
Java按自然语言字符截取字符串
由于unicode字符在java中可能超过2个char,String类自带的substring不能很好的满足要求,可能产生? ,所以按照commons的StringUtils开发了这个方法
/** * 仿照{@link StringUtils#substring(String, int, int)}开发的自然语言截取方法,考虑到了多语言字符截取问题, * 配合nvarchar类型字段的截取函数使用 * @param str 要截取的字符串 * @param start 字符开始位置,包含 * @param end 字符结束位置,不包含 * @return */ public static String naturalSubstring(String str, int start, int end) { if (str == null) { return null; } // handle negatives int naturalLength = str.codePointCount(0, str.length()); if (end < 0) { end = naturalLength + end; // remember end is negative } if (start < 0) { start = naturalLength + start; // remember start is negative } // check length next if (end > naturalLength) { end = naturalLength; } // if start is greater than end, return "" if (start > end) { return ""; } if (start < 0) { start = 0; } if (end < 0) { end = 0; } StringBuilder result = new StringBuilder(); int codePointCounter = 0; int charIndex = 0; if (start > 0 ) { // 过滤起始 for (; charIndex < str.length() && codePointCounter < start; charIndex++,codePointCounter++) { if (Character.isHighSurrogate(str.charAt(charIndex))) { charIndex++; } } } if (end < naturalLength) { for (; charIndex < str.length() && codePointCounter < end; charIndex++, codePointCounter++) { result.append(str.charAt(charIndex)); if (Character.isHighSurrogate(str.charAt(charIndex))) { result.append(str.charAt(++charIndex)); } } } else { return str.substring(charIndex, str.length()); } return result.toString(); }
测试
// "\uD83D\uDF01" == 🜁 // "\uD801\uDC00" == 𐐀 String test = "🜁𐐀🜁𐐀𐐀🜁🜁𐐀𐐀𐐀"; System.out.println(StringUtil.naturalSubstring(test, 0 ,1)); System.out.println(StringUtil.naturalSubstring(test, 0 ,3)); System.out.println(StringUtil.naturalSubstring(test, 1 ,3)); System.out.println(StringUtil.naturalSubstring(test, 4 ,8)); System.out.println(StringUtil.naturalSubstring(test, 4 ,100)); System.out.println(test.substring(1,3));
显示结果
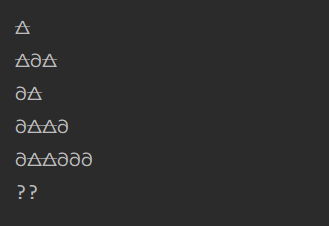
符合预期

 浙公网安备 33010602011771号
浙公网安备 33010602011771号