DBSCAN聚类入门案例
简介
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的聚类算法,它能够将具有足够高密度的区域划分为聚类,并将低密度区域的点视为噪声。
DBSCAN的主要特点
1. 无需指定聚类数目:与K-means等算法不同,DBSCAN不需要预先指定聚类的数量。
2. 对噪声鲁棒:DBSCAN可以识别并处理数据中的噪声点,将它们标记为噪声而不是错误地归入某个聚类。
3. 发现任意形状的聚类:DBSCAN可以识别出任意形状的聚类,而不仅仅是球形或圆形。
DBSCAN算法动态示意图
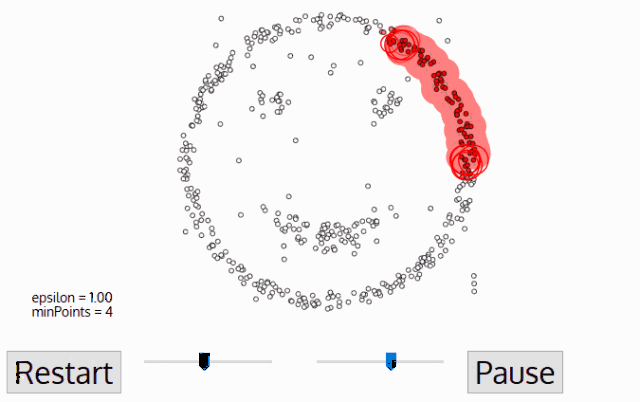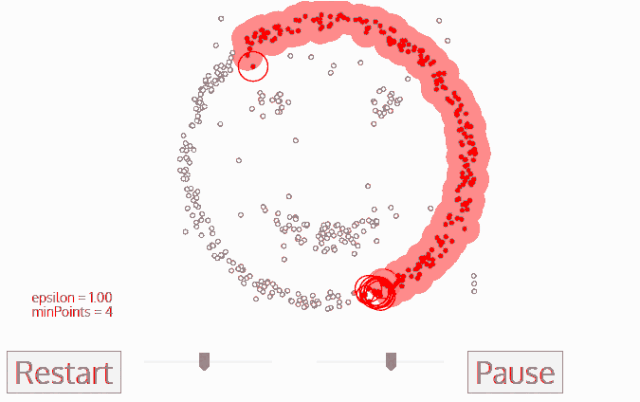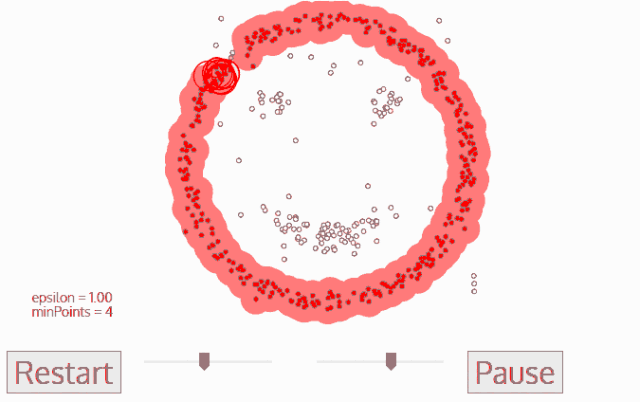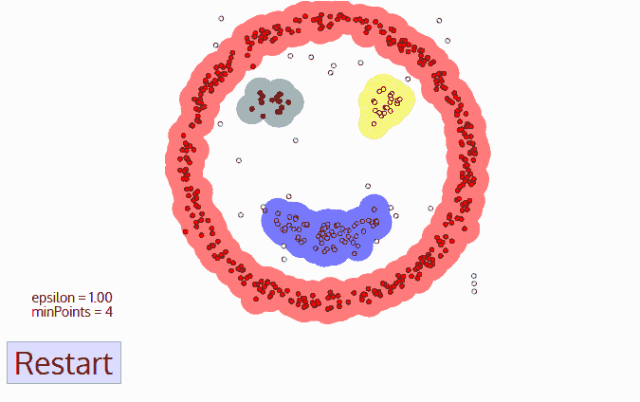
sklearn库中的DBSCAN实例使用
在sklearn库中,DBSCAN类实现了DBSCAN聚类算法。以下是一些关键参数的简要介绍:
1. eps (float): 表示邻域半径,即考虑一个点的邻域时的最大距离。这个参数定义了两点之间的最大距离,如果在这个距离内的点被认为是相互连接的。eps的选择对聚类结果有很大影响。
2. min_samples (int): 表示一个点成为核心点所需的最小邻居数目,包括点本身。如果一个点的ε邻域内至少有min_samples个点,则该点被认为是核心点。这个参数与eps一起决定了聚类的形状和大小。
3. metric (string or callable): 用于计算两点之间距离的度量方式。默认是'minkowski'(闵可夫斯基距离),但也可以是'euclidean'(欧几里得距离)、'manhattan'(曼哈顿距离)等,或者是一个自定义的距离度量函数。
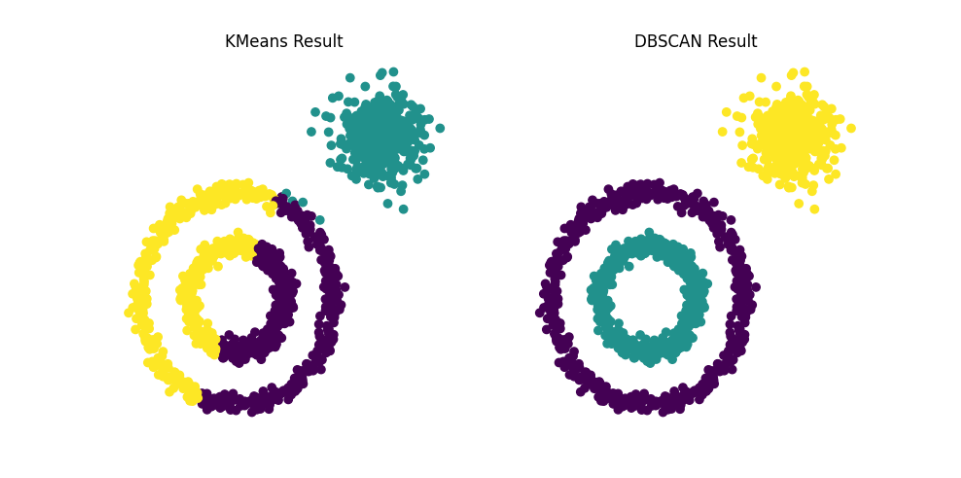
运行截图
本案例创建了两个同心圆环形点簇及一个远离圆环的球形点簇,作为训练数据。随后分别使用KMeans和DBSCAN聚类算法对点集进行分类,并可视化展示分类结果。
Full Code
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans, DBSCAN
from sklearn import datasets
# 创建两个同心圆环数据
X, y = datasets.make_circles(n_samples=1000, noise=0.05, factor=0.5)
# 创建右上角的点簇
X1, y1 = datasets.make_blobs(n_samples=500, n_features=2, centers=[(1.5, 1.5)], cluster_std=0.2)
# 合并数据
X = np.concatenate((X, X1), axis=0)
y = np.concatenate((y, y1 + 2), axis=0)
# 使用Kmeans聚类
kMeans_instance = KMeans(n_clusters=3)
kMeans_instance.fit(X)
y_pred1 = kMeans_instance.predict(X)
# 使用DBSCAN聚类
DBSCAN_instance = DBSCAN(eps=0.2, min_samples=3)
DBSCAN_instance.fit(X)
y_pred2 = DBSCAN_instance.labels_
# 绘图部分
# 创建图像显示的子图
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(10, 5))
ax1.scatter(X[:, 0], X[:, 1], c=y_pred1)
ax1.set_title('KMeans Result')
ax1.axis('off') # 不显示坐标轴
ax2.scatter(X[:, 0], X[:, 1], c=y_pred2)
ax2.set_title(f'DBSCAN Result')
ax2.axis('off') # 不显示坐标轴
plt.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号