[SVM入门]基于SVM的楼道门牌号识别模型
简介
SVM
支持向量机(SVM)是一种强大的监督学习算法,主要用于分类和回归分析。它通过在特征空间中寻找一个最优的超平面来实现数据的分类,核心思想是最大化决策边界的宽度,即间隔最大化。SVM特别适用于中小型复杂数据集的分类问题,并且具有良好的泛化能力。
SVM处理图像分类问题的原理是将图像数据映射到高维空间中,在这个空间中寻找一个最优的超平面来区分不同的类别。对于线性可分的情况,SVM使用线性核函数;对于非线性可分的情况,则使用非线性核函数(如多项式核、径向基函数RBF等)来实现数据的分类。SVM的核方法使得原本线性不可分的数据在高维空间中变得线性可分。
SVM将数据映射到高维超平面的特性,使其能处理复杂的分类问题,尤其适用于本案例为代表的图像分类问题。
mchar
楼道门牌mchar数据集是一个字符识别数据集,来源于Google街景图像中的门牌号数据集(SVHN),用于字符识别比赛。该数据集包含从天池官网下载的图片和相应的标注信息,每张图片包括颜色图像和对应的编码类别及具体位置信息。在字符识别任务中,SVM可以被用来构建图像分类模型,通过对图像特征的学习和分类,实现对字符的识别。
参数说明:
-
"label": 图片中字符。
-
"left": 字符在图片中左边界的x坐标。
-
"top": 字符在图片中顶部的y坐标。
-
"width": 字符的宽度。
-
"height": 字符的高度。
程序流程概要
本案例中,程序执行具体的步骤如下:
-
对图像预处理(灰度化、裁剪、缩放、二值化等)。
-
在小数据范围内训练SVM模型,寻找最优的误差参数C。(交叉验证优化)
-
固定选出的参数C,增大数据集,训练并测试模型。
程序流程
图片预处理
数据集包含图片和json字典数据两部分。
图片为包含若干数字的门牌号,json字典则指示了图片中具体的数字内容,以及数字在图片中的位置。
图片预处理是尤为关键的一步,直接影响了模型的训练成本及拟合度。通过灰度化、裁剪、缩放、二值化等一系列步骤,将原街道门牌图片中的每个数字提取,转为仅包含一个数字的,特征数(即像素数)相同的,可训练且易训练的矩阵。


图片裁剪
根据数字在图片中的坐标,使用pillow库的crop方法,单独裁剪出每个数字。
img_clip = img_gray.crop((info['left'][i], info['top'][i],
info['left'][i] + info['width'][i],
info['top'][i] + info['height'][i]))
图片拉伸
将裁剪出的单独数字图片统一拉伸为固定大小,以保证特征数相同。
IMAGE_SIZE = (16, 16) # 训练图片大小
img_clip = img_clip.resize(IMAGE_SIZE, Image.NEAREST)
拉伸后的图片:


图片二值化
图片背景颜色的不一致问题可能导致模型存在较大噪声,二值化处理可以使图片具有统一的背景色,特征更加突出。
值得注意的是,背景色不一定比数字的颜色浅,如果背景色为黑色,需要进行黑白翻转。采集边角四个点的像素,若黑块的数量 >= 3,则进行黑白翻转。
# 自适应二值化
def binarize(img_array):
_, binary_array = cv2.threshold(img_array, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)
# 通过四个角的权重计算是否需要翻转黑白像素(尽量保证背景是白色,字是黑色)
weight = (int(binary_array[0, 0]) + int(binary_array[H, 0])
+ int(binary_array[0, W]) + int(binary_array[H, W]))
if weight < 510:
cond = (binary_array == 0)
binary_array[...] = 0
binary_array[cond] = 255
binary_array = binary_array.astype(np.uint8)
# debug
# binary_img = Image.fromarray(binary_array) # debug输出二值化后的图片
# binary_img.show()
return binary_array
二值化后的图片:


数据降维
原数据的特征往往只有部分是有效特征。主成分分析(PCA)可以有效降低数据集的特征维度,保留最具有特征区分度的维度。
def decline_features(x_train, x_test):
pca = PCA(n_components=0.95)
x_train_pca = pca.fit_transform(x_train)
x_test_pca = pca.transform(x_test)
return x_train_pca, x_test_pca
训练模型
在本节中,我们介绍了两个关键函数,用于训练支持向量机(SVM)模型并优化其参数。
1. 单次训练函数 once_train
该函数使用指定的正则化参数 param_C 来训练一个使用径向基核函数(RBF)的SVM模型。用于已知较优的C参数情况下的模型训练。
# 单次训练
def once_train(param_C):
svc = SVC(kernel='rbf', C=param_C)
return svc
2. 获取最佳C值函数 get_best_C
此函数的目的是在训练数据较小的前提下,找到最佳的正则化参数 C,以最大化模型的准确率。它首先定义了一个参数网格 param_grid,其中包含了100个在5到20之间均匀分布的 C 值(或者使用 np.arange 来选择一个更粗的搜索网格)。随后通过网格搜索(GridSearchCV)来评估每一组参数。
一旦找到最佳参数,它将打印出最佳 C 值和对应的最佳分数(模型准确率)。之后,函数将使用这个最佳 C 值初始化一个新的SVM模型,并返回这个优化后的模型。
# 获取最佳C值
def get_best_C():
svc = SVC()
param_grid = {'C': np.linspace(5, 20, 100), 'kernel': ['rbf']}
# param_grid = {'C': np.arange(5, 20), 'kernel': ['rbf']}
grid_search = GridSearchCV(estimator=svc, param_grid=param_grid, cv=5, scoring='accuracy')
grid_search.fit(X_train_pca, y_train)
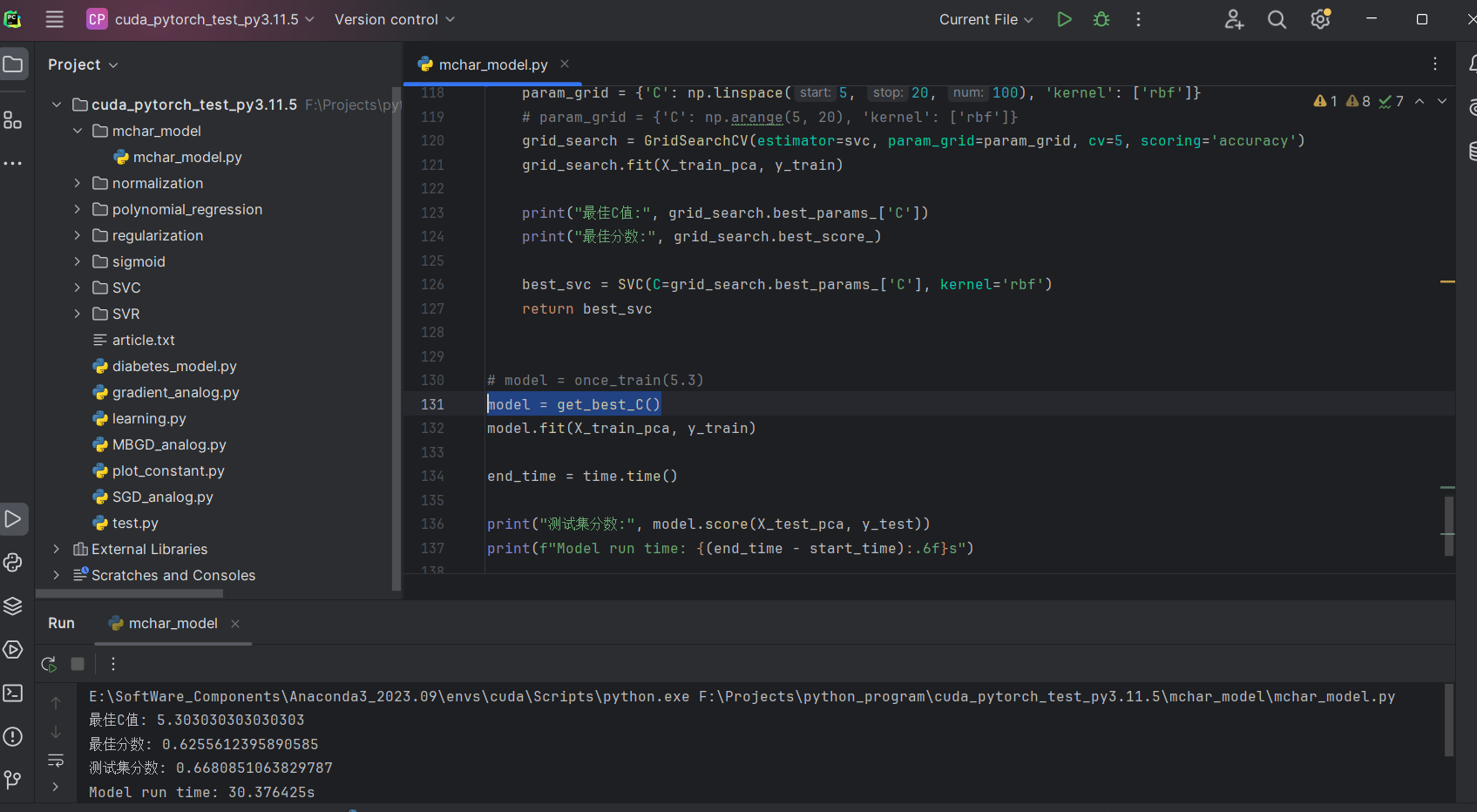
print("最佳C值:", grid_search.best_params_['C'])
print("最佳分数:", grid_search.best_score_)
best_svc = SVC(C=grid_search.best_params_['C'], kernel='rbf')
return best_svc
运行截图
在训练数据TRAIN_IMAGE_CNT = 500的前提下寻找最优参数C
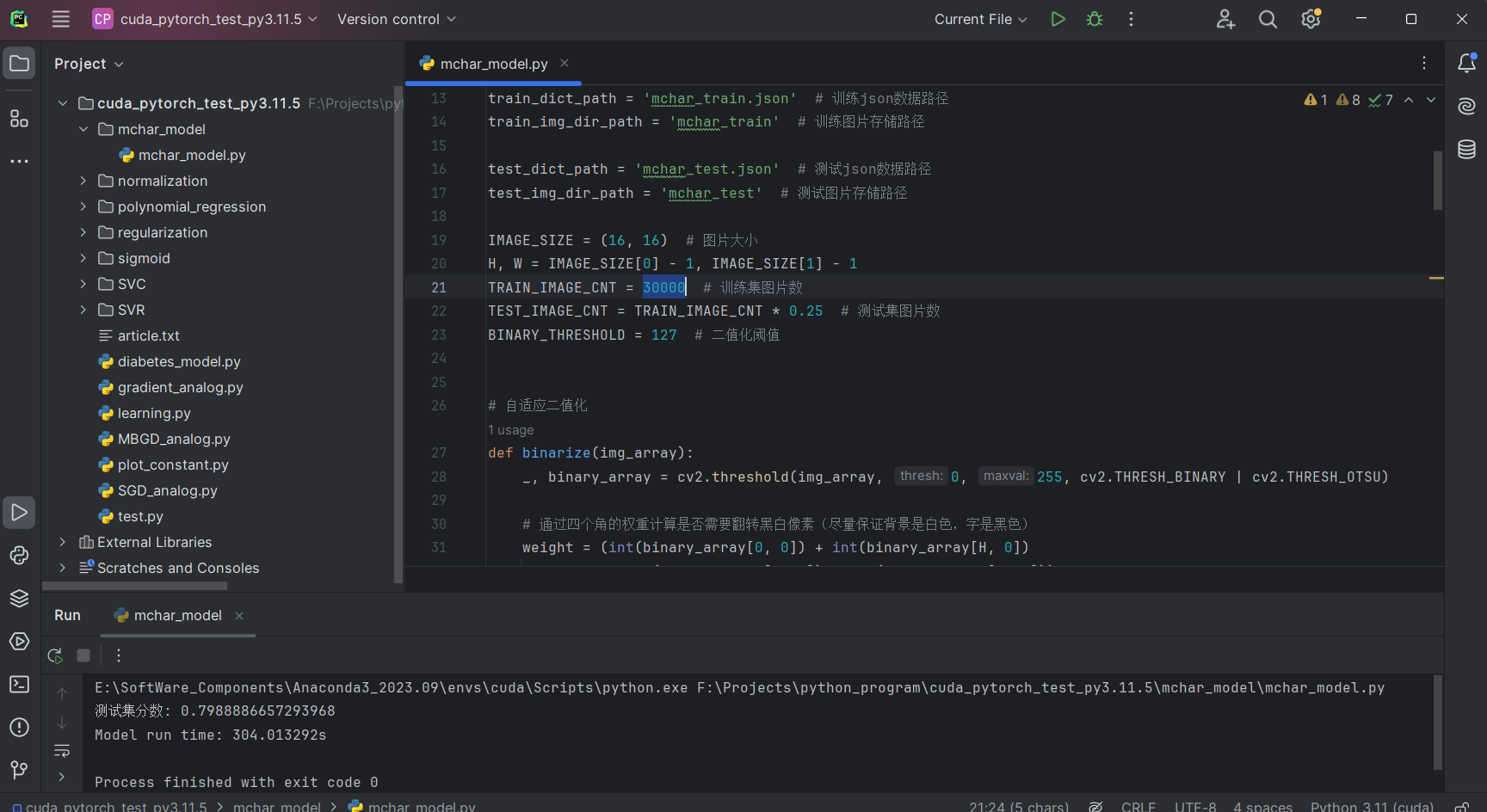
固定C为5.3,训练数据TRAIN_IMAGE_CNT = 30000,训练模型并使用测试集进行评分
Full Code
import os
import time
import json
import numpy as np
import cv2
from PIL import Image
from sklearn.decomposition import PCA
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
file_dir = 'G:\\dataset\\mchar\\' # 数据集路径
train_dict_path = 'mchar_train.json' # 训练json数据路径
train_img_dir_path = 'mchar_train' # 训练图片存储路径
test_dict_path = 'mchar_test.json' # 测试json数据路径
test_img_dir_path = 'mchar_test' # 测试图片存储路径
IMAGE_SIZE = (16, 16) # 训练图片大小
H, W = IMAGE_SIZE[0] - 1, IMAGE_SIZE[1] - 1
TRAIN_IMAGE_CNT = 30000 # 训练集图片数
TEST_IMAGE_CNT = TRAIN_IMAGE_CNT * 0.25 # 测试集图片数
# 自适应二值化
def binarize(img_array):
_, binary_array = cv2.threshold(img_array, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)
# 通过四个角的权重计算是否需要翻转黑白像素(尽量保证背景是白色,字是黑色)
weight = (int(binary_array[0, 0]) + int(binary_array[H, 0])
+ int(binary_array[0, W]) + int(binary_array[H, W]))
if weight < 510:
cond = (binary_array == 0)
binary_array[...] = 0
binary_array[cond] = 255
binary_array = binary_array.astype(np.uint8)
# debug
# binary_img = Image.fromarray(binary_array) # debug输出二值化后的图片
# binary_img.show()
return binary_array
# 图片转灰度图,裁剪图片内的数字,拉伸为16x16矩阵,返回裁剪后的像素列表
def crop_number(img, info):
img_gray = img.convert('L') # 转换为灰度图像
sz = len(info['label'])
X_clip = np.array([])
y_clip = np.array(info['label'])
for i in range(sz):
img_clip = img_gray.crop((info['left'][i], info['top'][i],
info['left'][i] + info['width'][i],
info['top'][i] + info['height'][i]))
img_clip = img_clip.resize(IMAGE_SIZE, Image.NEAREST)
pixel_array = binarize(np.array(img_clip))
pixel_array = pixel_array.flatten()
X_clip = np.append(X_clip, pixel_array)
return X_clip, y_clip
def get_json_dict(filepath):
with open(file_dir + filepath, 'r', encoding='utf-8') as json_file:
# 将JSON文件的内容加载到字典中
data = json.load(json_file)
return data
def get_data(dir_path, info_dict, image_cnt):
X = np.array([])
y = np.array([])
image_extensions = ['.jpg', '.jpeg', '.png', '.gif', '.bmp', '.tiff']
# 遍历dir_path下的所有文件
for root, dirs, files in os.walk(file_dir + dir_path):
for file in files:
# 检查文件扩展名是否是图片格式
if any(file.lower().endswith(ext) for ext in image_extensions):
full_path = os.path.join(root, file)
file_name = os.path.basename(full_path)
img = Image.open(full_path)
X_clip, y_clip = crop_number(img, info_dict[file_name])
X = np.append(X, X_clip)
y = np.append(y, y_clip)
image_cnt -= 1
if image_cnt <= 0:
break
X = X.reshape(-1, IMAGE_SIZE[0] * IMAGE_SIZE[1])
return X, y
def decline_features(x_train, x_test):
pca = PCA(n_components=0.95)
x_train_pca = pca.fit_transform(x_train)
x_test_pca = pca.transform(x_test)
return x_train_pca, x_test_pca
train_info_dict = get_json_dict(train_dict_path)
test_info_dict = get_json_dict(test_dict_path)
X_train, y_train = get_data(train_img_dir_path, train_info_dict, TRAIN_IMAGE_CNT)
X_test, y_test = get_data(test_img_dir_path, test_info_dict, TEST_IMAGE_CNT)
X_train_pca, X_test_pca = decline_features(X_train, X_test)
start_time = time.time()
def once_train(param_C):
svc = SVC(kernel='rbf', C=param_C)
return svc
# 获取最佳C值
def get_best_C():
svc = SVC()
param_grid = {'C': np.linspace(5, 20, 100), 'kernel': ['rbf']}
# param_grid = {'C': np.arange(5, 20), 'kernel': ['rbf']}
grid_search = GridSearchCV(estimator=svc, param_grid=param_grid, cv=5, scoring='accuracy')
grid_search.fit(X_train_pca, y_train)
print("最佳C值:", grid_search.best_params_['C'])
print("最佳分数:", grid_search.best_score_)
best_svc = SVC(C=grid_search.best_params_['C'], kernel='rbf')
return best_svc
model = once_train(5.3)
# model = get_best_C()
model.fit(X_train_pca, y_train)
end_time = time.time()
print("测试集分数:", model.score(X_test_pca, y_test))
print(f"Model run time: {(end_time - start_time):.6f}s")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号