

Docker Swarm

虽然现在docker Swarm 已经使用的少了 但是如果公司服务器在十台左右建议使用docker swarm
- 以群体模式初始化Docker引擎集群
- 向集群添加节点
- 将应用程序服务部署到集群
- 一旦一切运行起来,就管理群
Docker Swarm安装
1.环境准备准四台centos7 并且安装了docker

#初始化一个集群
[root@localhost ~]# docker swarm init --advertise-addr 192.168.148.136
Swarm initialized: current node (pohu1c3zf3qlyg0wxqw8dgffh) is now a manager.
To add a worker to this swarm, run the following command:
docker swarm join --token SWMTKN-1-2vhp67t9cqt8e2ku8q9l4dlhihtgexad8e0fduds31evud9cws-bhkmfax949neyueuvzugyh9em 192.168.148.136:2377
To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.
#上面能看出 家兔建群的方式有两种
1.docker swarm join-token manager
2.docker swarm join-token worker

将node2 假如集群

#查看我们的node
docker node ls

我们一次将node3 worker和node4 加成manager
至此我们就搭建成了一个双主双从的集群!!

测试集群的单点故障!
#1. 手动将我我们的node1 manager主节点的docker 服务停止
# 我们看node4 会不会自动取代我们的node1 成为主节点

思考:要想搭建一个swarm 集群到底需要多少个manager 节点呢?
swarm 是遵循raft协议的
实现swarm高可用
#1. 将node3 移除集群
[root@localhost ~]# docker swarm leave
Node left the swarm.
#2. 将我们的node3 以manager的角色假如集群

我这里将node3 移除再想假如集群报错 可能是主机名一样 所有重新改了主机名重新创建了集群

现在 我们将我们的node1停止了

将我们的node1 停掉看我们的集群依然可用
现在我们再将node3 停止看效果

重新开启我们的node3 node1 发现我们的node4 已经成为我们的 leader了

实战
484 docker service create -p 8888:80 --name my-nginx nginx
485 docker service ls
486 docker service update --help
docker service update --replicas 3 my-nginx #创建三个副本
1.创建一个服务
[root@node1 ~]# docker service create -p 1111:80 --name nginx-service nginx

我们已经创建了一个service 他会随机的在node上运行
我们别用node1-4 的ip:1111 访问下 看是否我们的集群功能是否实现


测试我们的集群是能够实现的
接下来我们试下下负载均衡
我们增加副本数(动态扩缩容)
[root@node1 ~]# docker service update --replicas 8 nginx-service
=====> 等价于 docker service scale nginx-service=8


我们能看到我们的每个node上都是负载了2个容器
至此我们的动态扩缩容和集群的负载均衡完成
补充: raft协议详解
说明
分布式存储系统通常通过维护多个副本来进行容错,提高系统的可用性。要实现此目标,就必须要解决分布式存储系统的最核心问题:维护多个副本的一致性。
首先需要解释一下什么是一致性(consensus),它是构建具有容错性(fault-tolerant)的分布式系统的基础。 在一个具有一致性的性质的集群里面,同一时刻所有的结点对存储在其中的某个值都有相同的结果,即对其共享的存储保持一致。集群具有自动恢复的性质,当少数结点失效的时候不影响集群的正常工作,当大多数集群中的结点失效的时候,集群则会停止服务(不会返回一个错误的结果)。
一致性协议就是用来干这事的,用来保证即使在部分(确切地说是小部分)副本宕机的情况下,系统仍然能正常对外提供服务。一致性协议通常基于replicated state machines,即所有结点都从同一个state出发,都经过同样的一些操作序列(log),最后到达同样的state。
架构
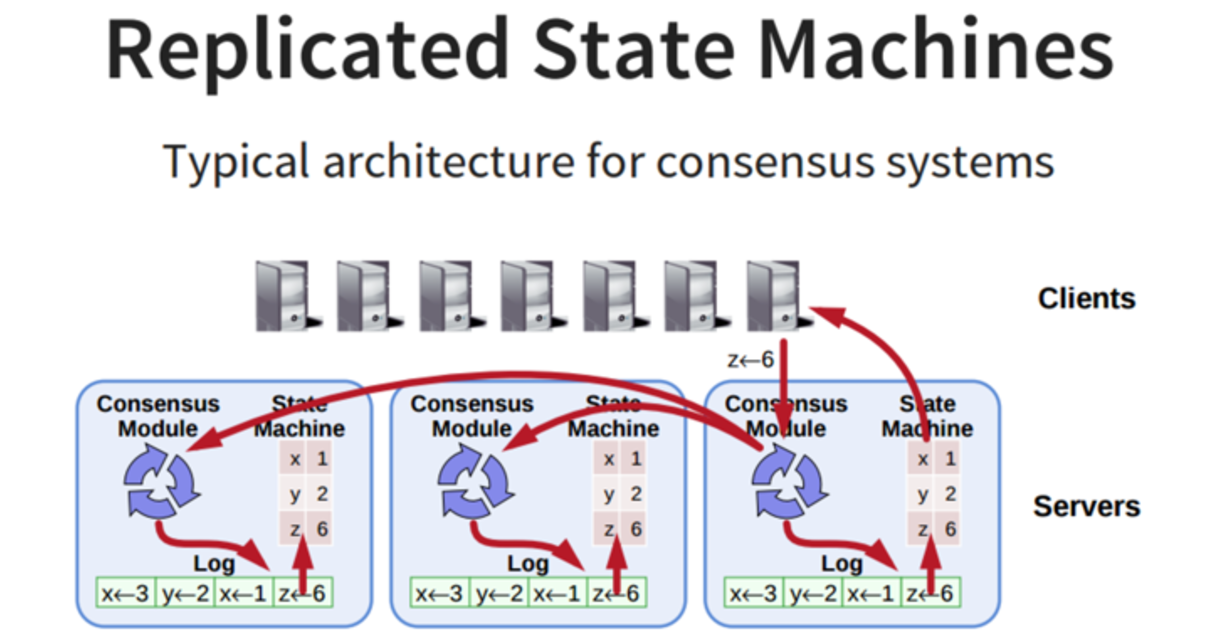
系统中每个结点有三个组件:
状态机: 当我们说一致性的时候,实际就是在说要保证这个状态机的一致性。状态机会从log里面取出所有的命令,然后执行一遍,得到的结果就是我们对外提供的保证了一致性的数据
Log: 保存了所有修改记录
一致性模块: 一致性模块算法就是用来保证写入的log的命令的一致性,这也是raft算法核心内容
协议内容
Raft协议将一致性协议的核心内容分拆成为几个关键阶段,以简化流程,提高协议的可理解性。
Leader election
Raft协议的每个副本都会处于三种状态之一:Leader、Follower、Candidate。
Leader:所有请求的处理者,Leader副本接受client的更新请求,本地处理后再同步至多个其他副本;
Follower:请求的被动更新者,从Leader接受更新请求,然后写入本地日志文件
Candidate:如果Follower副本在一段时间内没有收到Leader副本的心跳,则判断Leader可能已经故障,此时启动选主过程,此时副本会变成Candidate状态,直到选主结束。
时间被分为很多连续的随机长度的term,term有唯一的id。每个term一开始就进行选主:
- Follower将自己维护的current_term_id加1。
- 然后将自己的状态转成Candidate
- 发送RequestVoteRPC消息(带上current_term_id) 给 其它所有server
这个过程会有三种结果:
- 自己被选成了主。当收到了majority的投票后,状态切成Leader,并且定期给其它的所有server发心跳消息(不带log的AppendEntriesRPC)以告诉对方自己是current_term_id所标识的term的leader。每个term最多只有一个leader,term id作为logical clock,在每个RPC消息中都会带上,用于检测过期的消息。当一个server收到的RPC消息中的rpc_term_id比本地的current_term_id更大时,就更新current_term_id为rpc_term_id,并且如果当前state为leader或者candidate时,将自己的状态切成follower。如果rpc_term_id比本地的current_term_id更小,则拒绝这个RPC消息。
- 别人成为了主。如1所述,当Candidator在等待投票的过程中,收到了大于或者等于本地的current_term_id的声明对方是leader的AppendEntriesRPC时,则将自己的state切成follower,并且更新本地的current_term_id。
- 没有选出主。当投票被瓜分,没有任何一个candidate收到了majority的vote时,没有leader被选出。这种情况下,每个candidate等待的投票的过程就超时了,接着candidates都会将本地的current_term_id再加1,发起RequestVoteRPC进行新一轮的leader election。
投票策略:
- 每个节点只会给每个term投一票,具体的是否同意和后续的Safety有关。
- 当投票被瓜分后,所有的candidate同时超时,然后有可能进入新一轮的票数被瓜分,为了避免这个问题,Raft采用一种很简单的方法:每个Candidate的election timeout从150ms-300ms之间随机取,那么第一个超时的Candidate就可以发起新一轮的leader election,带着最大的term_id给其它所有server发送RequestVoteRPC消息,从而自己成为leader,然后给他们发送心跳消息以告诉他们自己是主。
Log Replication
当Leader被选出来后,就可以接受客户端发来的请求了,每个请求包含一条需要被replicated state machines执行的命令。leader会把它作为一个log entry append到日志中,然后给其它的server发AppendEntriesRPC请求。当Leader确定一个log entry被safely replicated了(大多数副本已经将该命令写入日志当中),就apply这条log entry到状态机中然后返回结果给客户端。如果某个Follower宕机了或者运行的很慢,或者网络丢包了,则会一直给这个Follower发AppendEntriesRPC直到日志一致。
当一条日志是commited时,Leader才可以将它应用到状态机中。Raft保证一条commited的log entry已经持久化了并且会被所有的节点执行。
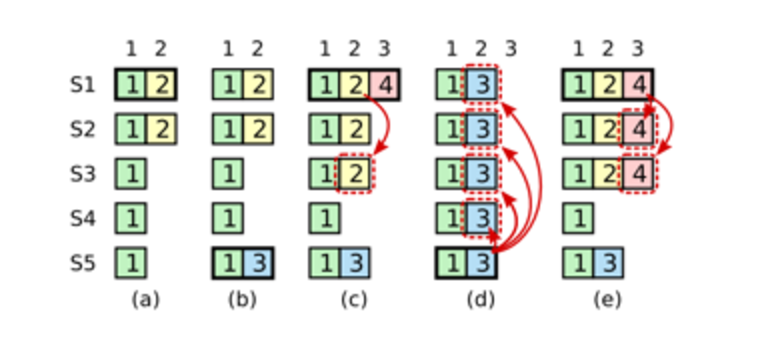
当一个新的Leader被选出来时,它的日志和其它的Follower的日志可能不一样,这个时候,就需要一个机制来保证日志的一致性。一个新leader产生时,集群状态可能如下:

最上面这个是新Leader,a~f是Follower,每个格子代表一条log entry,格子内的数字代表这个log entry是在哪个term上产生的。
新Leader产生后,就以Leader上的log为准。其它的follower要么少了数据比如b,要么多了数据,比如d,要么既少了又多了数据,比如f。
因此,需要有一种机制来让leader和follower对log达成一致,leader会为每个follower维护一个nextIndex,表示leader给各个follower发送的下一条log entry在log中的index,初始化为leader的最后一条log entry的下一个位置。leader给follower发送AppendEntriesRPC消息,带着(term_id, (nextIndex-1)), term_id即(nextIndex-1)这个槽位的log entry的term_id,follower接收到AppendEntriesRPC后,会从自己的log中找是不是存在这样的log entry,如果不存在,就给leader回复拒绝消息,然后leader则将nextIndex减1,再重复,知道AppendEntriesRPC消息被接收。
以leader和b为例:
初始化,nextIndex为11,leader给b发送AppendEntriesRPC(6,10),b在自己log的10号槽位中没有找到term_id为6的log entry。则给leader回应一个拒绝消息。接着,leader将nextIndex减一,变成10,然后给b发送AppendEntriesRPC(6, 9),b在自己log的9号槽位中同样没有找到term_id为6的log entry。循环下去,直到leader发送了AppendEntriesRPC(4,4),b在自己log的槽位4中找到了term_id为4的log entry。接收了消息。随后,leader就可以从槽位5开始给b推送日志了。
Safety
- 哪些follower有资格成为leader?
Raft保证被选为新leader的节点拥有所有已提交的log entry,这与ViewStamped Replication不同,后者不需要这个保证,而是通过其他机制从follower拉取自己没有的提交的日志记录
这个保证是在RequestVoteRPC阶段做的,candidate在发送RequestVoteRPC时,会带上自己的最后一条日志记录的term_id和index,其他节点收到消息时,如果发现自己的日志比RPC请求中携带的更新,拒绝投票。日志比较的原则是,如果本地的最后一条log entry的term id更大,则更新,如果term id一样大,则日志更多的更大(index更大)。
- 哪些日志记录被认为是commited?
- leader正在replicate当前term(即term 2)的日志记录给其它Follower,一旦leader确认了这条log entry被majority写盘了,这条log entry就被认为是committed。如图a,S1作为当前term即term2的leader,log index为2的日志被majority写盘了,这条log entry被认为是commited
- leader正在replicate更早的term的log entry给其它follower。图b的状态是这么出来的。
对协议的一点修正
在实际的协议中,需要进行一些微调,这是因为可能会出现下面这种情况:
- 在阶段a,term为2,S1是Leader,且S1写入日志(term, index)为(2, 2),并且日志被同步写入了S2;
- 在阶段b,S1离线,触发一次新的选主,此时S5被选为新的Leader,此时系统term为3,且写入了日志(term, index)为(3, 2);
- S5尚未将日志推送到Followers变离线了,进而触发了一次新的选主,而之前离线的S1经过重新上线后被选中变成Leader,此时系统term为4,此时S1会将自己的日志同步到Followers,按照上图就是将日志(2, 2)同步到了S3,而此时由于该日志已经被同步到了多数节点(S1, S2, S3),因此,此时日志(2,2)可以被commit了(即更新到状态机);
- 在阶段d,S1又很不幸地下线了,系统触发一次选主,而S5有可能被选为新的Leader(这是因为S5可以满足作为主的一切条件:1. term = 3 > 2, 2. 最新的日志index为2,比大多数节点(如S2/S3/S4的日志都新),然后S5会将自己的日志更新到Followers,于是S2、S3中已经被提交的日志(2,2)被截断了,这是致命性的错误,因为一致性协议中不允许出现已经应用到状态机中的日志被截断。
为了避免这种致命错误,需要对协议进行一个微调:
只允许主节点提交包含当前term的日志
针对上述情况就是:即使日志(2,2)已经被大多数节点(S1、S2、S3)确认了,但是它不能被Commit,因为它是来自之前term(2)的日志,直到S1在当前term(4)产生的日志(4, 3)被大多数Follower确认,S1方可Commit(4,3)这条日志,当然,根据Raft定义,(4,3)之前的所有日志也会被Commit。此时即使S1再下线,重新选主时S5不可能成为Leader,因为它没有包含大多数节点已经拥有的日志(4,3)。
Log Compaction
在实际的系统中,不能让日志无限增长,否则系统重启时需要花很长的时间进行回放,从而影响availability。Raft采用对整个系统进行snapshot来处理,snapshot之前的日志都可以丢弃。Snapshot技术在Chubby和ZooKeeper系统中都有采用。
Raft使用的方案是:*每个副本独立的对自己的系统状态进行Snapshot,并且只能对已经提交的日志记录(已经应用到状态机)进行snapshot。*
Snapshot中包含以下内容:
- 日志元数据,最后一条commited log entry的 (log index, last_included_term)。这两个值在Snapshot之后的第一条log entry的AppendEntriesRPC的consistency check的时候会被用上,之前讲过。一旦这个server做完了snapshot,就可以把这条记录的最后一条log index及其之前的所有的log entry都删掉。
- 系统状态机:存储系统当前状态(这是怎么生成的呢?)
snapshot的缺点就是不是增量的,即使内存中某个值没有变,下次做snapshot的时候同样会被dump到磁盘。当leader需要发给某个follower的log entry被丢弃了(因为leader做了snapshot),leader会将snapshot发给落后太多的follower。或者当新加进一台机器时,也会发送snapshot给它。发送snapshot使用新的RPC,InstalledSnapshot。
做snapshot有一些需要注意的性能点,1. 不要做太频繁,否则消耗磁盘带宽。 2. 不要做的太不频繁,否则一旦节点重启需要回放大量日志,影响可用性。系统推荐当日志达到某个固定的大小做一次snapshot。3. 做一次snapshot可能耗时过长,会影响正常log entry的replicate。这个可以通过使用copy-on-write的技术来避免snapshot过程影响正常log entry的replicate。
集群拓扑变化
集群拓扑变化的意思是在运行过程中多副本集群的结构性变化,如增加/减少副本数、节点替换等。
Raft协议定义时也考虑了这种情况,从而避免由于下线老集群上线新集群而引起的系统不可用。Raft也是利用上面的Log Entry和一致性协议来实现该功能。
假设在Raft中,老集群配置用Cold表示,新集群配置用Cnew表示,整个集群拓扑变化的流程如下:
- 当集群成员配置改变时,leader收到人工发出的重配置命令从Cold切成Cnew;
- Leader副本在本地生成一个新的log entry,其内容是Cold∪Cnew,代表当前时刻新旧拓扑配置共存,写入本地日志,同时将该log entry推送至其他Follower节点
- Follower副本收到log entry后更新本地日志,并且此时就以该配置作为自己了解的全局拓扑结构,
- 如果多数Follower确认了Cold U Cnew这条日志的时候,Leader就Commit这条log entry;
- 接下来Leader生成一条新的log entry,其内容是全新的配置Cnew,同样将该log entry写入本地日志,同时推送到Follower上;
- Follower收到新的配置日志Cnew后,将其写入日志,并且从此刻起,就以该新的配置作为系统拓扑,并且如果发现自己不在Cnew这个配置中会自动退出
- Leader收到多数Follower的确认消息以后,给客户端发起命令执行成功的消息
异常分析
- 如果Leader的Cold U Cnew尚未推送到Follower,Leader就挂了,此时选出的新的Leader并不包含这条日志,此时新的Leader依然使用Cold作为全局拓扑配置
- 如果Leader的Cold U Cnew推送到大部分的Follower后就挂了,此时选出的新的Leader可能是Cold也可能是Cnew中的某个Follower;
- 如果Leader在推送Cnew配置的过程中挂了,那么和2一样,新选出来的Leader可能是Cold也可能是Cnew中的某一个,那么此时客户端继续执行一次改变配置的命令即可
- 如果大多数的Follower确认了Cnew这个消息后,那么接下来即使Leader挂了,新选出来的Leader也肯定是位于Cnew这个配置中的,因为有Raft的协议保证。
为什么需要弄这样一个两阶段协议,而不能直接从Cold切换至Cnew?
这是因为,如果直接这么简单粗暴的来做的话,可能会产生多主。简单说明下:
假设Cold为拓扑为(S1, S2, S3),且S1为当前的Leader,如下图:
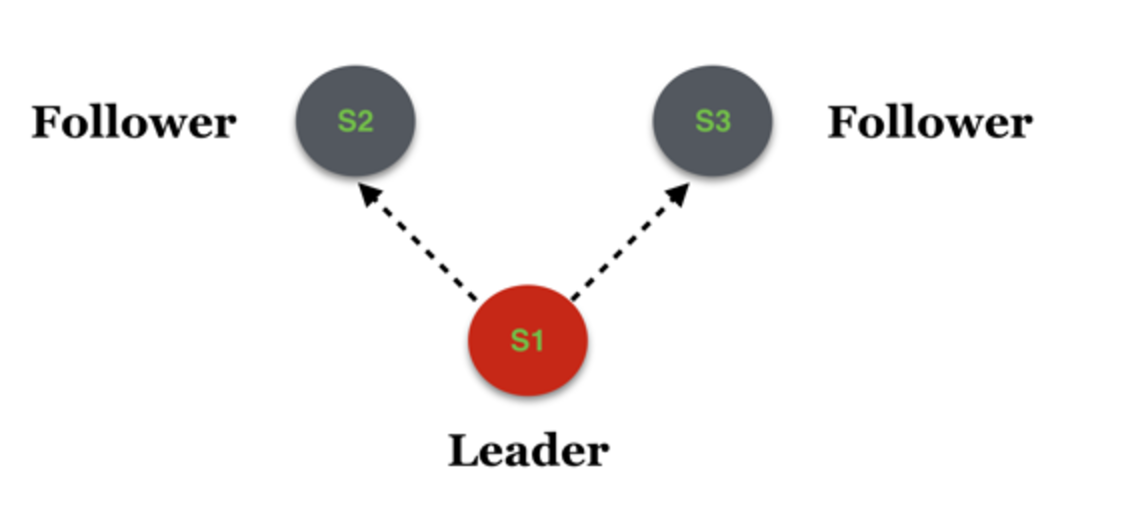
假如此时变更了系统配置,将集群范围扩大为5个,新增了S4和S5两个服务节点,这个消息被分别推送至S2和S3,但是假如只有S3收到了消息并处理,S2尚未得到该消息
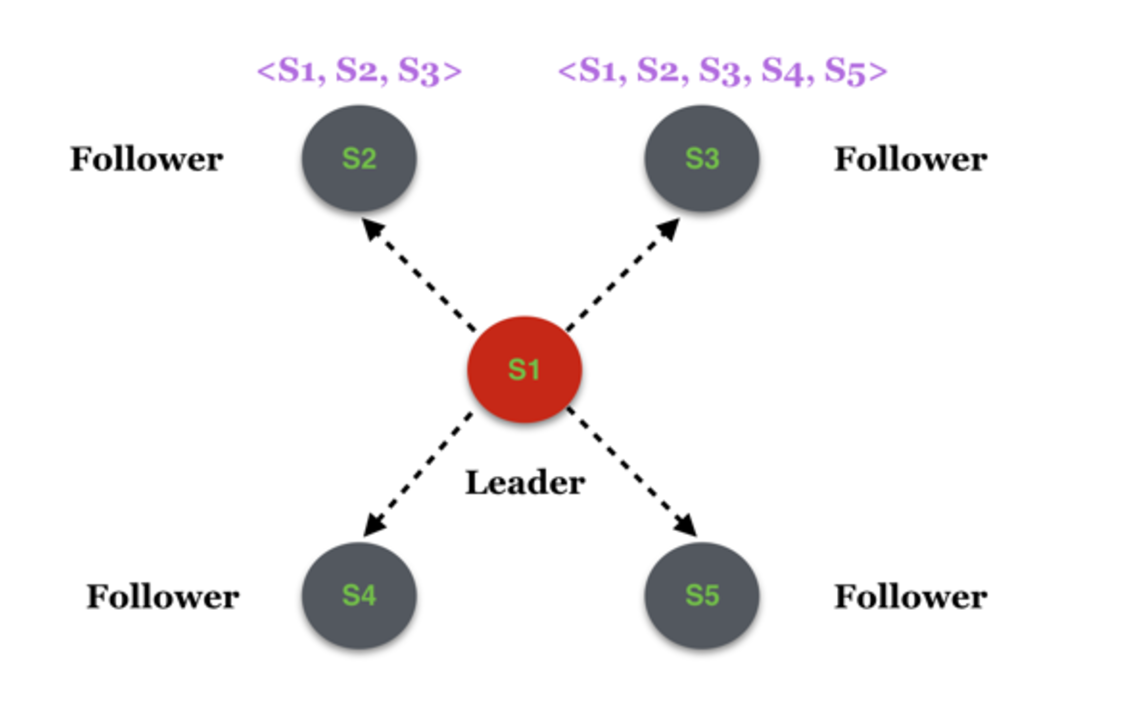
这时在S2的眼里,拓扑依然是<S1, S2, S3>,而在S3的眼里拓扑则变成了<S1, S2, S3, S4, S5>。假如此时由于某种原因触发了一次新的选主,S2和S3分别发起选主的请求:
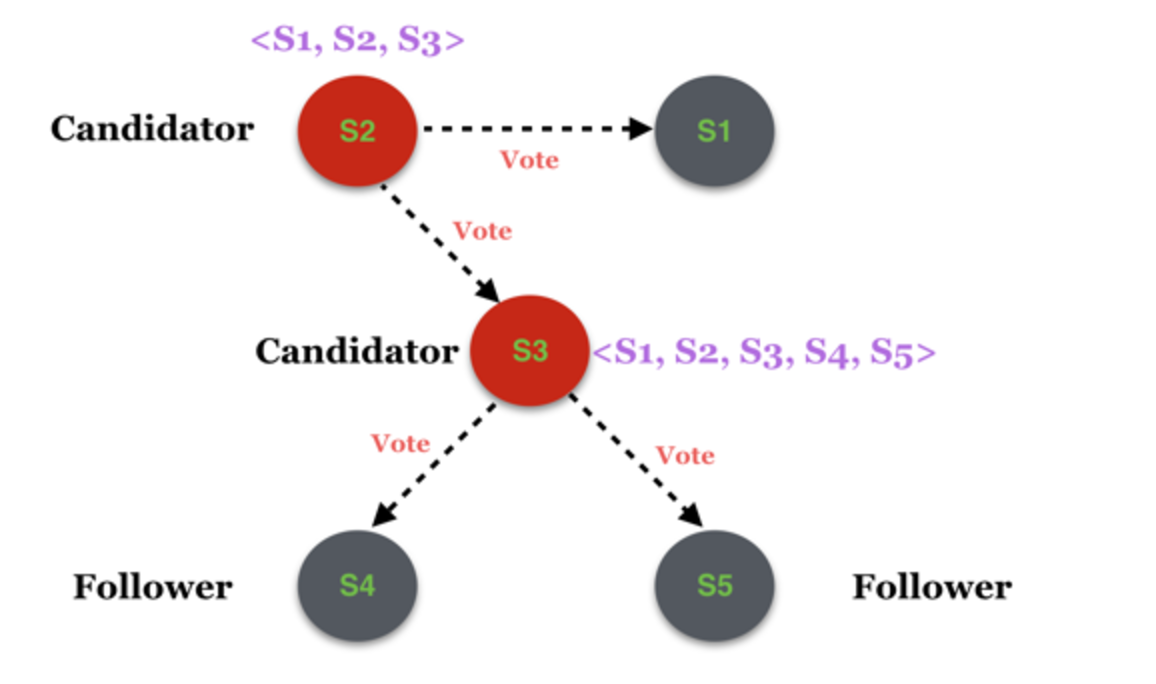
最终,候选者S2获得了S1和S2自己的赞成票,那么在它眼里,它就变成了Leader,而S3获得了S4、S5和S3自己的赞成票,在它眼里S3也变成了Leader,那么多Leader的问题就产生了。而产生该问题的最根本原因是S2和S3的系统视图不一致。

