python -- 内存与垃圾回收源码分析
以前刚学python的时候,经常需要对数据进行循环操作,但是又需要保留原始数据,就有了下面的代码,此代码只是描述,不可当真。
data_list = [1,2,3,4,5]
temp_list = data_list
for data in data_list:
if data == 2 or data == 6:
temp_list.append(6)
这个代码会一直无限循环下去,明明是俩个不同的变量,只有data_list和temp_list是一样的,之后使用id查看变量的地址。
data_list = [1,2,3,4,5]
temp_list = data_list
temp_list.append(6)
print(data_list)
print(id(data_list))
print(id(temp_list))
之后输出的结果就是
[1, 2, 3, 4, 5, 6]
2296507176648
2296507176648
之后我想直接先删除吧,然后再重新创建一个
data_list = [1,2,3,4,5]
temp_list = data_list
temp_list.append(6)
print(data_list)
print(id(data_list))
print(id(temp_list))
del data_list
del temp_list
second_list = [1,2]
print(id(second_list))
但是结果地址结果竟然都是一样的
[1, 2, 3, 4, 5, 6]
2296507176648
2296507176648
2296507176648
下面我们就从源代码的角度来分析这种现象。
python内存管理机制
为了能够了解内存管理,我们最好是从源码来看并且分析,因为大学时期学过C语言,因此勉强能看懂,此次我们看的是python3.7.6的源码,不过我感觉每版的源码应该没有太大的变化,毕竟基础原理和语言特性是不会改变的。打开include中的listObject.h,
typedef struct {
// object里面的内容
PyObject_VAR_HEAD
/* Vector of pointers to list elements. list[0] is ob_item[0], etc. */
// 头元素指针
PyObject **ob_item;
/* ob_item contains space for 'allocated' elements. The number
* currently in use is ob_size.
* Invariants:
* 0 <= ob_size <= allocated
* len(list) == ob_size
* ob_item == NULL implies ob_size == allocated == 0
* list.sort() temporarily sets allocated to -1 to detect mutations.
*
* Items must normally not be NULL, except during construction when
* the list is not yet visible outside the function that builds it.
*/
// 当前可容纳的元素大小
Py_ssize_t allocated;
} PyListObject;
头元素指针ob_item就是首地址,这个很好理解,其他语言中也有这种类似的,就是数组名就是首地址,下面allocated就是list中可容纳的元素大小,其实就是list申请了多少内存,从注释中可以看出ob_size是当前元素个数大小,这里的意思就是列表需要频繁的插入和删除,那么频繁的申请和释放内存是不明智的,那么就先申请一大块内存,这个一大块就是allocated,已经使用的大小就是ob_size,那最上面那个PyObject_VAR_HEAD是什么呢?我们都知道所有的对象都会继承object这个对象,我们打开include中的object.h,在这个文件的开头定义中有这么一行代码,
/* PyObject_HEAD defines the initial segment of every PyObject. */
#define PyObject_HEAD PyObject ob_base;
#define PyObject_HEAD_INIT(type) \
{ _PyObject_EXTRA_INIT \
1, type },
#define PyVarObject_HEAD_INIT(type, size) \
{ PyObject_HEAD_INIT(type) size },
/* PyObject_VAR_HEAD defines the initial segment of all variable-size
* container objects. These end with a declaration of an array with 1
* element, but enough space is malloc'ed so that the array actually
* has room for ob_size elements. Note that ob_size is an element count,
* not necessarily a byte count.
*/
#define PyObject_VAR_HEAD PyVarObject ob_base;
#define Py_INVALID_SIZE (Py_ssize_t)-1
我们发现PyObject_VAR_HEAD其实就是PyVarObject这个对象,并且也可以发现PyObject_HEAD 就是PyObject,下面就是这俩个结构体的定义
// 只有float是用的它
typedef struct _object {
// 双向链表
_PyObject_HEAD_EXTRA
// 引用计数器
Py_ssize_t ob_refcnt;
// 对象类型
struct _typeobject *ob_type;
} PyObject;
// list,dict,set,tuple,int等
typedef struct {
// 实例
PyObject ob_base;
// 容器内的元素个数,比如列表,字典这种
Py_ssize_t ob_size; /* Number of items in variable part */
} PyVarObject;
从上面的注释就可以看出它们之间的关系,一个最基本的对象最起码有双向链表(用于管理python中创建的对象)、引用计数器和对象类型,双向链表和引用计数器主要是为了管理对象和垃圾回收机制的,像list这种PyVarObject会有ob_size,也就是元素个数,但是如果查看longObject这种数据类型(python3中没有long类型,只有int,而int是用C中的long实现的)我们发现也是PyVarObject,但是它并不像列表需要放很多元素啊。这个主要还是与它内部实现相关,我们都知道python的整数是可以无限大小的,这里的无限大小就是很多个digit堆叠起来的,自然也是需要计数的。
struct _longobject {
PyObject_VAR_HEAD
digit ob_digit[1];
};
再看PyObject中,它里面还存放了数据类型,之后我们需要看看初始化是什么样的,list分析的话比较难,涉及到垃圾回收机制,我们先看简单的,之后分析完垃圾回收机制再来看list的源代码。
floatObject的操作
我们先看一个简单的floatObject,因为它是最简单的PyObject,其他的都是PyVarObject。从Objects找出floatObject.c,
PyObject *
PyFloat_FromDouble(double fval)
{
PyFloatObject *op = free_list;
if (op != NULL) {
// 先从单项链表中拿出来一个。这个单项链表就是存储那些引用计数为0的开辟好的空间,这也是一种缓存机制
// int和字符串没有这种缓存机制
free_list = (PyFloatObject *) Py_TYPE(op);
// free_list里面最多有100个
numfree--;
} else {
// 开辟内存,深究下面有点复杂
op = (PyFloatObject*) PyObject_MALLOC(sizeof(PyFloatObject));
if (!op)
return PyErr_NoMemory();
}
/* Inline PyObject_New */
// 在开辟好的内存中进行初始化
/* - PyObject_Init(op, typeobj) and PyObject_InitVar(op, typeobj, n) don't
allocate memory. Instead of a 'type' parameter, they take a pointer to a
new object (allocated by an arbitrary allocator), and initialize its object
header fields.*/
(void)PyObject_INIT(op, &PyFloat_Type);
// 将值赋值到开辟的内存中
op->ob_fval = fval;
// 返回创建对象的内存地址的指针
return (PyObject *) op;
}
从上面的注释可以看出,如果是刚开始赋值的话,会先开辟内存,然后在开辟好的内存中进行初始化,我们从objimpl.h中找到这个初始化的方法,其中一个是对对象类型进行赋值,之后的操作都是在_Py_NewReference中的。
#define PyObject_INIT(op, typeobj) \
( Py_TYPE(op) = (typeobj), _Py_NewReference((PyObject *)(op)), (op) )
#define PyObject_INIT_VAR(op, typeobj, size) \
( Py_SIZE(op) = (size), PyObject_INIT((op), (typeobj)) )
打开实现文件object.c,找到_Py_NewReference方法
void
_Py_NewReference(PyObject *op)
{
_Py_INC_REFTOTAL;
// 引用计数器为1
op->ob_refcnt = 1;
// 添加到双向链表中
_Py_AddToAllObjects(op, 1);
_Py_INC_TPALLOCS(op);
}
这个方法做的就是引用计数器为1,之后就是_Py_AddToAllObjects方法,找出这个方法
/* Head of circular doubly-linked list of all objects. These are linked
* together via the _ob_prev and _ob_next members of a PyObject, which
* exist only in a Py_TRACE_REFS build.
*/
static PyObject refchain = {&refchain, &refchain};
/* Insert op at the front of the list of all objects. If force is true,
* op is added even if _ob_prev and _ob_next are non-NULL already. If
* force is false amd _ob_prev or _ob_next are non-NULL, do nothing.
* force should be true if and only if op points to freshly allocated,
* uninitialized memory, or you've unlinked op from the list and are
* relinking it into the front.
* Note that objects are normally added to the list via _Py_NewReference,
* which is called by PyObject_Init. Not all objects are initialized that
* way, though; exceptions include statically allocated type objects, and
* statically allocated singletons (like Py_True and Py_None).
*/
void
_Py_AddToAllObjects(PyObject *op, int force)
{
#ifdef Py_DEBUG
if (!force) {
/* If it's initialized memory, op must be in or out of
* the list unambiguously.
*/
assert((op->_ob_prev == NULL) == (op->_ob_next == NULL));
}
#endif
// 添加
if (force || op->_ob_prev == NULL) {
op->_ob_next = refchain._ob_next;
op->_ob_prev = &refchain;
refchain._ob_next->_ob_prev = op;
refchain._ob_next = op;
}
}
可以看出refchain是个双向链表中,整个过程就是添加到对象双向链表中。我们来整理一下整个floatObject的初始化过程,如果a = 8.9,那么它会先开辟内存,之后进行初始化,就是类型赋值,引用加1,加入双向链表中,之后将值赋值到开辟的内存中,之后返回到a中,a其实就是一个地址的引用而已,那么我们知道在python中变量本质就是对一块内存数据区域的引用,而不是内存中一块存储数据的区域。这里的变量名是没有类型的,类型是属于对象的。变量引用什么类型的对象,对象就是什么类型的,那么list也是如此,如果b = a,会执行的就是下面的代码
#define Py_INCREF(op) ( \
_Py_INC_REFTOTAL _Py_REF_DEBUG_COMMA \
((PyObject *)(op))->ob_refcnt++)
上面其实就是将引用计数+1而已,那么temp_list = data_list,其实就是引用计数器再加1,其内存空间没有任何的改变,所以上面的temp_list也会变成data_list操作。之后我们将temp_list和data_list都删除,再创建一个列表的时候,它的内存地址还是一样,为什么会这样?我们先从对象的销毁来看,先是从object.h中找出Py_CLEAR
#define Py_CLEAR(op) \
do { \
PyObject *_py_tmp = (PyObject *)(op); \
if (_py_tmp != NULL) { \
(op) = NULL; \
Py_DECREF(_py_tmp); \
} \
} while (0)
执行Py_DECREF,从中找出Py_DECREF
// #define _Py_DEC_REFTOTAL _Py_RefTotal--
#define Py_DECREF(op) \
do { \
PyObject *_py_decref_tmp = (PyObject *)(op); \
if (_Py_DEC_REFTOTAL _Py_REF_DEBUG_COMMA \
--(_py_decref_tmp)->ob_refcnt != 0) \
_Py_CHECK_REFCNT(_py_decref_tmp) \
else \
// 进行垃圾回收
_Py_Dealloc(_py_decref_tmp); \
} while (0)
这个函数的if条件就是先执行引用-1,之后再检查引用是否等于0,如果不等于0的话,那么使用_Py_CHECK_REFCNT来检查它的引用是否小于0,如果小于0了,那么需要处理这种错误。那么上面代码中第一个del,只是删除了引用。
#define _Py_CHECK_REFCNT(OP) \
{ if (((PyObject*)OP)->ob_refcnt < 0) \
_Py_NegativeRefcount(__FILE__, __LINE__, \
(PyObject *)(OP)); \
}
如果引用等于0的话,那么要对它进行垃圾回收,执行_Py_Dealloc
void
_Py_Dealloc(PyObject *op)
{
// 找到float类型的tp_dealloc进行内存销毁
destructor dealloc = Py_TYPE(op)->tp_dealloc;
// 从双向链表中移除
_Py_ForgetReference(op);
// 调用float类型的tp_dealloc进行内存销毁
(*dealloc)(op);
}
那么从floatobject.c中找出来
// #define PyFloat_MAXFREELIST 100
static void
float_dealloc(PyFloatObject *op)
{
if (PyFloat_CheckExact(op)) {
// 检查缓冲池个数是否大于最大
if (numfree >= PyFloat_MAXFREELIST) {
// 缓冲满了,直接将对象销毁
PyObject_FREE(op);
return;
}
// 缓冲池+1
numfree++;
// 并将要销毁的数据加入到free_list单向链表中
Py_TYPE(op) = (struct _typeobject *)free_list;
free_list = op;
}
else
Py_TYPE(op)->tp_free((PyObject *)op);
}
如果引用等于0,那么先检查缓冲数组free_list个数是否已经最大,如果还没有,那么缓冲池+1,之后加入到free_list中,大家可以翻到上面对象创建的代码PyFloat_FromDouble中,我们发现在开辟空间的时候,是有if条件的,满足的话,就从free_list中拿出来的,这个free_list就是一个缓冲数组。python删除对象所有的引用之后,并没有直接销毁掉,而是采用了一种缓冲机制,下次初始化相同类型的数,直接从缓冲中取,就不用重新申请内存啥的了。所有上面我们全部删除,之后再重新定义list,就会发现它们都是一样的内存地址,list、float、dict、tuple都是如此,其中tuple有点特殊,它的free_list有20个元素,第一个元素里面放的都是空元素的tuple,第二个放的都是有1个元素的tuple,以此下去,最后一个就是放19个元素的元组,并且每一个位置可以存放2000个元组,就是free_list中第2个位置可以存放2000个含有一个元素的元组,所以如果你之前创建的是俩个元素的元组,删除之后,只有再创建俩个元素的元组,这俩个元组的内存地址才会一样。
但是有的对象用的不是free_list,比如字符串和int,字符串会先将所有ASCII字符都创建出来然后一直放在内存中,之后还会采用字符串驻留技术,就是内存中如果有这个字符串,就不用创建,直接使用原来的地址。int是用的小数据池,它先将[-5,257)中所有的数先创建出来,它认为它们是频繁被使用的,一直保存在内存中,也就是它们的引用计数永远都是大于0的,我们也可以从代码中找到判断是否小数据池中的。
// 下面一个是5,一个是257,这个就是小整数池
#ifndef NSMALLPOSINTS
#define NSMALLPOSINTS 257
#endif
#ifndef NSMALLNEGINTS
#define NSMALLNEGINTS 5
#endif
static PyObject *
get_small_int(sdigit ival)
{
PyObject *v;
assert(-NSMALLNEGINTS <= ival && ival < NSMALLPOSINTS);
v = (PyObject *)&small_ints[ival + NSMALLNEGINTS];
Py_INCREF(v);
#ifdef COUNT_ALLOCS
if (ival >= 0)
quick_int_allocs++;
else
quick_neg_int_allocs++;
#endif
return v;
}
// 核实是否在小整数池中,如果是的,那么直接取数据[5,257)
#define CHECK_SMALL_INT(ival) \
do if (-NSMALLNEGINTS <= ival && ival < NSMALLPOSINTS) { \
return get_small_int((sdigit)ival); \
} while(0)
python的垃圾回收机制
引用计数器
从上面的分析中可以得知,每个对象在创建的时候都会有一个引用计数器,而这种变量内存方式也注定了python的回收机制是以引用计数为主的。
// 只有float是用的它
typedef struct _object {
// 双向链表
_PyObject_HEAD_EXTRA
// 引用计数器
Py_ssize_t ob_refcnt;
// 对象类型
struct _typeobject *ob_type;
} PyObject;
增加与删除实际上都有引用计数有关,就是将引用计数加1和引用计数减1。删除的时候还要判断是否引用计数为0,如果为0,那么开启垃圾回收。
// #define _Py_DEC_REFTOTAL _Py_RefTotal--
#define Py_DECREF(op) \
do { \
PyObject *_py_decref_tmp = (PyObject *)(op); \
if (_Py_DEC_REFTOTAL _Py_REF_DEBUG_COMMA \
--(_py_decref_tmp)->ob_refcnt != 0) \
_Py_CHECK_REFCNT(_py_decref_tmp) \
else \
// 进行垃圾回收
_Py_Dealloc(_py_decref_tmp); \
} while (0)
但是如果仅仅使用引用计数器作为判别标准的话,在循环引用问题上会出现BUG,因此还需要标记清除和分代回收机制作为辅助。
标记清除
循环引用的问题我们可以看一下程序
a = [1,2,3]
b = [2,3,4]
a.append(b)
b.append(a)
这种就会产生循环引用的问题。那么python的办法是再创建一个链表,专门存放那些可能会出现循环引用问题的数据类型,比如list、tuple、dict和set。之后在某种情况下触发,扫描链表中的每个元素,找到那些不可达对象即可,那么就可以将之引用计数为0。
分为俩个阶段:
- 标记阶段,GC会将所有的活动对象打上标记
- 将那些没有标记的对象(非活动对象)进行回收
问题就来到了,怎么判断哪些是活动对象,哪些是不活动对象???利用有向图,我们从上面知道所有对象之间通过指针连在一起,对象构成这个有向图的节点,引用关系构成这个有向图的边。从根节点出发,沿着有向边遍历对象,可达对象就标记为活动对象,不可达对象就是非活动对象。
缺点就是清除非活动对象的时候,必须扫描整个堆内存,哪怕只剩下小部分的活动对象也要扫描所有的对象
分代回收
这是一种空间换时间的操作方式,python根据内存对象的存活时间划分为不同的集合,每个集合就是一个代。python将内存分为3代,年轻代、中年代、老年代,分别对应着3个链表,它们的垃圾收集频率随着存活的时间增大而减小。
新创建的对象都会被分配在年轻代,年轻带的链表达到上限后,python的垃圾回收机制就会被触发,把那些可以回收的对象回收掉,而那些不会回收的对象就会被移到中年代去,以此类推,老年代对象就是存活时间最久的对象,有可能存活于整个系统的生命周期内。所以真实中一共存在四个链表。如图所示
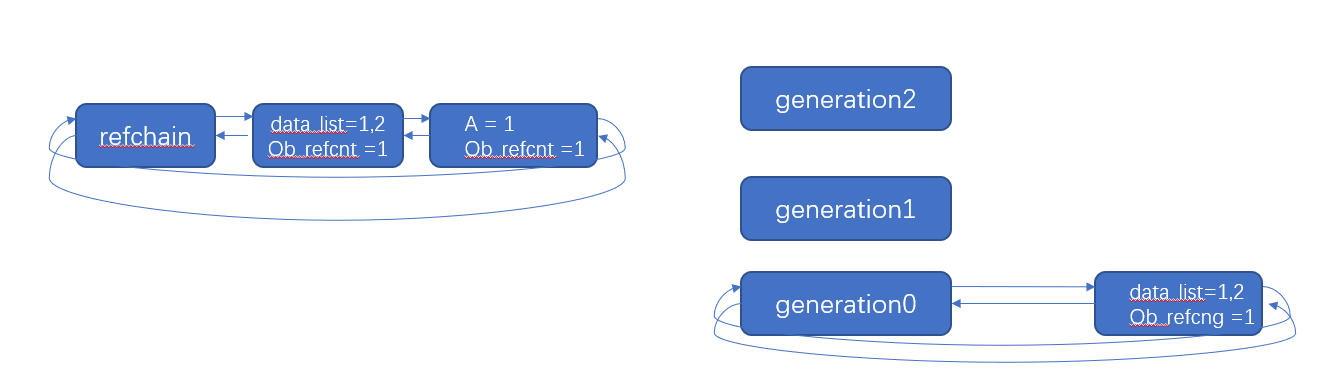
创建列表的时候,要检查0代数量+1,是否超出了阈值,如果超过了,就需要进行分代处理。从Modules/gcmodule.c中可以找到判断的代码
static PyObject *
_PyObject_GC_Alloc(int use_calloc, size_t basicsize)
{
PyObject *op;
PyGC_Head *g;
size_t size;
if (basicsize > PY_SSIZE_T_MAX - sizeof(PyGC_Head))
return PyErr_NoMemory();
size = sizeof(PyGC_Head) + basicsize;
if (use_calloc)
g = (PyGC_Head *)PyObject_Calloc(1, size);
else
g = (PyGC_Head *)PyObject_Malloc(size);
if (g == NULL)
return PyErr_NoMemory();
g->gc.gc_refs = 0;
_PyGCHead_SET_REFS(g, GC_UNTRACKED);
// 0代数量+1
_PyRuntime.gc.generations[0].count++; /* number of allocated GC objects */
// 0代超出自己的阈值,就会进行分代处理
if (_PyRuntime.gc.generations[0].count > _PyRuntime.gc.generations[0].threshold &&
_PyRuntime.gc.enabled &&
_PyRuntime.gc.generations[0].threshold &&
!_PyRuntime.gc.collecting &&
!PyErr_Occurred()) {
_PyRuntime.gc.collecting = 1;
// 回收
collect_generations();
_PyRuntime.gc.collecting = 0;
}
op = FROM_GC(g);
return op;
}
我们可以从中看出其中collect_generations()就是具体回收的代码,我们找到其中的代码发现了
static Py_ssize_t
collect_generations(void)
{
int i;
Py_ssize_t n = 0;
/* Find the oldest generation (highest numbered) where the count
* exceeds the threshold. Objects in the that generation and
* generations younger than it will be collected. */
// 倒序循环三代,这里就是2代如果达到阈值需要扫描了,那么之前的1代也需要扫描
for (i = NUM_GENERATIONS-1; i >= 0; i--) {
if (_PyRuntime.gc.generations[i].count > _PyRuntime.gc.generations[i].threshold) {
/* Avoid quadratic performance degradation in number
of tracked objects. See comments at the beginning
of this file, and issue #4074.
*/
if (i == NUM_GENERATIONS - 1
&& _PyRuntime.gc.long_lived_pending < _PyRuntime.gc.long_lived_total / 4)
continue;
// 扫描当前代之前所有代,
n = collect_with_callback(i);
break;
}
}
return n;
}
其中循环三代的时候,就是倒序循环的,这是因为如果高级代达到了阈值了,那么低代都需要一起扫描,其中扫描的代码是在collect_with_callback。
/* Perform garbage collection of a generation and invoke
* progress callbacks.
*/
static Py_ssize_t
collect_with_callback(int generation)
{
Py_ssize_t result, collected, uncollectable;
invoke_gc_callback("start", generation, 0, 0);
result = collect(generation, &collected, &uncollectable, 0);
invoke_gc_callback("stop", generation, collected, uncollectable);
return result;
}
其中具体的代码应该是在collect,找到collect。
/* This is the main function. Read this to understand how the
* collection process works. */
static Py_ssize_t
collect(int generation, Py_ssize_t *n_collected, Py_ssize_t *n_uncollectable,
int nofail)
{
int i;
Py_ssize_t m = 0; /* # objects collected */
Py_ssize_t n = 0; /* # unreachable objects that couldn't be collected */
PyGC_Head *young; /* the generation we are examining */
PyGC_Head *old; /* next older generation */
PyGC_Head unreachable; /* non-problematic unreachable trash */
PyGC_Head finalizers; /* objects with, & reachable from, __del__ */
PyGC_Head *gc;
_PyTime_t t1 = 0; /* initialize to prevent a compiler warning */
struct gc_generation_stats *stats = &_PyRuntime.gc.generation_stats[generation];
if (_PyRuntime.gc.debug & DEBUG_STATS) {
PySys_WriteStderr("gc: collecting generation %d...\n",
generation);
PySys_WriteStderr("gc: objects in each generation:");
for (i = 0; i < NUM_GENERATIONS; i++)
PySys_FormatStderr(" %zd",
gc_list_size(GEN_HEAD(i)));
PySys_WriteStderr("\ngc: objects in permanent generation: %zd",
gc_list_size(&_PyRuntime.gc.permanent_generation.head));
t1 = _PyTime_GetMonotonicClock();
PySys_WriteStderr("\n");
}
if (PyDTrace_GC_START_ENABLED())
PyDTrace_GC_START(generation);
/* update collection and allocation counters */
// 当前代扫描一次,那么高级代次数要+1
if (generation+1 < NUM_GENERATIONS)
_PyRuntime.gc.generations[generation+1].count += 1;
// 比当前代低的代,次数会设置为0,因为当前代扫描会带着年轻代一起扫描的,扫描后年轻代的对象会升到高级代中,年轻代就是0
for (i = 0; i <= generation; i++)
_PyRuntime.gc.generations[i].count = 0;
// 高的+1,低的为0
/* merge younger generations with one we are currently collecting */
// 将比自己低的所有代,都放在一个链表中
for (i = 0; i < generation; i++) {
gc_list_merge(GEN_HEAD(i), GEN_HEAD(generation));
}
/* handy references */
// 获取链表头
young = GEN_HEAD(generation);
// 获取比当前代高的代的链表头,比如当前代是1,那么old就是2代,young就是0代和1代
if (generation < NUM_GENERATIONS-1)
old = GEN_HEAD(generation+1);
else
old = young;
/* Using ob_refcnt and gc_refs, calculate which objects in the
* container set are reachable from outside the set (i.e., have a
* refcount greater than 0 when all the references within the
* set are taken into account).
*/
// 为了在循环处理代中数据的时候不更改数据,那么先拷贝一份所有数据的引用计数到gc_refs,之后对gc_refs进行操作
// 如果拷贝中的引用计数为0,那么再处理链表中的数据
update_refs(young);
// 这个函数就是处理循环引用,将循环引用的数据的引用计数变成0
subtract_refs(young);
/* Leave everything reachable from outside young in young, and move
* everything else (in young) to unreachable.
* NOTE: This used to move the reachable objects into a reachable
* set instead. But most things usually turn out to be reachable,
* so it's more efficient to move the unreachable things.
*/
// 将链表中所有的引用计数器为0的,移动到不可达链表中
// 循环处理young中的每个数据,然后看gc_refs是否为0,如果是0就放到不可达链表中
gc_list_init(&unreachable);
move_unreachable(young, &unreachable);
/* Move reachable objects to next generation. */
// 将可达数据放入到下一代中
if (young != old) {
// 如果是0,1代,那么升级到下一代
if (generation == NUM_GENERATIONS - 2) {
_PyRuntime.gc.long_lived_pending += gc_list_size(young);
}
// 把将young链表拼接到old链表中
gc_list_merge(young, old);
}
else {
/* We only untrack dicts in full collections, to avoid quadratic
dict build-up. See issue #14775. */
// 如果是2代,那么更新long_lived_pending和long_lived_total
untrack_dicts(young);
_PyRuntime.gc.long_lived_pending = 0;
_PyRuntime.gc.long_lived_total = gc_list_size(young);
}
/* All objects in unreachable are trash, but objects reachable from
* legacy finalizers (e.g. tp_del) can't safely be deleted.
*/
// 循环所有不可达元素,把具有__del__方法数据放到finalizers,
gc_list_init(&finalizers);
move_legacy_finalizers(&unreachable, &finalizers);
/* finalizers contains the unreachable objects with a legacy finalizer;
* unreachable objects reachable *from* those are also uncollectable,
* and we move those into the finalizers list too.
*/
move_legacy_finalizer_reachable(&finalizers);
/* Print debugging information. */
if (_PyRuntime.gc.debug & DEBUG_COLLECTABLE) {
for (gc = unreachable.gc.gc_next; gc != &unreachable; gc = gc->gc.gc_next) {
debug_cycle("collectable", FROM_GC(gc));
}
}
/* Clear weakrefs and invoke callbacks as necessary. */
m += handle_weakrefs(&unreachable, old);
/* Call tp_finalize on objects which have one. */
// 处理那些具有del方法的数据
finalize_garbage(&unreachable);
// 清除垃圾
if (check_garbage(&unreachable)) {
revive_garbage(&unreachable);
gc_list_merge(&unreachable, old);
}
else {
/* Call tp_clear on objects in the unreachable set. This will cause
* the reference cycles to be broken. It may also cause some objects
* in finalizers to be freed.
*/
m += gc_list_size(&unreachable);
delete_garbage(&unreachable, old);
}
/* Collect statistics on uncollectable objects found and print
* debugging information. */
for (gc = finalizers.gc.gc_next;
gc != &finalizers;
gc = gc->gc.gc_next) {
n++;
if (_PyRuntime.gc.debug & DEBUG_UNCOLLECTABLE)
debug_cycle("uncollectable", FROM_GC(gc));
}
if (_PyRuntime.gc.debug & DEBUG_STATS) {
_PyTime_t t2 = _PyTime_GetMonotonicClock();
if (m == 0 && n == 0)
PySys_WriteStderr("gc: done");
else
PySys_FormatStderr(
"gc: done, %zd unreachable, %zd uncollectable",
n+m, n);
PySys_WriteStderr(", %.4fs elapsed\n",
_PyTime_AsSecondsDouble(t2 - t1));
}
/* Append instances in the uncollectable set to a Python
* reachable list of garbage. The programmer has to deal with
* this if they insist on creating this type of structure.
*/
handle_legacy_finalizers(&finalizers, old);
/* Clear free list only during the collection of the highest
* generation */
if (generation == NUM_GENERATIONS-1) {
clear_freelists();
}
if (PyErr_Occurred()) {
if (nofail) {
PyErr_Clear();
}
else {
if (gc_str == NULL)
gc_str = PyUnicode_FromString("garbage collection");
PyErr_WriteUnraisable(gc_str);
Py_FatalError("unexpected exception during garbage collection");
}
}
/* Update stats */
if (n_collected)
*n_collected = m;
if (n_uncollectable)
*n_uncollectable = n;
stats->collections++;
stats->collected += m;
stats->uncollectable += n;
if (PyDTrace_GC_DONE_ENABLED())
PyDTrace_GC_DONE(n+m);
return n+m;
}
可以看出其中的代码非常的复杂,其实先是进行一些处理,就是当前代进行扫描的话,那么高的代的扫描次数+1,低代的次数设置为0,之后将低代和当前代放入到young链表中,高代放入到old中,然后扫描young链表,先拷贝出所有对象的引用计数到gc_refs,之后循环遍历链表找出循环引用对象,将循环引用对象设置为0,并将这些对象放入到不可达链表中,将那些可达对象放入到下一代中,之后都是删除循环引用对象,注意有del的对象要特殊处理。
listObject中的操作
下面我们来看list的初始化,找到listObject.c代码,
PyObject *
PyList_New(Py_ssize_t size)
{
// 列表对象
PyListObject *op;
#ifdef SHOW_ALLOC_COUNT
static int initialized = 0;
if (!initialized) {
Py_AtExit(show_alloc);
initialized = 1;
}
#endif
// 如果列表大小0,直接返回
if (size < 0) {
PyErr_BadInternalCall();
return NULL;
}
if (numfree) {
// 如果缓冲中有对象,直接拿一个
numfree--;
op = free_list[numfree];
_Py_NewReference((PyObject *)op);
#ifdef SHOW_ALLOC_COUNT
count_reuse++;
#endif
} else {
// 如果没有,开辟内存,他会检查0代链表是不是达到700了
op = PyObject_GC_New(PyListObject, &PyList_Type);
if (op == NULL)
return NULL;
#ifdef SHOW_ALLOC_COUNT
count_alloc++;
#endif
}
// 为对象维护元素列表申请空间
if (size <= 0)
op->ob_item = NULL;
else {
op->ob_item = (PyObject **) PyMem_Calloc(size, sizeof(PyObject *));
if (op->ob_item == NULL) {
Py_DECREF(op);
return PyErr_NoMemory();
}
}
Py_SIZE(op) = size;
op->allocated = size;
// 把对象加入到分代回收的0代链表中
_PyObject_GC_TRACK(op);
return (PyObject *) op;
}
从上面可以看出如果缓冲区有的话,是直接拿的,但是如果缓冲区没有,自己开辟内存空间的话,是调用了PyObject_GC_New,GC一般都是指垃圾回收机制,难道开辟空间与之有关,查看Modules/gcmodule.c文件,找到这个方法。
PyObject *
_PyObject_GC_New(PyTypeObject *tp)
{
// 创建对象
PyObject *op = _PyObject_GC_Malloc(_PyObject_SIZE(tp));
if (op != NULL)
// 初始化对象并且放入到refchain链表中
op = PyObject_INIT(op, tp);
return op;
}
可以看出_PyObject_GC_Malloc来创建的对象,那么找到它,发现它就是上面的那个垃圾回收机制的开始函数_PyObject_GC_Alloc。
PyObject *
_PyObject_GC_Malloc(size_t basicsize)
{
return _PyObject_GC_Alloc(0, basicsize);
}
那么list在创建对象的时候,先查看缓冲区,如果缓冲区没有的话,开辟内存空间,在开辟内存空间的时候,需要检查0代是否已满,满的话,需要进行分代处理,就是每一代都需要进行标记清除,然后开辟好空间之后,为对象维护元素列表申请空间,再往这个空间里赋值,最后将这个对象加入到0代中。
总结
这篇文章主要就是总结一下python语言中的内存存储机制和垃圾回收机制,这俩个其实是深入学习python的第一步,因为从那时开始,我就开始思考python语言的背后机制,也开始学会了读一些源码,之前也看过雨痕的python学习笔记,不过他的笔记是python2的,其中有一些机制已经发生了改变,不过确实是那个笔记让我发现了新世界。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号