[AI优化算法] —— 归一化 (Min-Max、Z-Score算法的入门应用)
简介
归一化
归一化(Normalization) 是机器学习中常用的一种数据预处理技术,其主要目的是将数据的数值范围调整到一个特定的区间,通常是\([0, 1]\)或者\([-1, 1]\),或者将数据的均值调整为0,标准差调整为1。
归一化的目的
数据集的不同特征可能采用不同或不相关的数量级进行标注,其数值范围差异往往很大。
例如,一个数据集包含身高和体重,其中,身高以米为单位,范围是 \([1, 2]\),体重以千克为单位,范围是\([40, 150]\)。在没有归一化的情况下,数值范围大的特征在模型中的影响会更大,本例中,体重的数值远大于身高,这可能会导致梯度下降方程对体重敏感,训练得到的模型也更偏向于体重。
归一化的目的是,使数量级不同的不同维度 \(\Theta\) ,可以步调一致协同的进行梯度下降,从而避免某些维度梯度下降速度过快或过慢。
常见的归一化算法
Min-Max 归一化
Min-Max归一化可以将数据的数值范围调整到[0, 1]区间,样本中的最大值为1,最小值为0,其他数据以此为参照进行线性缩放。
\(X_{norm} = \frac{x - x_{min}}{x_{max} - x_{min}}\),其中 \(x\) 是原始数据值,\(x_{min}\) 是数据集中的最小值,\(x_{max}\) 是数据集中的最大值。
sklearn库为我们提供了便捷的Min-Max标准化工具,代码如下:
# 对数据进行Min-Max归一化
from sklearn.preprocessing import MinMaxScaler
mms = MinMaxScaler()
mms.fit(X)
X = mms.transform(X)
Z-Score 标准化
Z-Score归一化通过减去均值后除以标准差来实现,使得数据的均值为0,标准差为1,即呈现以0为轴的,标准差为1的正态分布。
\(X_{std} = \frac{x - \mu}{\sigma}\),其中 \(x\) 是原始数据值,\(\mu\) 是数据的均值,\(\sigma\) 是数据的标准差。
sklearn库同样为我们提供了Z-Score标准化工具,代码如下:
# 对数据进行Z-Score归一化
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(X)
X = ss.transform(X)
运行截图
未进行归一化操作
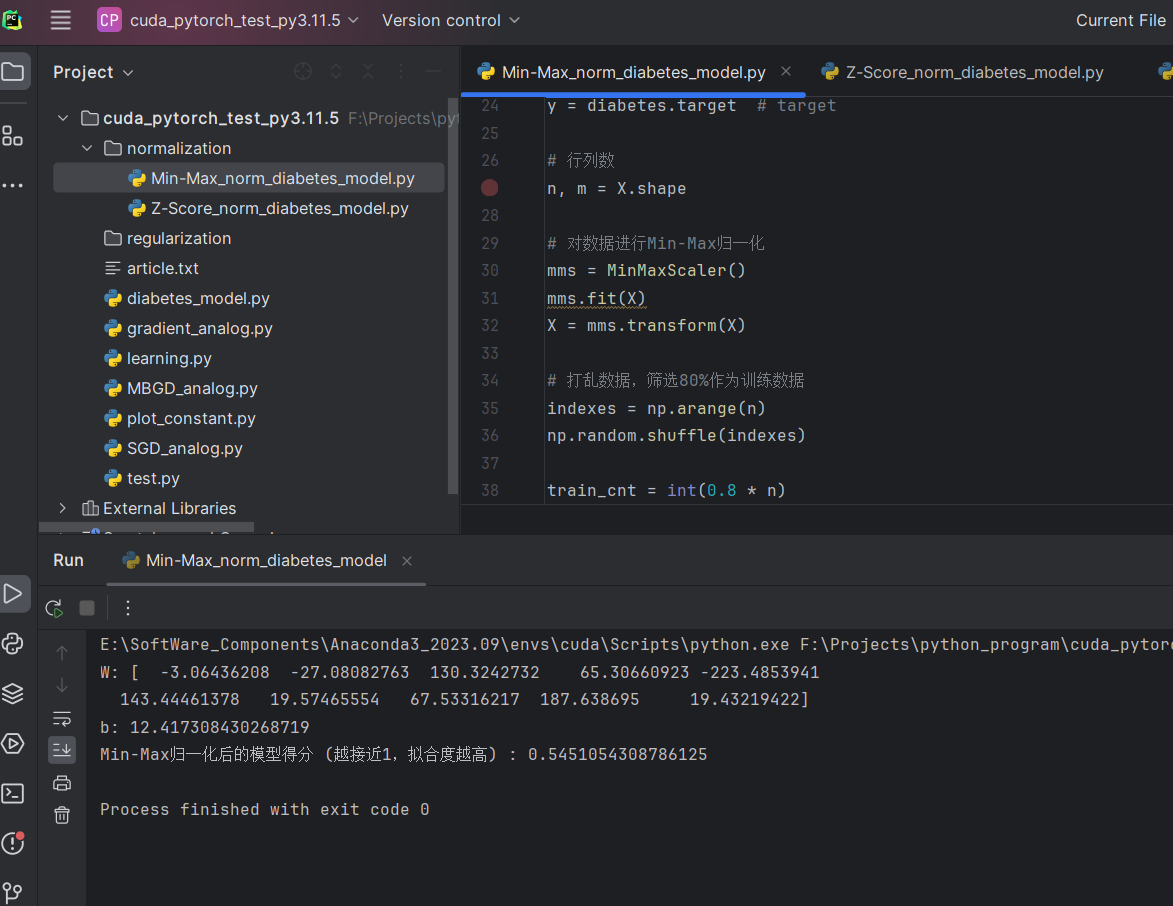
Min-Max归一化
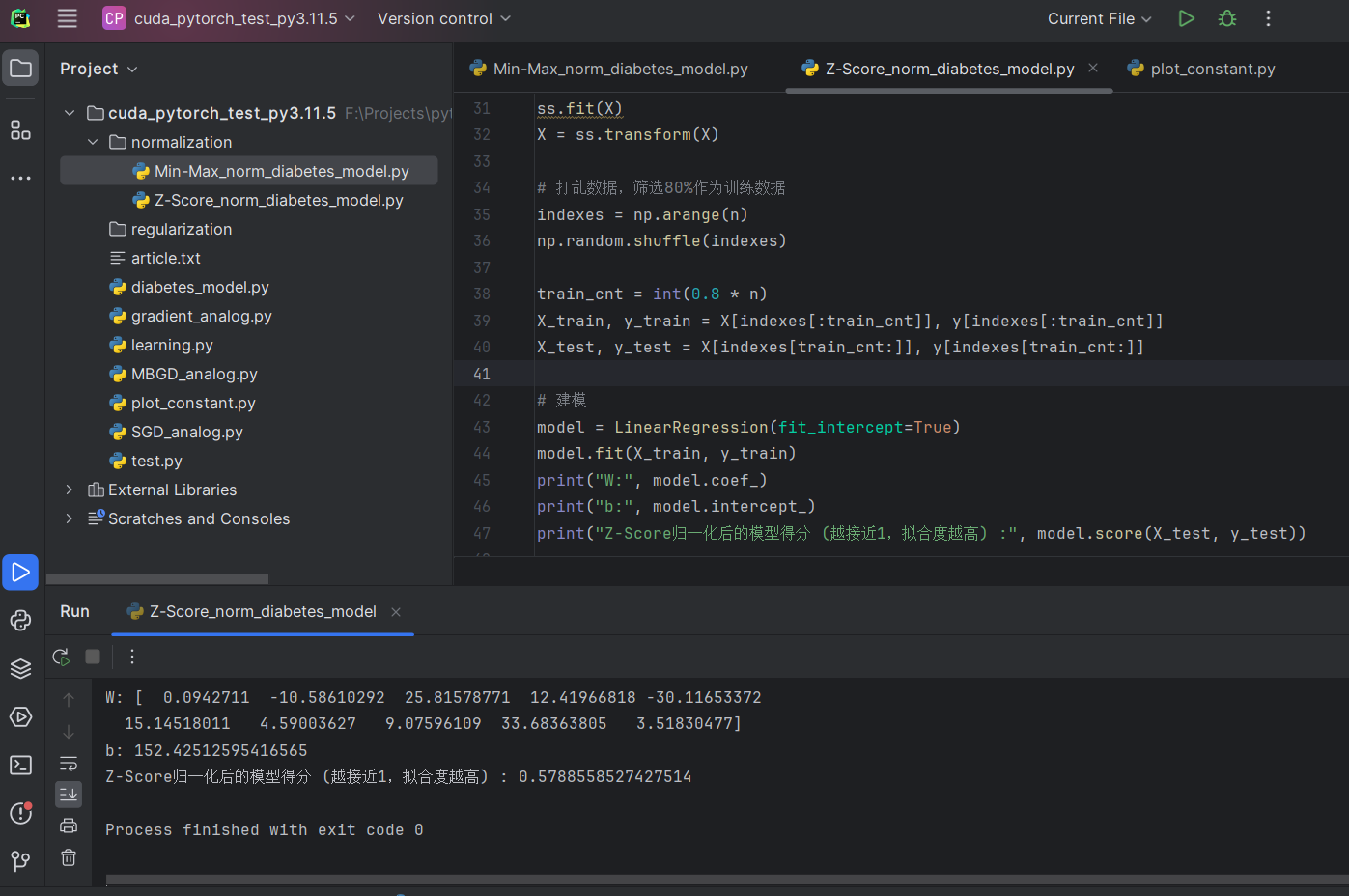
Z-Score归一化
Full Code
Min-Max_norm_diabetes_model.py
import numpy as np
from sklearn import datasets
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import MinMaxScaler
diabetes = datasets.load_diabetes()
'''
age: 年龄(以年为单位)
sex: 性别
bmi: 体重指数(Body Mass Index)
bp: 平均血压(Blood Pressure)
s1: 总血清胆固醇(Total Serum Cholesterol,tc)
s2: 低密度脂蛋白(Low-Density Lipoproteins,ldl)
s3: 高密度脂蛋白(High-Density Lipoproteins,hdl)
s4: 总胆固醇与高密度脂蛋白的比值(Total Cholesterol / HDL,tch)
s5: 血清甘油三酯水平的可能对数值(Log of Serum Triglycerides Level,ltg)
s6: 血糖水平(Blood Sugar Level,glu)
'''
column_names = ['age', 'sex', 'bmi', 'bp', 's1', 's2', 's3', 's4', 's5', 's6']
X = diabetes.data # data
y = diabetes.target # target
# 行列数
n, m = X.shape
# 对数据进行Min-Max归一化
mms = MinMaxScaler()
mms.fit(X)
X = mms.transform(X)
# 打乱数据,筛选80%作为训练数据
indexes = np.arange(n)
np.random.shuffle(indexes)
train_cnt = int(0.8 * n)
X_train, y_train = X[indexes[:train_cnt]], y[indexes[:train_cnt]]
X_test, y_test = X[indexes[train_cnt:]], y[indexes[train_cnt:]]
# 建模
model = LinearRegression(fit_intercept=True)
model.fit(X_train, y_train)
print("W:", model.coef_)
print("b:", model.intercept_)
print("Min-Max归一化后的模型得分 (越接近1,拟合度越高) :", model.score(X_test, y_test))
Z-Score_norm_diabetes_model.py
import numpy as np
from sklearn import datasets
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
diabetes = datasets.load_diabetes()
'''
age: 年龄(以年为单位)
sex: 性别
bmi: 体重指数(Body Mass Index)
bp: 平均血压(Blood Pressure)
s1: 总血清胆固醇(Total Serum Cholesterol,tc)
s2: 低密度脂蛋白(Low-Density Lipoproteins,ldl)
s3: 高密度脂蛋白(High-Density Lipoproteins,hdl)
s4: 总胆固醇与高密度脂蛋白的比值(Total Cholesterol / HDL,tch)
s5: 血清甘油三酯水平的可能对数值(Log of Serum Triglycerides Level,ltg)
s6: 血糖水平(Blood Sugar Level,glu)
'''
column_names = ['age', 'sex', 'bmi', 'bp', 's1', 's2', 's3', 's4', 's5', 's6']
X = diabetes.data # data
y = diabetes.target # target
# 行列数
n, m = X.shape
# 对数据进行Z-Score归一化
ss = StandardScaler()
ss.fit(X)
X = ss.transform(X)
# 打乱数据,筛选80%作为训练数据
indexes = np.arange(n)
np.random.shuffle(indexes)
train_cnt = int(0.8 * n)
X_train, y_train = X[indexes[:train_cnt]], y[indexes[:train_cnt]]
X_test, y_test = X[indexes[train_cnt:]], y[indexes[train_cnt:]]
# 建模
model = LinearRegression(fit_intercept=True)
model.fit(X_train, y_train)
print("W:", model.coef_)
print("b:", model.intercept_)
print("Z-Score归一化后的模型得分 (越接近1,拟合度越高) :", model.score(X_test, y_test))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号