
一分钟了解 ChatGPT 语音对话
一、背景
近期 ChatGPT 推出新的语音和图像功能,可以与用户进行语音对话或基于用户上传的图像进行分析和对话,提供了一种新的、更直观的交互体验。用户可以更轻松地表达自己的需求、提出问题,并获得 ChatGPT 的回答和建议。而且,语音合成的真实度让用户感觉像是在与真实的对话伙伴进行交流,提供了更加沉浸式和互动性强的体验。
在接下来的部分,我将对 ChatGPT mobile App 语音对话功能背后的原理进行分析和探讨。通过一个实际的案例 Demo 来进行演示。我将展示一个完整的 ChatGPT 语音对话场景,以帮助您更好地了解其工作方式。
二、语音对话的原理
目前我从事是音视频产品,刚好对音频采集和播放有一定的了解。然后经常关注 OpenAI 的最新动态,每一次新的功能发布,都会上手体验。所以使用 ChatGPT mobile App 语音对话功能时,脑海中立刻浮现出下面这个调用链图。
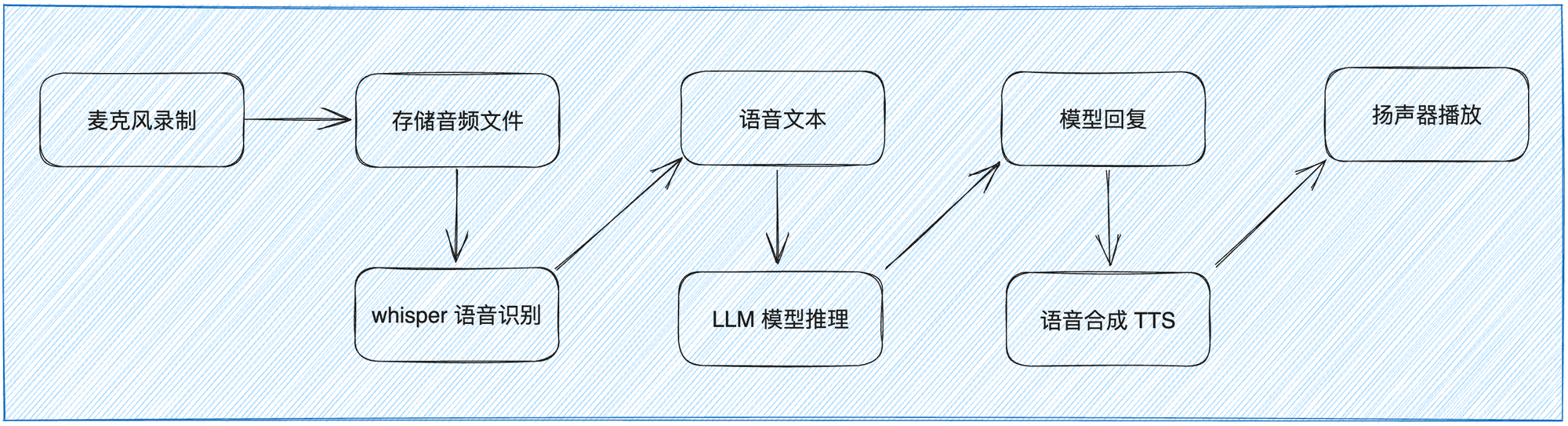
智能语音对话的关键步骤:
- 第一步:设备采集语音输入,然后通过语音识别(ASR)模型(如 Whisper)将语音转换为文本。
- 第二步:然后,将识别的文本将被提交给大型语言模型(如 LLM)进行推理和处理。LLM 模型会根据上下文、语义和用户意图等信息生成回复文本。
- 第三步:最后,生成的文本结果会经过语音合成(TTS)技术转换为语音,并通过设备的扬声器进行播放。
这样,用户就能通过语音与系统进行交互,并听到自然流畅的语音回复。整个过程结合了语音处理、文本处理和语音合成等关键技术,以实现语音对话的交互体验。
三、语音转文字 + 模型推理 + 语音合成
恕我直言,只有极少的天才能够写模型算法,极少数的公司有财力训练模型。市面产品都是套壳,所以各位都别折腾了,直接调用云厂商的 API 吧。
3.1 语音识别
OpenAI 语音转文字 API 是基于开源大型 v2 Whisper 模型。可以用于将音频转录为与音频所在语言相同的语言以及将音频翻译并转录成英文。文件上传目前限制为 25 MB,支持以下输入文件类型:mp3、mp4、mpeg、mpga、m4a、wav 和 webm。
curl --location 'https://api.openai.com/v1/audio/transcriptions' \
--header 'Authorization: Bearer sk-xxxx' \
--form 'model="whisper-1"' \
--form 'file=@"/Users/xxx/output.wav"'
3.2 模型推理
大模型是做什么就不介绍了,这里使用 GPT-3.5-turbo 模型是以一系列消息作为输入,并将模型生成的消息作为输出。
curl --location 'https://api.openai.com/v1/chat/completions' \
--header 'Authorization: Bearer sk-xxx' \
--header 'Content-Type: application/json' \
--data '{
"model": "gpt-3.5-turbo",
"max_tokens": 20,
"messages": [
{
"role": "user",
"content": "Lorem ipsum"
}
]
}'
其中,OpenAI 的 API 服务不对中国大陆开放,可以使用 Cloudflare worker 解决了用户没有 VPN 的痛点。
3.3 语音合成
语音合成(Text-to-Speech,TTS)技术是指将文本转换为语音输出的过程。实现可以使用 AVSpeechSynthesizer 在 iOS 上实现类似于 say 命令的能力,另外一种方式使用 Azure 文本转语音服务,使您的应用程序、工具或设备能够将文本转换为类似人声的合成语音。
curl --location 'https://{xxx}.tts.speech.microsoft.com/cognitiveservices/v1' \
--header 'Ocp-Apim-Subscription-Key: {xxx}' \
--header 'Content-Type: application/ssml+xml' \
--header 'X-Microsoft-OutputFormat: audio-16khz-128kbitrate-mono-mp3' \
--data '<speak version="1.0" xml:lang="en-US">
<voice xml:lang="en-US" xml:gender="Female" name="en-US-JennyNeural">
my voice is my passport verify me
</voice>
</speak>'
其中,Azure 的 API 服务对中国大陆开放,实测网络质量还可以。
四、语音对话 Demo
到现在我们完成全部的调研工作,剩下的需要将这一切串联起来,就可以实现一个类似于 ChatGPT mobile App 的语音对话的产品功能。Now, let’s move!
语音采集是在 iOS 上完成的,使用 AVAudioRecorder 原生支持 M4A(MPEG-4 Audio)文件格式。M4A 文件通常包含使用 AAC(Advanced Audio Coding)编码的音频。要使用 AVAudioRecorder 录制 M4A 格式的音频,需要将音频格式设置为 kAudioFormatMPEG4AAC。
NSDictionary *recordSettings = @{
AVFormatIDKey: @(kAudioFormatMPEG4AAC),
AVSampleRateKey: @44100.0,
AVNumberOfChannelsKey: @(channelCount),
AVEncoderAudioQualityKey: @(AVAudioQualityHigh)
};
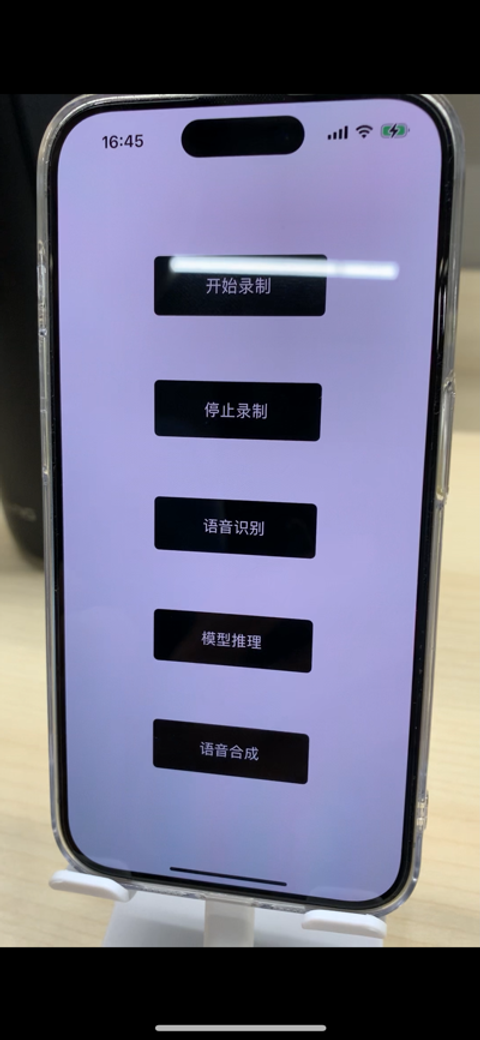
然后增加一个 APP 操作界面,方便观察每个步骤的进行状态。演示视频前往 B 站: https://www.bilibili.com/video/BV1z94y1t7V6
五、参考资料
- ChatGPT 的语音对话功能 https://twitter.com/onenewbite/status/1706511064660369542
- OpenAI 新发布的语音生成技术 https://openai.com/blog/chatgpt-can-now-see-hear-and-speak
- OpenCat 接入 Azure TTS https://twitter.com/waylybaye/status/1641369899267416064
- LLaMA voice chat + Siri TTS https://twitter.com/ggerganov/status/1640416314773700608
- OpenAI speech-to-text API https://platform.openai.com/docs/guides/speech-to-text
- Azure Text to speech API 文档 https://learn.microsoft.com/en-us/azure/ai-services/speech-service

 浙公网安备 33010602011771号
浙公网安备 33010602011771号