Pearson相关性分析 —— 入门案例
1.Spearman相关性分析 —— 入门案例
2.Pearson相关性分析 —— 入门案例
简介
Pearson相关系数
Pearson相关系数是一种统计方法,用于衡量两个连续变量之间的线性相关程度。Pearson相关系数的值范围从-1到1,其中:
- 接近1的值表示两个变量之间存在强正线性关系。
- 接近-1的值表示两个变量之间存在强负线性关系。
- 接近0的值表示两个变量之间没有线性关系。
Pearson相关系数可以用来判断数据是否线性相关,但需要注意以下几点:
- 它只能检测线性关系,不能检测非线性关系。
- 它假设两个变量都是连续的,并且分布接近正态分布。
- 它对异常值敏感,异常值可能会对相关系数的计算结果产生较大影响。
Pearson相关系数的计算公式:
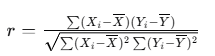
其中:
利用P值检验
Pearson相关系数告诉我们变量之间是否存在线性关系以及这种关系的强度,但并不告诉我们这种关系是否具有统计显著性。p值提供了这种显著性的证据。因此,它们一起使用可以更全面地评估变量之间的关系。
- p值越小,表示观察到的数据与零假设的偏差越大,即我们越有理由拒绝零假设,认为两个变量之间存在某种关系。
- 通常,如果p值小于某个显著性水平(如置信水平0.05),我们认为结果具有统计显著性,即两个变量之间存在显著的相关性。
运行结果
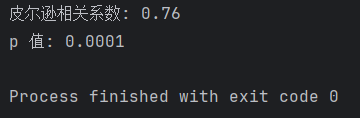
根据结果,人均 GDP 和预期寿命之间的皮尔逊相关系数为 0.76,表示两个变量之间存在较强的正相关关系。p 值非常小(远小于置信水平 0.05),因此我们可以拒绝零假设,认为人均 GDP 和预期寿命之间存在显著的线性相关性。
Full Code
import numpy as np
from scipy.stats import pearsonr
# 第一列代表GDP,第二列代表人均寿命
gdp = np.array([62794, 39286, 47603, 42943, 41464, 34483, 46233, 31362, 11289, 8920,
9771, 2010, 57305, 30371, 9946, 3894, 52367, 23219, 9370, 82950])
life_expectancy = np.array([78.5, 84.1, 80.8, 80.9, 82.3, 82.8, 81.9, 82.0, 72.4, 75.1,
76.4, 68.8, 82.6, 83.1, 75.0, 71.5, 81.6, 74.8, 77.4, 83.3])
corr, p_value = pearsonr(gdp, life_expectancy)
print(f"皮尔逊相关系数: {corr:.2f}")
print(f"p 值: {p_value:.4f}")


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 终于写完轮子一部分:tcp代理 了,记录一下
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理