OO第一单元表达式求导作业总结
OO第一单元表达式求导作业总结
1、三次作业的实现方法、度量分析和bug分析
1.1第一次作业
第一次作业比较简单,只涉及到常数因子和幂函数因子,并且不用考虑括号的嵌套问题。
1.1.1实现方法
-
在MainClass类里实例化一个Expression对象Expression,把输入的字符串传入Expression,通过正则表达式匹配每个项,对于每个项,实例化一个Term对象Term,把匹配到的项传入Term,然后再通过正则表达式匹配每个因子,对于每个因子,实例化一个Factor对象Factor,把匹配到的因子传入Factor,再根据不同的因子识别对应的属性。表达式解析完成。
-
求导是通过递归的方法。Expression里面存储了一个Arraylist
,Term里面则存储了一个Arraylist ,为Expression、Term,以及各个Factor类写出相应的求导方法并且重写toString方法,递归实现求导过程。
1.1.2度量分析
-
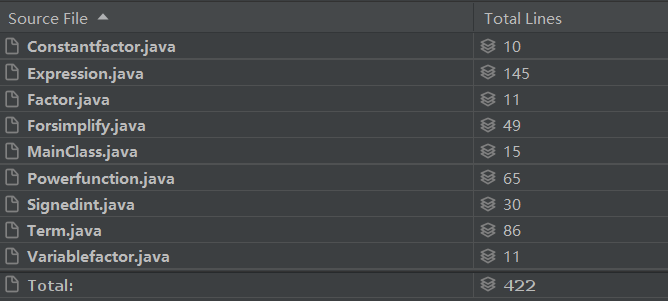
度量类的属性个数、方法个数、每个方法规模、每个方法的控制分支数目、类总代码规模。
-
类的属性个数
除Expression类有3个属性,其他类的属性个数均在0-2个。
-
类的方法个数、每个方法规模、每个方法的控制分支数目
-

- 总代码规模为422行,Expression类偏长。
-
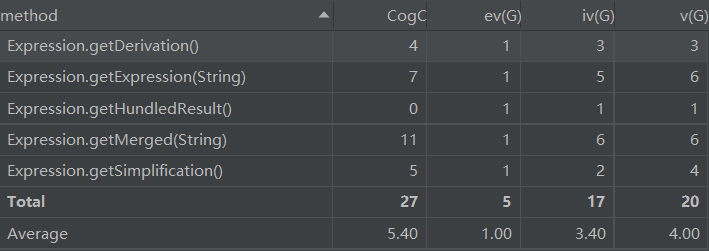
计算经典的OO度量,分析类的内聚和相互间的耦合情况。
- 首先上图看类的复杂度,可以看出Expression类承担的工作比较复杂,需要完成的任务较多,显得很臃肿。其他的类相对来说比较符合高内聚低耦合的特点。

- 然后上Expression类的方法复杂度分析图,可以看到主要的复杂度是在于解析表达式的方法和合并同类项的方法。
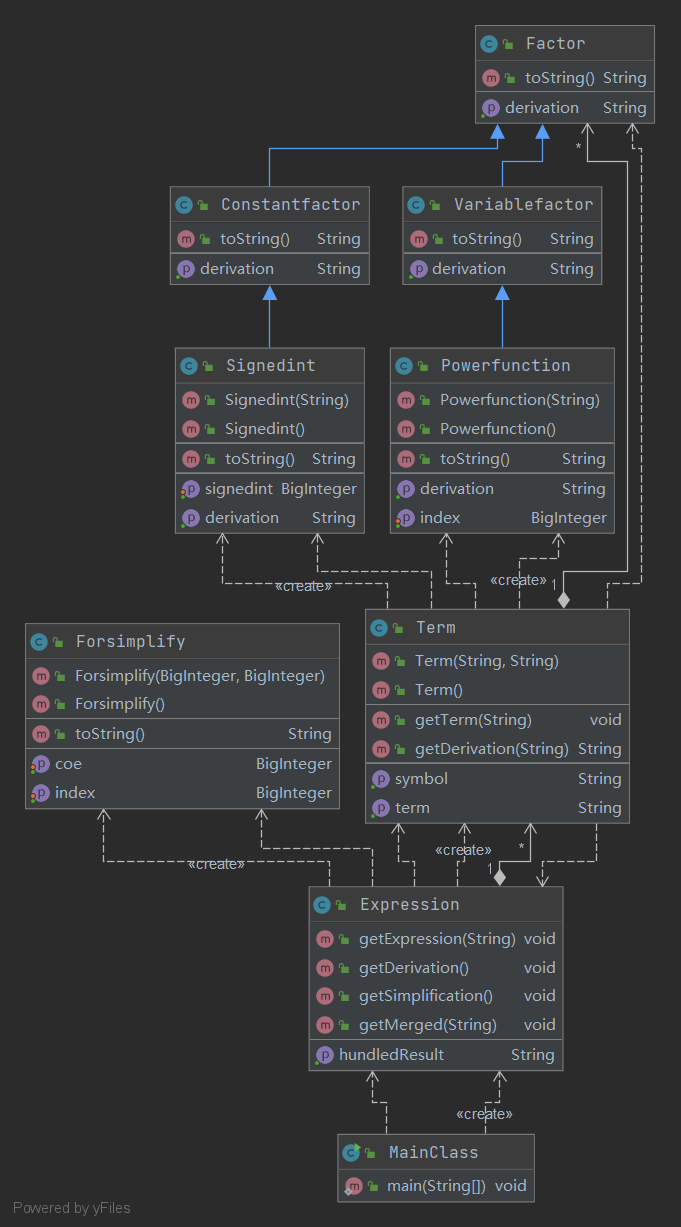
- 根据类图分析优点和缺点
-
各个类的设计考虑
- MainClass类:主类,程序的主要流程。
- Expression类:表达式类,负责解析表达式(把表达式拆成各个项存入Arraylist
),表达式的求导,表达式的合并和化简。 - Term类:项类,负责解析项(把项拆成各个因子存入Arraylist
),项的求导,项的输出。 - Factor类:因子类,其实应该用接口实现,但是当时不会使用接口。。。
- Variablefactor类:变量因子类,没有存在的必要,因子直接继承Factor类即可。
- Constantfactor类:常量因子类,没有存在的必要,因子直接继承Factor类即可。
- Powerfunction类:幂函数类,负责解析传入的幂函数(得到指数),幂函数的求导,幂函数的输出。
- Signedint类:带符号整数类,负责解析传入的整数,整数的求导,整数的输出。
- Forsimplify类:一个纯粹为了方便化简写出来的类。从类图就可以看出有些多余。。。
-
设计优点:
- 思路清晰,一层一层对表达式进行解析
- 因子的继承关系较好的考虑了以后的拓展问题
-
设计缺点:
- Forsimplify类其实并没有设计的必要,很多余,并且不符合高内聚低耦合的特点。
- Expression类的功能比较繁杂,复杂度较高,并且控制分支数目多。
- Term类的符号属性没有必要,而且为后面的作业增加了麻烦。
- 表达式的识别完全依靠正则表达式,导致正则表达式很多很复杂。
- 在识别前没有对表达式进行初步的化简,正则表达式特别长,为互测中的爆栈埋下隐患。
- 求导是通过递归进行求导,debug难度较大。
1.1.3bug分析
- 这次的作业比较简单,强测没有测出bug,但是互测被一个略“阴间”的数据hack了,500个x相乘,导致出现了StackOverflow的问题。
- 出现问题的原因就是在前面所说的,没有对表达式做初步的处理,导致正则表达式太过于长,在Expression类中解析各个项时出现了爆栈现象。
- 修复bug的过程比较痛苦,查了很久的资料都没有什么很好的方法,最后还是对表达式先做了初步处理,然后简化正则表达式,成功解决了这个问题。
1.2第二次作业
第二次作业加入了三角函数(只可能出现sin(x)和cos(x)的形式),表达式因子,并且由此产生了嵌套。
1.2.1实现方法
- 先对表达式进行预处理:
- 去除空白符
- 把连续多个加减操作符替换为一个
- 把**替换为 ^
- 把sin(x)、cos(x)替换为sin
,cos - 把表达式因子的最外层括号替换为中括号
- 在MainClass类里实例化一个Expression对象Expression,把输入的字符串传入Expression,通过正则表达式匹配每个项,对于每个项,实例化一个Term对象Term,把匹配到的项传入Term,然后再通过正则表达式匹配每个因子,对于每个因子,实例化一个Factor对象Factor,把匹配到的因子传入Factor,再根据不同的因子识别对应的属性。表达式解析完成。
- 求导是通过递归的方法。Expression里面存储了一个Arraylist
,Term里面则存储了一个Arraylist ,为Expression、Term,以及各个Factor类写出相应的求导方法并且重写toString方法,递归实现求导过程。
1.2.2度量分析
-
度量类的属性个数、方法个数、每个方法规模、每个方法的控制分支数目、类总代码规模。
-
类的属性个数
所有类的属性个数均在0-2个。
-
-
类的方法个数、每个方法规模、每个方法的控制分支数目
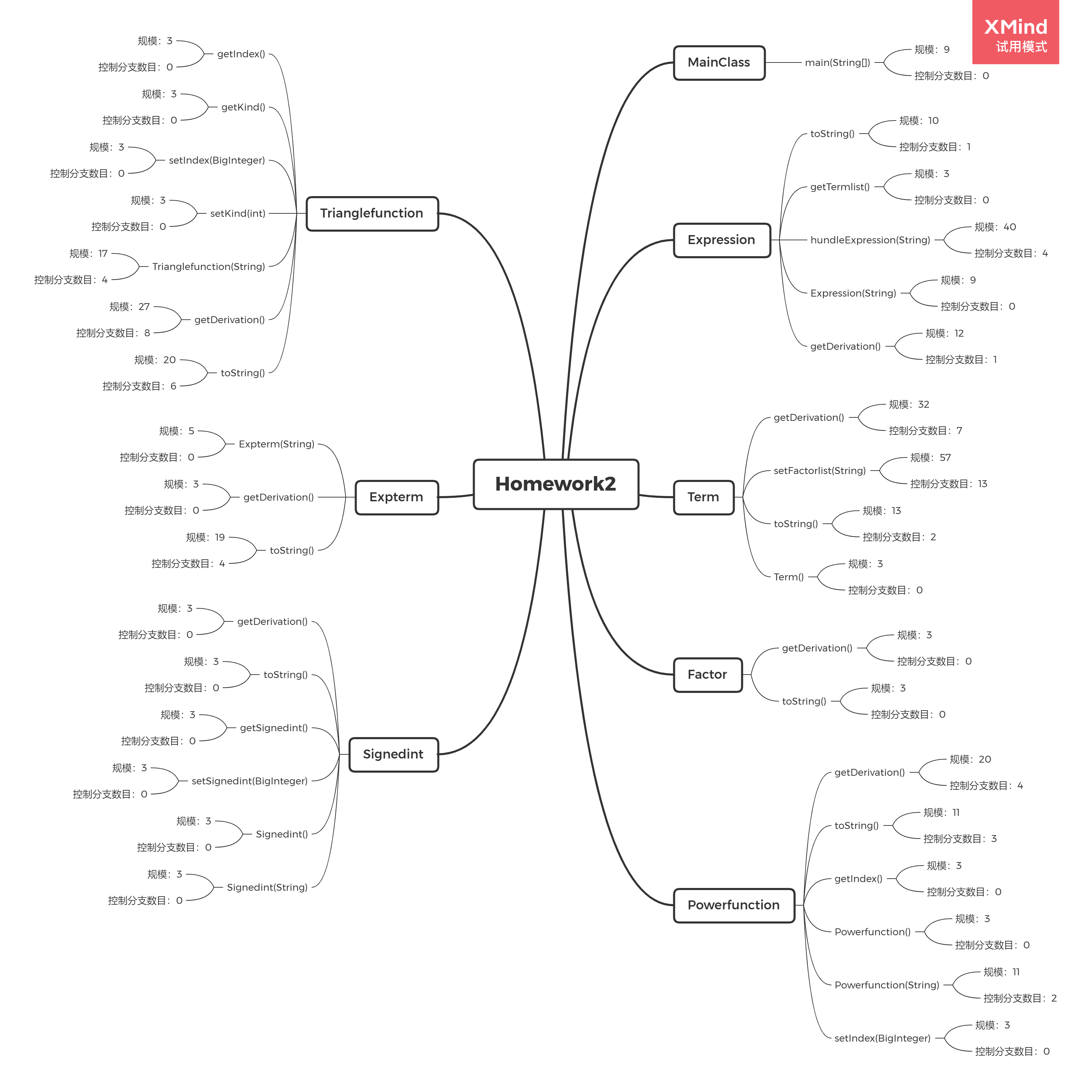
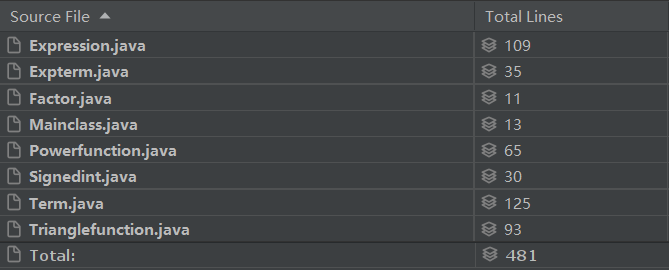
- 总代码规模为481行,Term类和Expression类偏长。
-
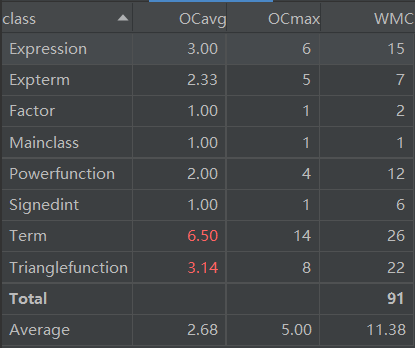
计算经典的OO度量,分析类的内聚和相互间的耦合情况。
- 首先上图看类的复杂度情况,可以看出这次Expression类的复杂度已经降低到正常水平,复杂度较高的是Term类和Triangfunction类,特别是Term类,是Expression的两倍还要多。
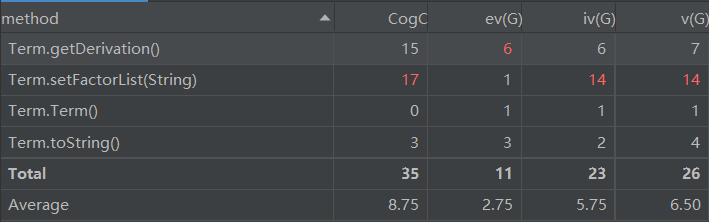
- 上Term类的方法复杂度图,可见求导方法的基本复杂度较高,说明求导方法的非结构化程度较高,写的很乱很臃肿,自己去看都有点晕,需要结合注释。而对各个项的解析方法除了基本复杂度,其他都很高,这个方法规模是57行,并且负责的工作很多,耦合度较高,并且增加了维护的难度和debug的难度。
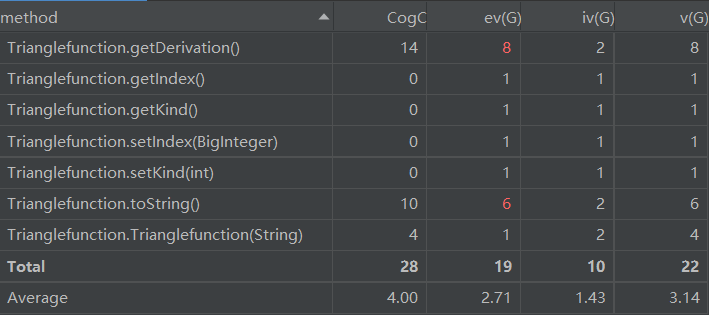
- 上Triangfunction类的方法复杂度图,求导方法和toString方法的基本复杂度较高,这是因为为了输出的简洁,在这两个方法中存在很多的if-else结构和if-else的嵌套,导致非结构化程度较高。
- 根据类图分析优点和缺点
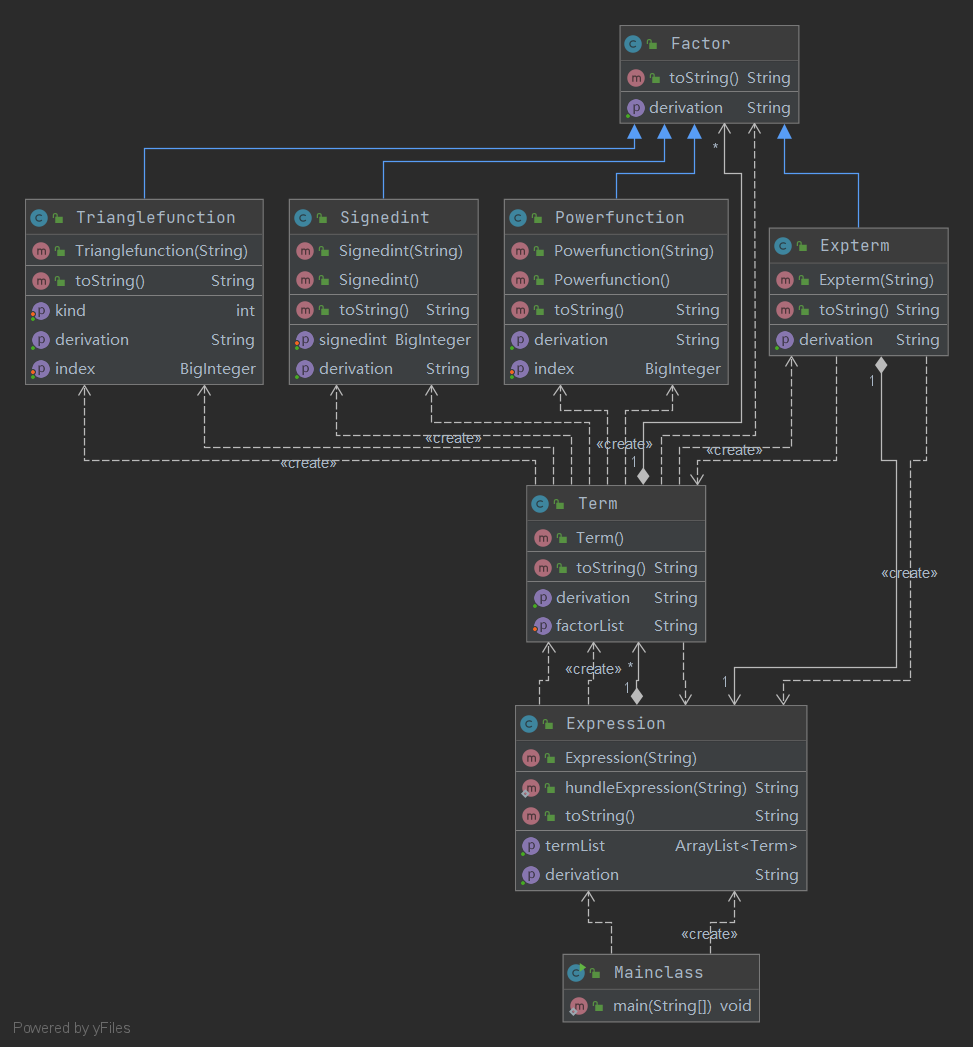
-
各个类的设计考虑:
- MainClass类、Expression类、Term类、Factor类、Powerfunction类、Signedint类、Triangfunction类设计考虑与第一次相同,此处不再赘述。
- Expterm类:表达式因子类,负责解析传入的表达式因子,表达式因子的求导,表达式因子的输出。这里着重说明一下表达式因子,Expterm类有一个属性是Expression,在实例化Expterm的同时也会实例化一个Expression,把传入的表达式因子去掉最外层的括号,作为新的表达式进行解析,从而递归实现表达式因子的解析。求导方法和输出方法直接调用Expression的求导方法和输出方法即可。
-
设计优点:
-
先对表达式进行预处理,降低了正则表达式的复杂度,较简单的实现了表达式因子的解析。
-
思路清晰,一层一层对表达式进行解析
-
-
设计缺点:
- 表达式的识别仍然完全依靠正则表达式,导致正则表达式很多很复杂。
- 对工厂模式不熟悉,导致某些类(比如Term类)中的方法耦合度较高。
- 表达式因子的识别和表达式的求导都是通过递归实现,debug难度较大,难以确定bug的具体位置。
- 由于设计的问题和自身水平问题,完全没有进行优化。
1.2.3bug分析
- 强测没有bug,互测也没有bug
1.3第三次作业
第三次作业加入了格式检查,同时三角函数的括号里可以是可能出现的任何因子
1.3.1实现方法
-
先对表达式进行部分格式检查:
- 检查异常字符(不应该出现的字符比如a)和空字符串
- 检查括号是否匹配(左右括号数是否相等)
- 检查空格和操作符
- 数字中存在空格
- 指数的符号与数字之间存在空格
- 指数或者因子有两个以上的符号
- 指数的两个*之间有空格
- 项的第一个常数因子的符号与数字之间存在空格
- 项的第一个因子不是常数因子但有三个以上的符号
- 项有四个以上的符号
- 常数因子的符号与数字之间有空格
- sin、cos之间有空格
- 检查指数
-
再对表达式进行预处理:
- 去除空白符
- 把连续多个加减操作符替换为一个
- 把**替换为 ^
- 把不在表达式因子中的三角函数的括号换成<>
- 把表达式因子最外层的括号换成中括号
-
在MainClass类里实例化一个Expression对象Expression,把输入的字符串传入Expression,通过正则表达式检查整体是否符合格式,符合则匹配每个项,对于每个项,实例化一个Term对象Term,把匹配到的项传入Term,然后再通过正则表达式检查项是否符合格式,符合则匹配每个因子,对于每个因子,实例化一个Factor对象Factor,把匹配到的因子传入Factor,再根据不同的因子识别对应的属性。表达式解析完成。
-
求导是通过递归的方法。Expression里面存储了一个Arraylist
,Term里面则存储了一个Arraylist ,为Expression、Term,以及各个Factor类写出相应的求导方法并且重写toString方法,递归实现求导过程。
1.3.2度量分析
-
度量类的属性个数、方法个数、每个方法规模、每个方法的控制分支数目、类总代码规模。
-
类的属性个数
除Trianglefunction类有3个属性,其他类的属性个数均在0-2个。
-
类的方法个数、每个方法规模、每个方法的控制分支数目
-
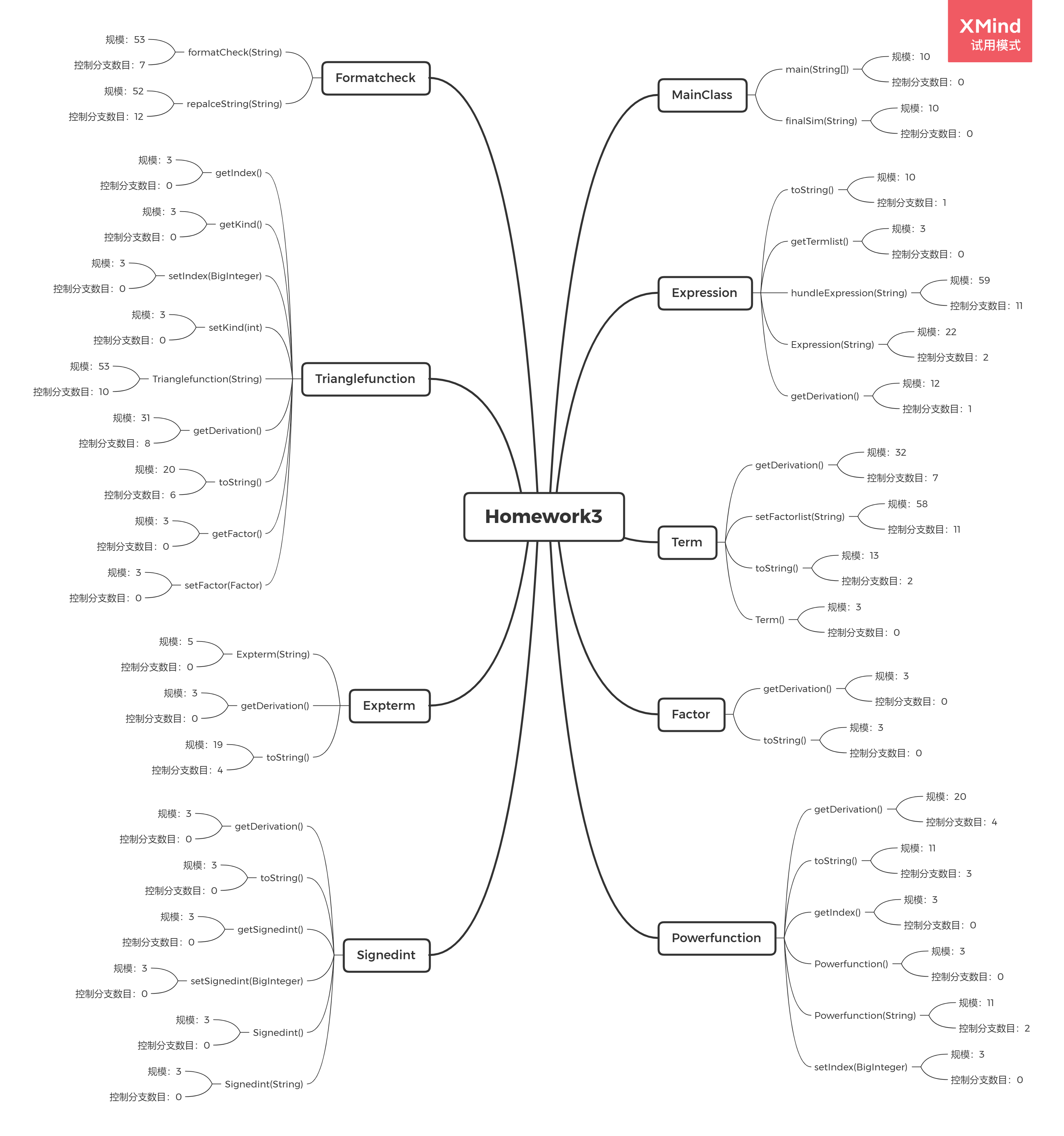
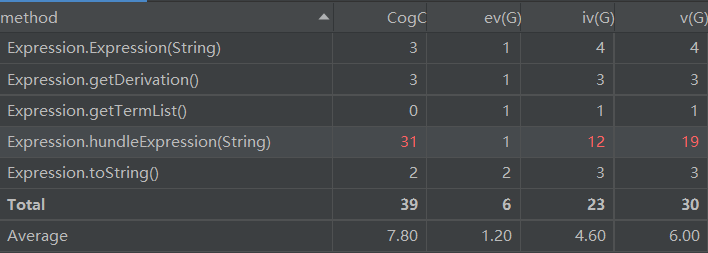
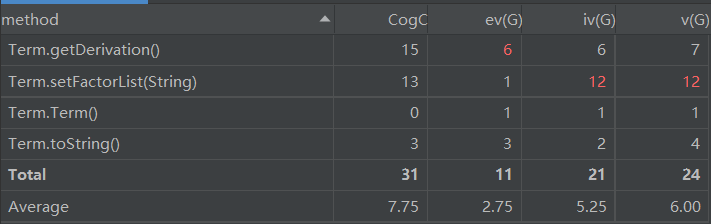
- 总代码规模为722行,Formatcheck类、Expression类、Term类和Trianglefunction类偏长。
-
计算经典的OO度量,分析类的内聚和相互间的耦合情况。
- 首先上图看类的复杂度情况,这次的Trianglefunction类的复杂度已经正常,但是Expression类、Term类和Formatcheck类的复杂度都严重超标。
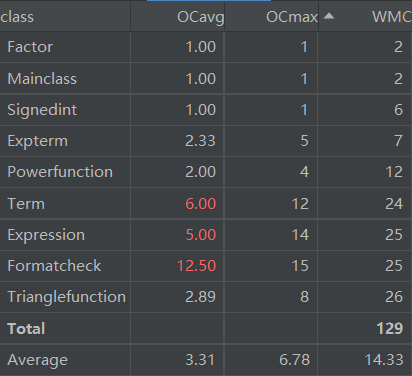
- 上Formatcheck类的方法复杂度图,可以看到对表达式预处理的方法除基本复杂度以外都严重偏高。这个方法有56行,其实应该把对字符串的预处理拆成多个方法而不是全部写进一个方法里,全部写进一个方法导致这个方法的耦合度过高,圈复杂度也过高。
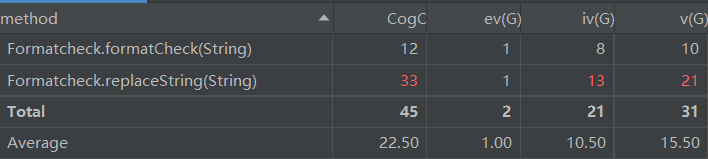
- 上Expression类的方法复杂度图,主要的问题同样是表达式预处理的问题,这个方法和Formatcheck.replaceString(String)方法基本相同,导致两者出现的问题也完全相同,耦合度过高,圈复杂度过高。
- 上Term类的方法复杂度图,出现的问题和第二次相同,这是因为在做第三次作业的过程中对于这两个方法几乎没有进行修改,此处不再赘叙。
- 根据类图分析优点和缺点
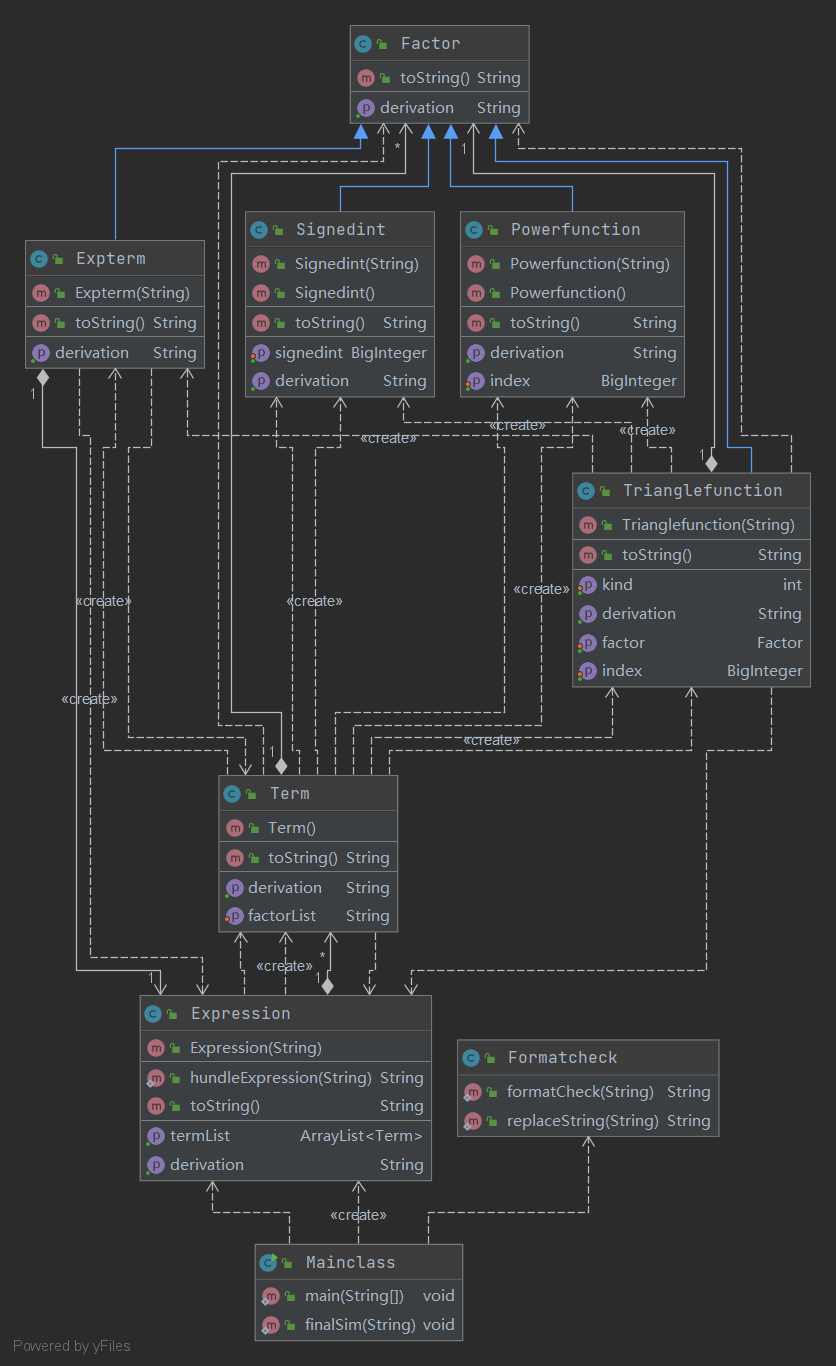
-
各个类的设计考虑:
- MainClass类、Expression类、Term类、Factor类、Powerfunction类、Signedint类、Triangfunction类、Expterm类设计考虑与第二次相同,此处不再赘述。
- Formatcheck类:有formatCheck和replaceString两个方法,用于应对新加入的格式检查需求。
-
设计优点:
- 整体基本符合高内聚、低耦合的特点
-
设计缺点:由于设计构架没有进行更改,只是增加了一个类用于格式检查,因此缺点与第二次相同。
- 表达式的识别仍然完全依靠正则表达式,导致正则表达式很多很复杂。
- 对工厂模式不熟悉,导致某些类(比如Term类)中的方法耦合度较高。
- 表达式因子的识别和表达式的求导都是通过递归实现,debug难度较大,难以确定bug的具体位置。
- 由于设计的问题和自身水平问题,完全没有进行优化。
1.3.3bug分析
- 强测和互测都没有发现bug
2.互测找bug策略
2.1第一次作业
- 第一次没有写自动评测,因此只能手动构造测试数据
- 构造的数据主要针对多个连续符号,前导零,正负指数,结果为0等几个问题进行构造
- 还真的找到了bug,明明是Aroom但是出现了结果为0时不输出的问题(建议加强数据
- 第一次互测试着去读代码,读了两三份实在读不下去了,几乎每个人都有自己的实现方法。最后还是直接构造数据找到的bug
2.2第二次作业
- 由于今年第二次就加入了嵌套规则,靠自己肉眼比对求导结果实在太难了,加上第一次研讨课有大佬分享了自动评测机的构造思路,我就自己动手写了一个
- 当然并没有指望单纯依靠自动评测找bug,除了自动评测,还手动构造一些数据,在第一次构造数据的基础上,又构造了一些多层括号嵌套的数据,放进评测机去评测
- 但是这次Room内的大家水平都很高,没有能够找到bug
- 由于这次有自动评测了,索性完全没有读代码
2.3第三次作业
- 第三次互测的要求让我有些无法理解,为什么不能提交错误格式的数据,明明这是第三次作业的重点内容
- 对于格式正确的表达式,自动评测并没有找到bug,自己构造数据也并不能找到
- 构造了一些格式错误的表达式,找到了bug,和第一次作业很类似,都是很简单的错误,也都是Aroom,这次找到的bug是x*+-1直接输出了-1,可惜明明找到了bug却无法提交
- 建议加强数据,建议互测能够提交格式不正确的数据
- 这次同样没有读代码
2.4结合三次互测经历给出的建议
- 希望公测的数据能够覆盖到更多的情况
- 希望有格式检查的作业能够提交格式错误的数据
- 希望减少一个Room内的人数。一个房间7-8人,进行到第二次或者第三次,代码的复杂度是很高的,想要依靠读别人的代码来找bug实在太难了,有这个功夫自动评测机也搭好了
3.重构经历总结
由于第一次作业考虑的比较全面,使用递归求导,因此从始至终架构都没有大改,没有进行重构。
4.心得体会
第一单元就已经感受到了OO的困难QAQ。
第一次作业应该是最困难的,尽管假期做了Pre,但是那时候并没有深入学习,只是为了完成作业,导致几乎就是零基础开始做作业。面对一种全新的语言,一种全新的思想,还有一个这么长的作业指导书,是很迷茫的,更不用说还要考虑后续作业的迭代开发。不过第一次痛苦过后,第二次第三次作业相对来说就好一些,整体的思路和逻辑大抵相同,只是根据新增加的需求添加一些新的类/方法和改动一些已有的方法,核心的方法基本不需要大改。尽管过程很痛苦,但是写出来的那一刻真的成就满满。
一些不足:
- 没有采用工厂模式,导致某些方法的耦合度很高。
- 完全采用正则表达式匹配表达式,尽管面对三次作业没有太大的问题,但是面对更长的表达式很可能爆栈。
- 某些方法过于长(56、57、58行),应该把这些方法再细分。
- 不喜欢写注释,加上自身代码风格并不算好,导致有时候debug都要好好读一读某些代码到底是干什么的。
- 虽然三次作业强测都很好的通过了,但是感觉自己写的代码并不够OO,还是有着面向过程的影子。
- 第二次第三次作业完全放弃了优化。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号