【论文阅读笔记】QwenLM多模态版本——《Qwen2-VL: Enhancing Vision-Language Model’s Perception of the World at Any Resolution》
论文地址:https://arxiv.org/pdf/2409.12191
代码地址:https://github.com/QwenLM/Qwen2-VL

Qwen
Qwen(通义千问)为大模型家族,其 base model 为 Qwen,目前已经衍生出众多适应下游任务的大模型(图一 [1]),本篇博客重点探讨多模态版本 Qwen-VL 以及 Qwen2-VL。
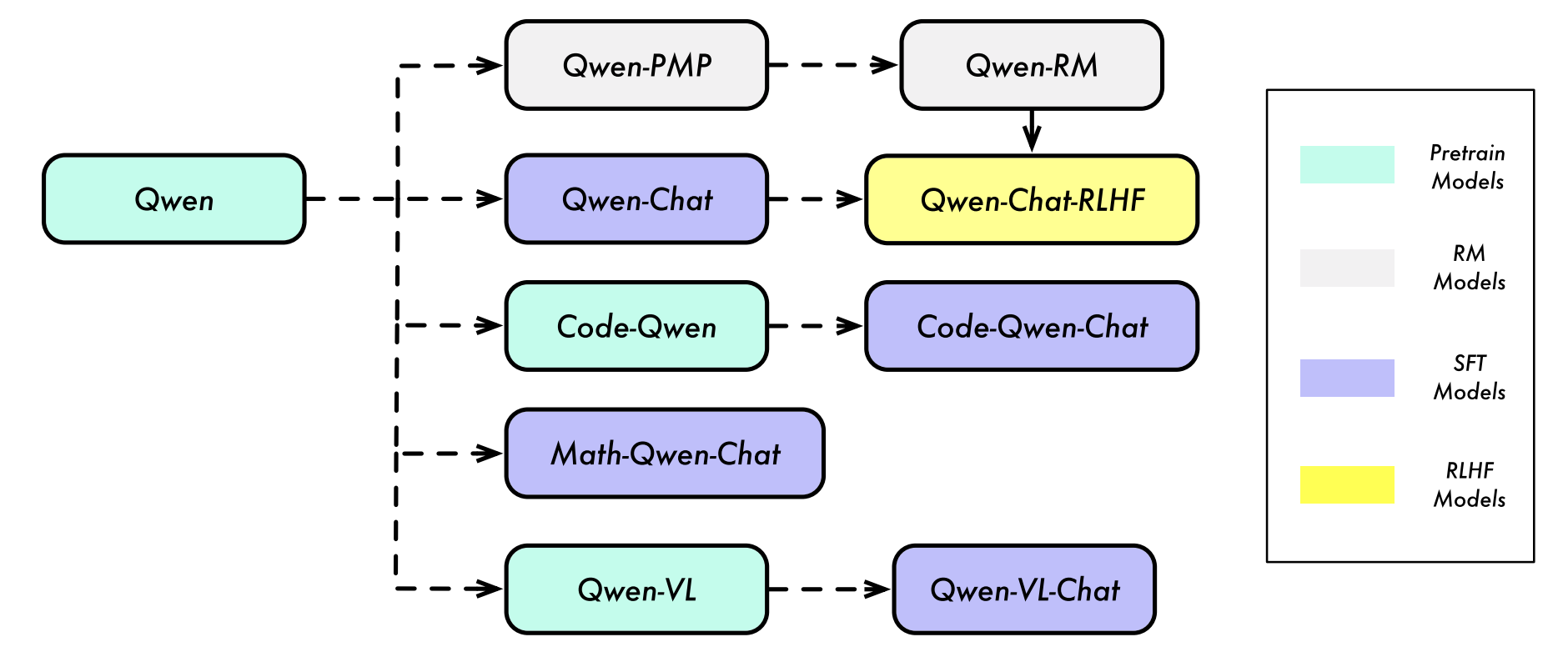
图 1:Qwen 大模型家族
Qwen-VL
Qwen-VL 是基于 Qwen-7B 的一系列高性能、通用的 LVLM(Large Vision-Language Model)。
Features of Qwen-VL: Leading performance, Multi-lingual(most base on Chinese and English), Multi-image, Fine-grained visual understanding.
模型架构
- Foundation Component: initialized with pretrained weights from Qwen-7B
- Visual Encoder: Vision Transformer, initialized with pre-trained weights from ViT-bigG.
- Position-aware Vision-Language Adapter: a single-layer cross-attention module initialized randomly
输入图片首先被裁剪为统一像素,然后被 Encoder 分割成 14*14 的小块。最后通过一个交叉注意力模块(模块提供 \(Q\),Encoder 输出序列提供 \(KV\))压缩成长度 256 ,包含 2D 位置信息的序列。Detail 和 Pipline 如图 2 [2]所示。

图 2:Detail of parameters and training pipline.
Input and Output
- Image Input: 输入图片经过上节的处理后,首尾加上 <img> 和 </img> 两个 token
- Bounding Box Input and Output: 利用一组形如 \((X_{topleft},Y_{topleft}),(X_{bottomright},Y_{bottomright})\) 的字符串(两端加上 <box> 和 </box>)标记出 bounding box;然后利用 <ref> 和 </ref> 将其与其对应描述性的序列对应起来。用来训练出能够应对细粒度问题(如指定区域的描述、问答等)的模型。
训练
如图 2 所示,训练需要经过 2-stage 预训练以及 1-stage 指令微调。
Pre-training
主要利用大规模的、弱标记的、网络抓取的图像-文本对,分辨率为 224*224(图 3)。
冻结 LLM,只训练 vision encoder 和 VL adapter。
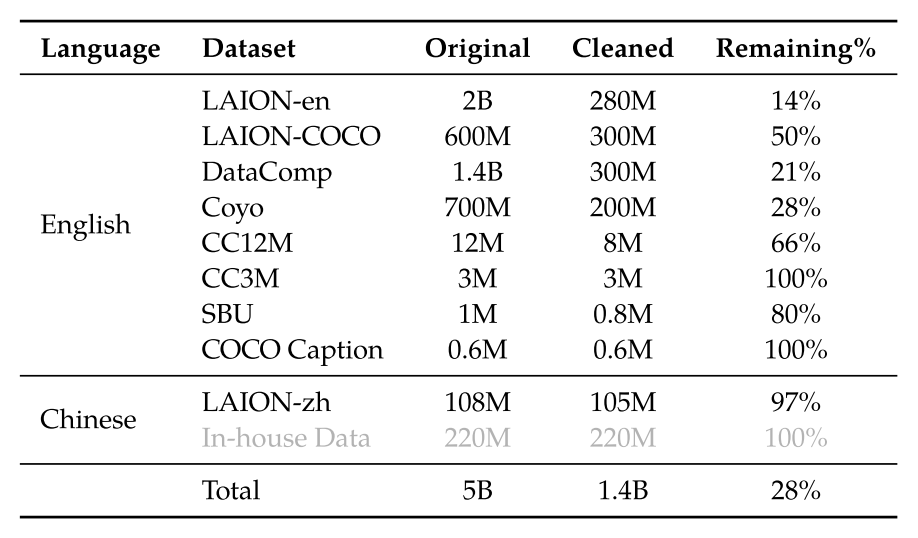
图 3:第一阶段训练数据
Multi-task Pre-training
引入了具有较大分辨率的高质量和细粒度的 VL 标注数据以及交错的图像-文本数据,分辨率为 448*448(图 4)。
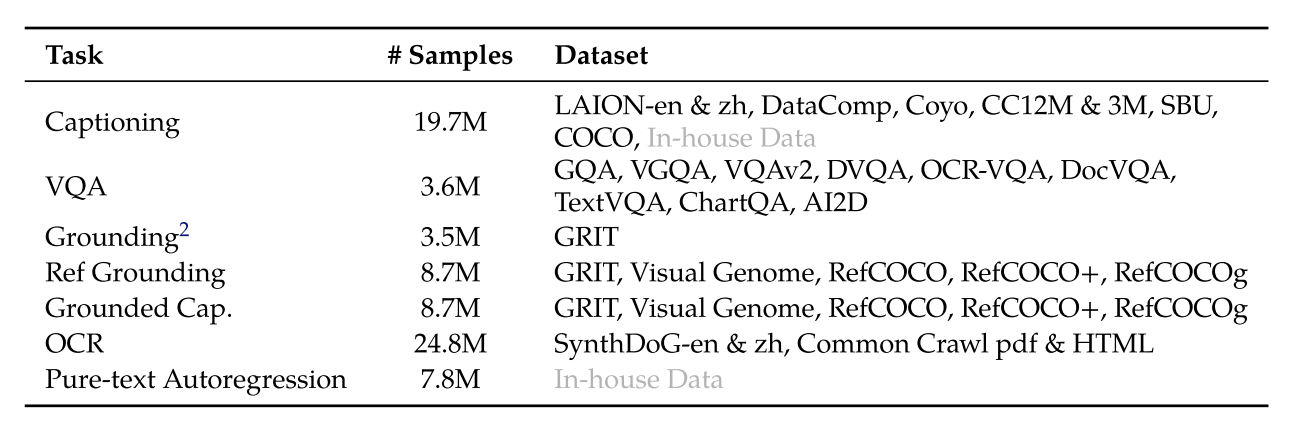
图 4:第二阶段训练数据
Supervised Fine-tuning
利用指令微调强化模型的指令遵循以及对话能力(产生了 Qwen-VL-Chat 模型)。除了大部分 LLM 自己生成的标注以及对话数据外,作者团队人工构建了高质量的对话数据;此外,团队将纯文本对话和多模态混合在一起,以确保模型在对话方面的通用性。
Evalution
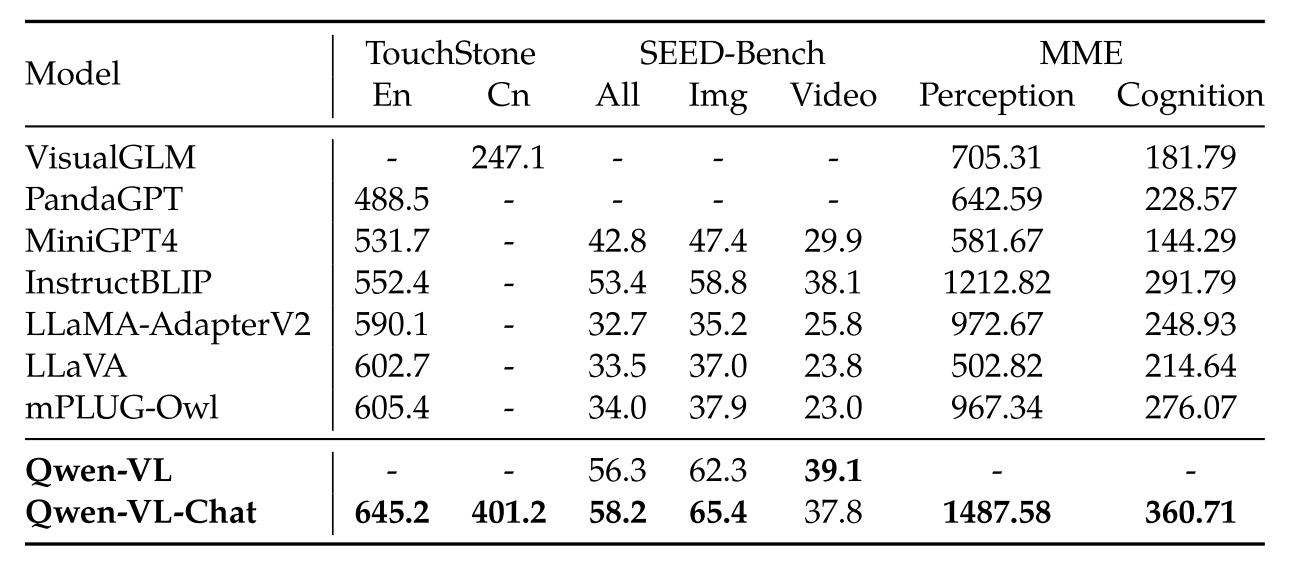
表 1:Image Captioning and General VQA
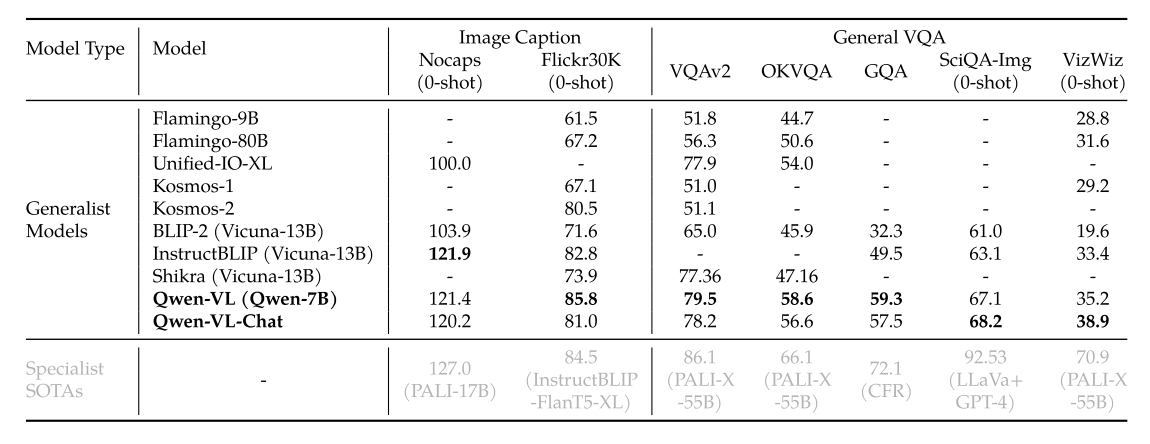
表 2:Text-oriented VQA(与普通的 VQA 相比,模型需要理解图片中的文本信息)
表 3:Referring Expression Comprehension(根据描述标出 bounding box)
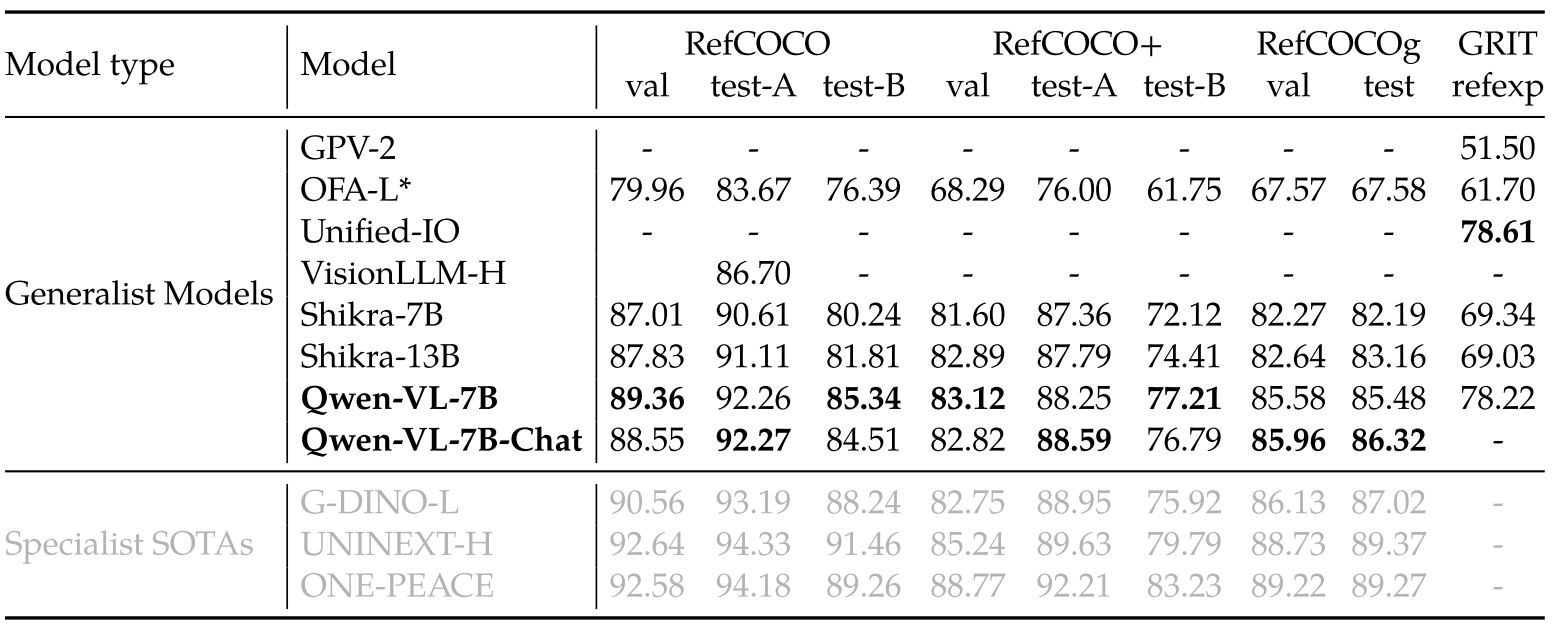
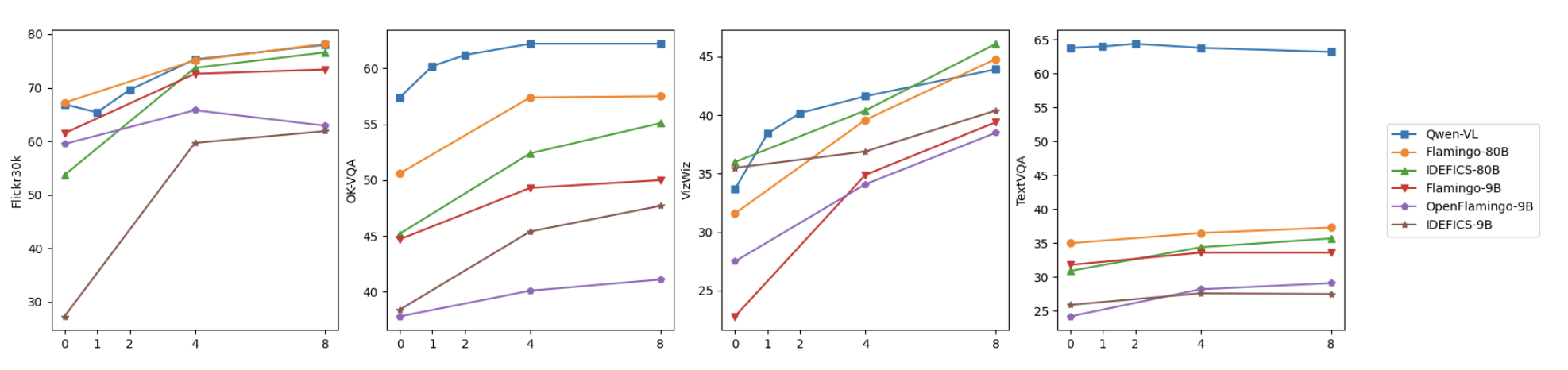
图 5:Few-shot learning results
表 4:Instruction-following benchmarks