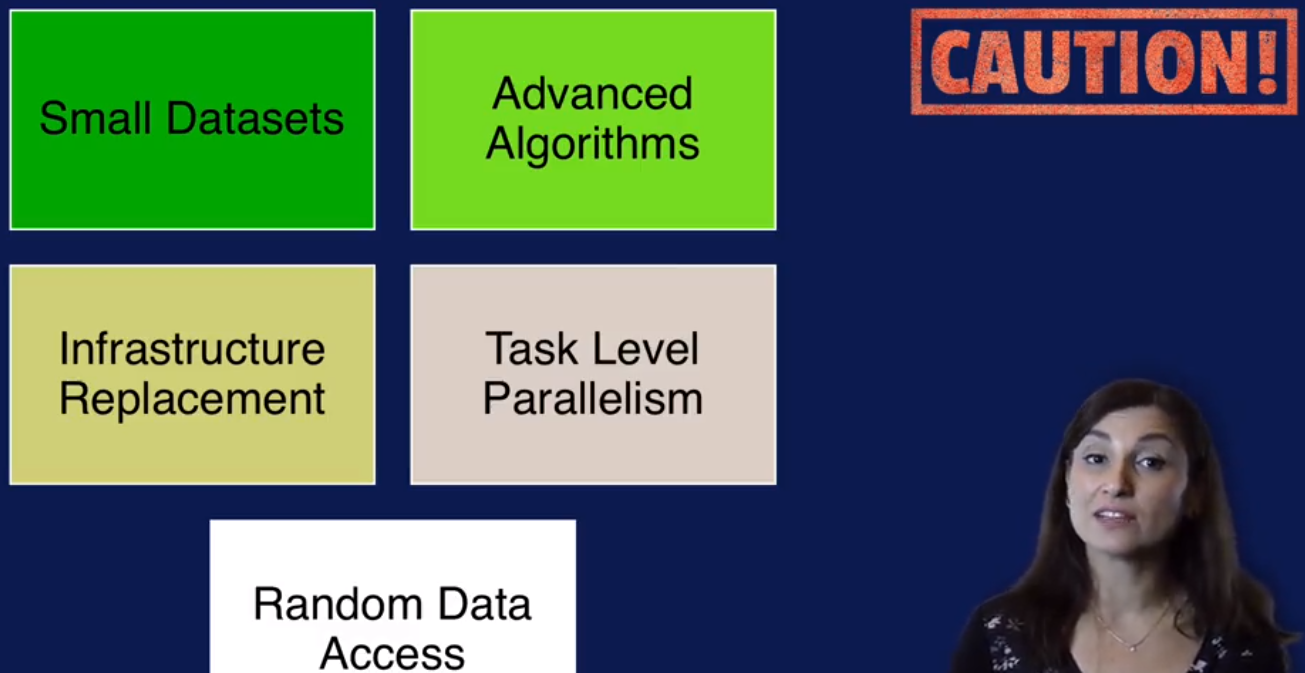
哪些情况不适合使用MapReduce: 因为每次都需要读取Input数据,所有Input数据不能随时变化,还有task 不能有先后依赖,还有MR 算完了才出结果也就不适合交互型的task.

什么情况下Hadoop使用或者不适用?
适用的场景包括了数据量比较大,数据格式多样等
不适用的场景:小数据量;一些数据之间有依赖的高级算法也不适用
云计算:
把基础架构交给云服务商,团队只需要关注应用.
IaaS: 比如 Amazon EC2, 阿里云
PaaS: Microsoft Azure, Google App Engine
SaaS: Dropbox
Value from Hadoop:
Ref:
About YARN: https://www.ibm.com/developerworks/cn/data/library/bd-yarn-intro/

