[AI优化算法] —— 正则化 (L1、L2、Elastic Net正则化的入门应用)
简介
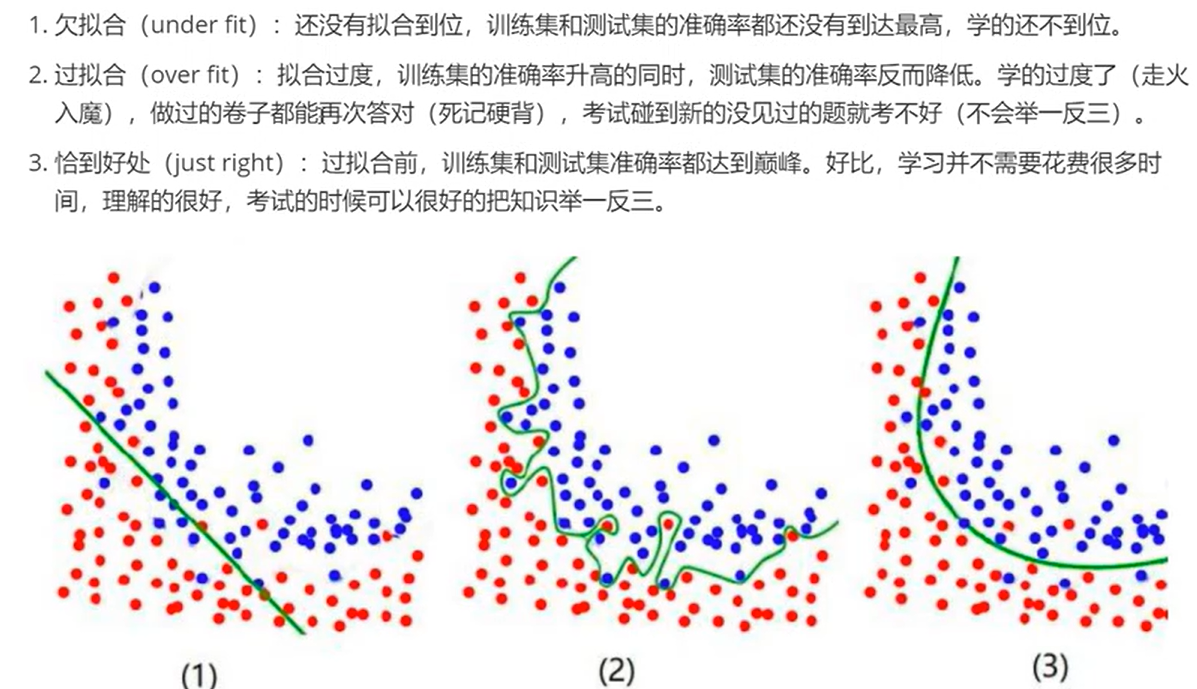
过拟合和欠拟合
欠拟合:模型在训练数据上表现不佳,未能捕捉数据的基本规律。
过拟合:模型在训练数据上表现极佳,但在新数据上泛化能力差。在模型中的具体表现往往是拟合曲线过度陡峭,即模型的斜率 \(\Theta\) 的绝对值太大。
例如,\(M1 = y = 10x + 10\) 与 \(M2 = y = x + 100\) 是对同一个数据集的两个不同的拟合模型,那么,\(M1\) 更可能出现过拟合的情况,因为 \(|\Theta|\) 更大,\(x\) 的轻微扰动对其拟合方向的影响将更大。
正则化
正则化是机器学习中用于防止模型过拟合的一种技术。正则化通过在模型的损失函数中添加一个额外的项来实现,这个额外的项通常与模型参数的大小有关。
三种常见的正则化
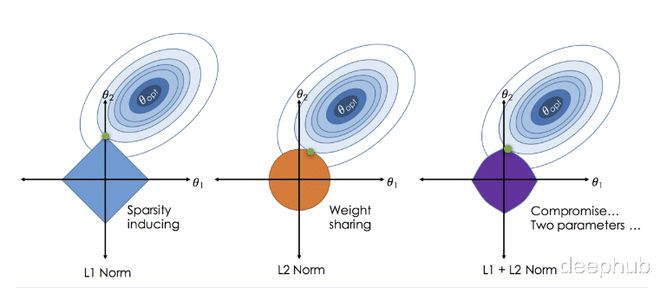
L1 正则化(Lasso 正则化)
\(J(\omega) = L(\omega) + \lambda \sum_{j=1}^{p} |\omega_{j}|\)
- \(J(\omega)\):损失函数
- $ L(\omega)$: 原始损失
- \(\lambda\): 正则化参数
- \(\omega_{j}\): 模型参数
L1 正则化通过在损失函数中添加参数的绝对值之和来实现正则化。
由于其在几何图像上表现为棱角突出的多边形,损失函数往往与其棱角相交,而棱角恰好是某些特征的参数为0的点。
因此,其主要作用是能够使得一些参数变为零,从而实现特征选择,得到一个稀疏的模型。这对于处理高维数据和特征分析非常有用。
优点:能够产生稀疏的模型,有助于特征选择。
缺点:由于其非连续性和非光滑性,在优化过程中可能更复杂,因为其正则化项在权重为零的地方不可微。这可能导致优化算法在这些点上难以收敛或者需要特别处理。
L2 正则化(Ridge 正则化)
\(J(\omega) = L(\omega) + \lambda \sum_{j=1}^{p} \omega_{j}^{2}\)
- \(J(\omega)\):损失函数
- $ L(\omega)$: 原始损失
- \(\lambda\): 正则化参数
- \(\omega_{j}\): 模型参数
L2 正则化在损失函数中添加参数的平方和。二维L2在空间中表现为以原点 \(O\) 为圆心的圆,它倾向于使参数值变小,但不会使其为零。
优点:L2正则化由于其连续性和光滑性,通常在优化时更加稳定和容易。L2正则化项是可微的,这使得使用梯度下降等标准优化算法时计算更加直接和高效。
缺点:不会产生稀疏解,没有特征选择性质。
弹性网络正则化(Elastic Net 正则化)
\(J(\omega) = L(\omega) + \rho\lambda \sum_{j=1}^{p} |\omega_{j}| + (1 - \rho)\lambda \sum_{j=1}^{p} \omega_{j}^{2}\)
- \(J(\omega)\):损失函数
- $ L(\omega)$: 原始损失
- \(\rho\): 介于\([0, 1]\)的参数
- \(\lambda\): 正则化参数
- \(\omega_{j}\): 模型参数
弹性网络正则化是 L1 正则化和 L2 正则化的组合。它结合了 L1 正则化的特征选择能力和 L2 正则化的稳定性。
优点:综合了 L1 和 L2 的优点。
缺点:需要调整两个参数 λ 和 ρ 。
三种正则化的可视化表达
运行截图
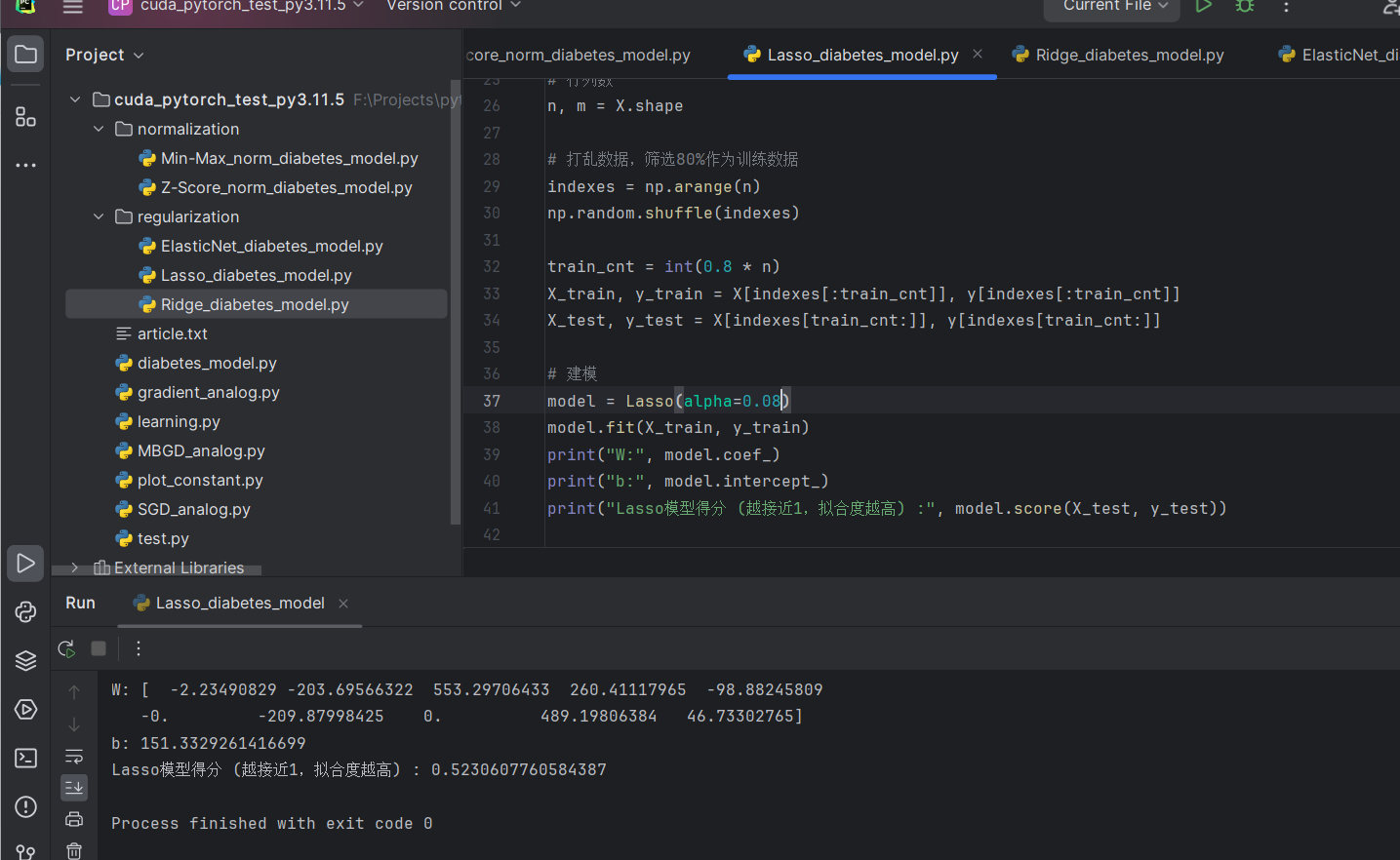
Lasso(套索回归)
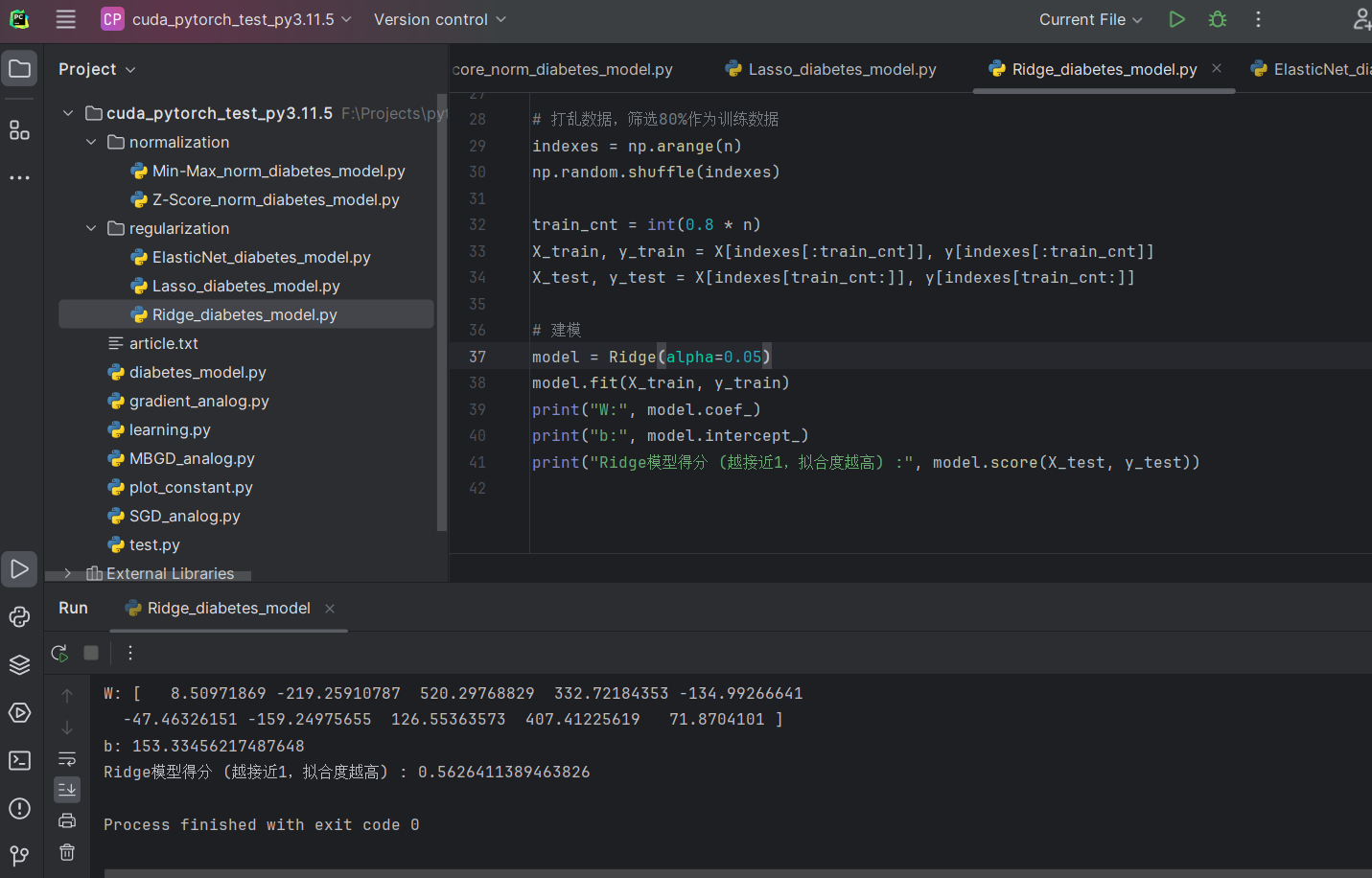
Ridge(岭回归)
Elastic Net(弹性网络回归)
Full Code
Lasso_diabetes_model.py
import numpy as np
from sklearn import datasets
from sklearn.linear_model import Lasso
diabetes = datasets.load_diabetes()
'''
age: 年龄(以年为单位)
sex: 性别
bmi: 体重指数(Body Mass Index)
bp: 平均血压(Blood Pressure)
s1: 总血清胆固醇(Total Serum Cholesterol,tc)
s2: 低密度脂蛋白(Low-Density Lipoproteins,ldl)
s3: 高密度脂蛋白(High-Density Lipoproteins,hdl)
s4: 总胆固醇与高密度脂蛋白的比值(Total Cholesterol / HDL,tch)
s5: 血清甘油三酯水平的可能对数值(Log of Serum Triglycerides Level,ltg)
s6: 血糖水平(Blood Sugar Level,glu)
'''
column_names = ['age', 'sex', 'bmi', 'bp', 's1', 's2', 's3', 's4', 's5', 's6']
X = diabetes.data # data
y = diabetes.target # target
# 行列数
n, m = X.shape
# 打乱数据,筛选80%作为训练数据
indexes = np.arange(n)
np.random.shuffle(indexes)
train_cnt = int(0.8 * n)
X_train, y_train = X[indexes[:train_cnt]], y[indexes[:train_cnt]]
X_test, y_test = X[indexes[train_cnt:]], y[indexes[train_cnt:]]
# 建模
model = Lasso(alpha=0.08)
model.fit(X_train, y_train)
print("W:", model.coef_)
print("b:", model.intercept_)
print("Lasso模型得分 (越接近1,拟合度越高) :", model.score(X_test, y_test))
Ridge_diabetes_model.py
import numpy as np
from sklearn import datasets
from sklearn.linear_model import Ridge
diabetes = datasets.load_diabetes()
'''
age: 年龄(以年为单位)
sex: 性别
bmi: 体重指数(Body Mass Index)
bp: 平均血压(Blood Pressure)
s1: 总血清胆固醇(Total Serum Cholesterol,tc)
s2: 低密度脂蛋白(Low-Density Lipoproteins,ldl)
s3: 高密度脂蛋白(High-Density Lipoproteins,hdl)
s4: 总胆固醇与高密度脂蛋白的比值(Total Cholesterol / HDL,tch)
s5: 血清甘油三酯水平的可能对数值(Log of Serum Triglycerides Level,ltg)
s6: 血糖水平(Blood Sugar Level,glu)
'''
column_names = ['age', 'sex', 'bmi', 'bp', 's1', 's2', 's3', 's4', 's5', 's6']
X = diabetes.data # data
y = diabetes.target # target
# 行列数
n, m = X.shape
# 打乱数据,筛选80%作为训练数据
indexes = np.arange(n)
np.random.shuffle(indexes)
train_cnt = int(0.8 * n)
X_train, y_train = X[indexes[:train_cnt]], y[indexes[:train_cnt]]
X_test, y_test = X[indexes[train_cnt:]], y[indexes[train_cnt:]]
# 建模
model = Ridge(alpha=0.05)
model.fit(X_train, y_train)
print("W:", model.coef_)
print("b:", model.intercept_)
print("Ridge模型得分 (越接近1,拟合度越高) :", model.score(X_test, y_test))
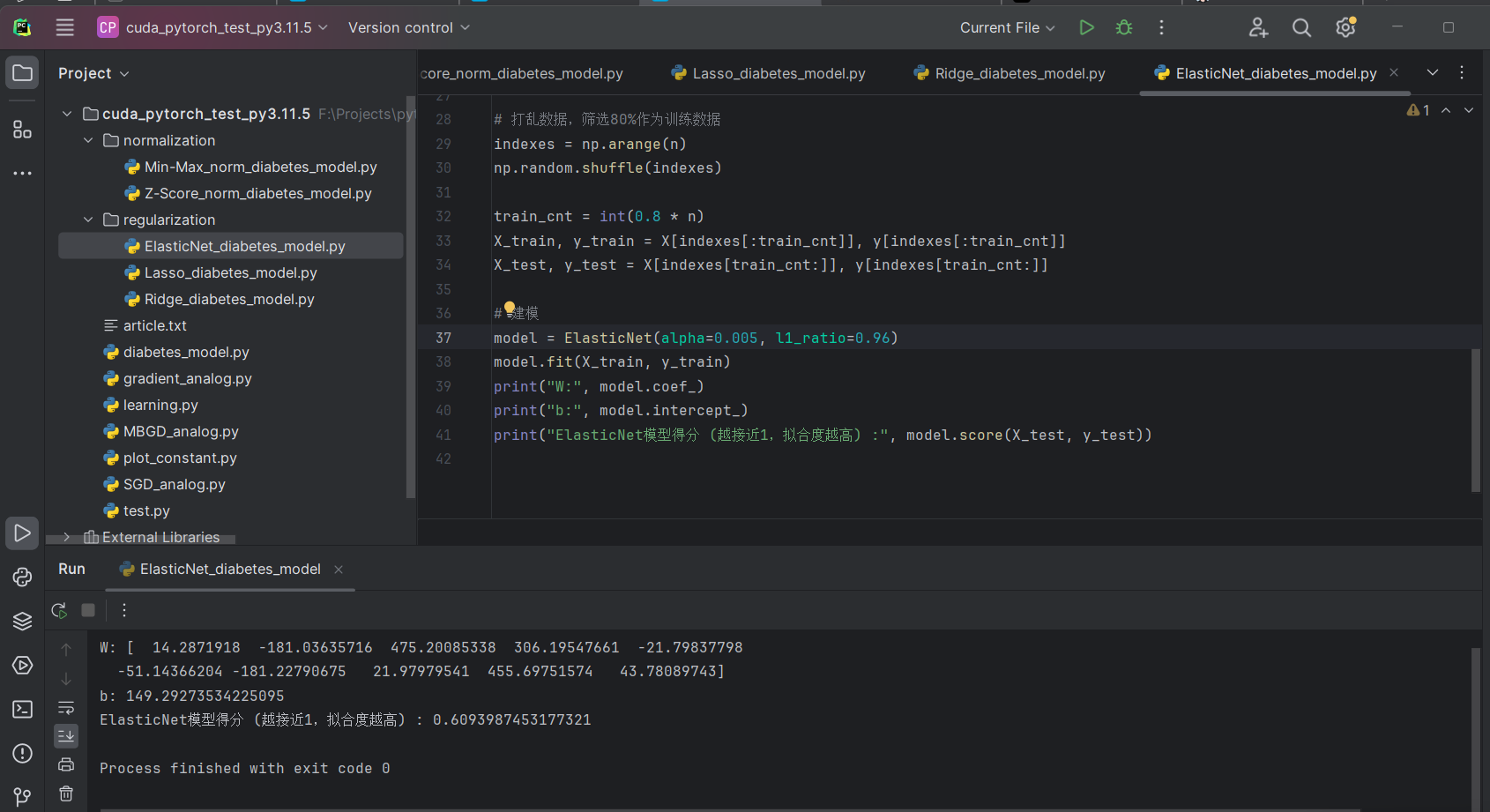
ElasticNet_diabetes_model.py
import numpy as np
from sklearn import datasets
from sklearn.linear_model import ElasticNet
diabetes = datasets.load_diabetes()
'''
age: 年龄(以年为单位)
sex: 性别
bmi: 体重指数(Body Mass Index)
bp: 平均血压(Blood Pressure)
s1: 总血清胆固醇(Total Serum Cholesterol,tc)
s2: 低密度脂蛋白(Low-Density Lipoproteins,ldl)
s3: 高密度脂蛋白(High-Density Lipoproteins,hdl)
s4: 总胆固醇与高密度脂蛋白的比值(Total Cholesterol / HDL,tch)
s5: 血清甘油三酯水平的可能对数值(Log of Serum Triglycerides Level,ltg)
s6: 血糖水平(Blood Sugar Level,glu)
'''
column_names = ['age', 'sex', 'bmi', 'bp', 's1', 's2', 's3', 's4', 's5', 's6']
X = diabetes.data # data
y = diabetes.target # target
# 行列数
n, m = X.shape
# 打乱数据,筛选80%作为训练数据
indexes = np.arange(n)
np.random.shuffle(indexes)
train_cnt = int(0.8 * n)
X_train, y_train = X[indexes[:train_cnt]], y[indexes[:train_cnt]]
X_test, y_test = X[indexes[train_cnt:]], y[indexes[train_cnt:]]
# 建模
model = ElasticNet(alpha=0.005, l1_ratio=0.96)
model.fit(X_train, y_train)
print("W:", model.coef_)
print("b:", model.intercept_)
print("ElasticNet模型得分 (越接近1,拟合度越高) :", model.score(X_test, y_test))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号