KMeans特征提取图片压缩 —— 聚类入门案例
简介
聚类算法
聚类算法是一种无监督学习算法,主要用于将数据集中的对象分组,使得同一组内的对象相似度高,而不同组之间的对象相似度低。聚类算法在许多领域都有应用,包括市场研究、社交网络分析、生物信息学等。
KMeans算法
KMeans(K均值)算法是聚类算法中最著名的一种,它通过迭代过程将数据点划分到K个簇中。
以下是KMeans算法的基本步骤:
- 选择K值:确定要分成的簇的数量。
- 初始化中心点:随机选择K个数据点作为初始的簇中心。
- 分配数据点:分别计算每个点与每个簇中心的距离,将其分配到最近的簇中心。
- 更新簇中心:重新计算每个簇的中心坐标,通常是簇内所有点的坐标均值。
- 迭代优化:重复步骤3和4,直到簇中心不再显著变化或达到预设的迭代次数。
KMeans算法流程示意图
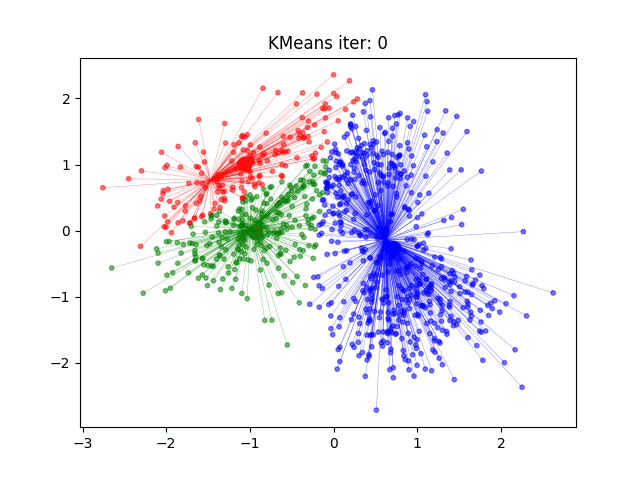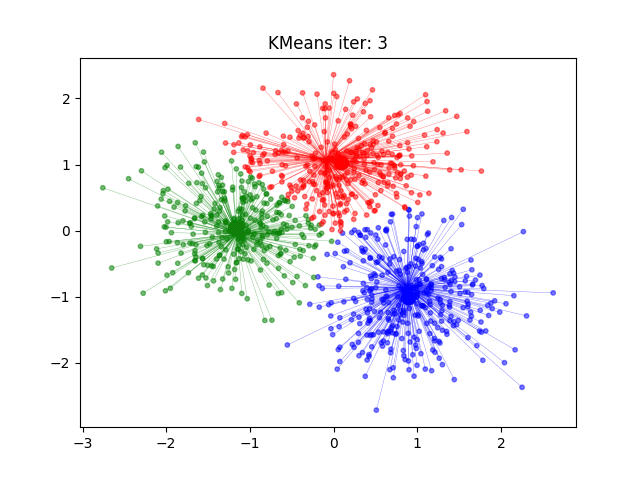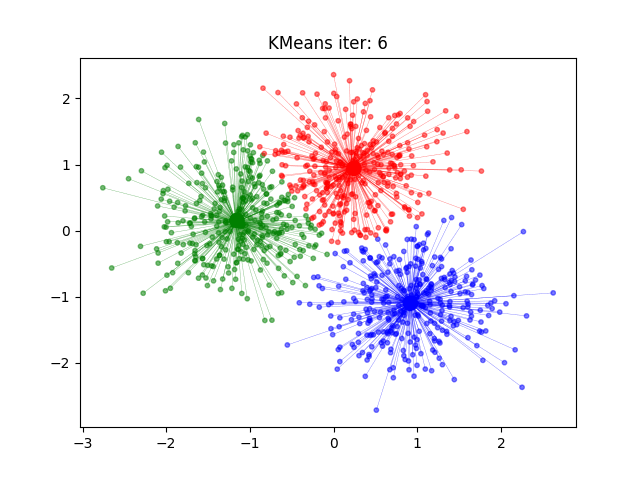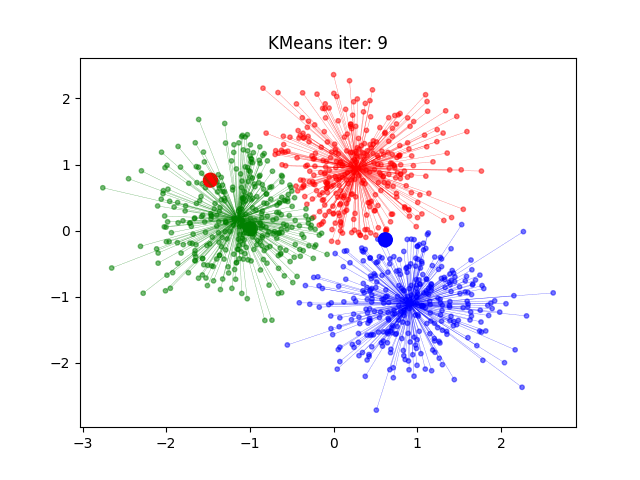
KMeans算法的时间复杂度
KMeans算法的时间复杂度主要取决于以下几个因素:
- 数据点的数量(n):算法需要处理的数据点总数。
- 特征的维度(d):每个数据点的特征数量。
- 簇的数量(k):算法需要找到的簇的数量。
- 迭代次数(i):算法收敛所需的迭代次数。
KMeans算法的时间复杂度可以近似表示为 $ O(k·n·d·i) $
KMeans算法的优缺点
- 简单易懂,容易实现。
- 计算效率相对较高,尤其是在数据集不是很大时。
KMeans算法的缺点包括:
- 对初始簇中心的选择敏感,不同的初始值可能导致不同的结果。
- 对噪声和异常值敏感,可能会影响聚类结果。
- 需要预先指定K值,而K值的选择往往依赖于问题和领域知识。
- 只能发现圆形或球形的簇,对于非球形的簇可能效果不佳。
案例简介
本案例展示了如何使用KMeans聚类算法对图像进行颜色压缩,以达到简化图像颜色、提取图像特征并减少存储空间的目的。使用sklearn库中的KMeans类,快捷地完成图像颜色分类任务。
运行结果

Full Code
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
IMG_PATH = './avatar.png'
COLOR_CNT = 8
img = plt.imread(IMG_PATH)
h, w = img.shape[:2]
X = img.reshape(-1, 3) # 图片转二维训练数据
kmeans = KMeans(n_clusters=COLOR_CNT) # 几种主要颜色
kmeans.fit(X)
main_colors = kmeans.cluster_centers_ # 提取出的主要颜色
y_pred = kmeans.predict(X)
img_result = main_colors[y_pred]
img_result = img_result.reshape(h, w, 3)
# 绘图部分
# 创建图像显示的子图
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(10, 5))
# 显示原图
ax1.imshow(img)
ax1.set_title('Original Image')
ax1.axis('off') # 不显示坐标轴
# 显示生成图
ax2.imshow(img_result)
ax2.set_title(f'Generated Image with {COLOR_CNT} Main Colors')
ax2.axis('off') # 不显示坐标轴
# 显示图像
plt.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号