论文笔记系列-AutoFPN
论文笔记系列-AutoFPN
原论文:Auto-FPN: Automatic Network Architecture Adaptation for Object Detection
Beyond Classification
之前的AutoML都是应用在图像分类或者语言模型上,AutoFPN成功地将这技术应用到了目标检测任务上。
一、传统two-stage目标检测网络结构
在介绍AutoFPN之前,首先大致介绍一下two-stage目标检测网络的结构组成。
- backbone:即用来提取图像特征的网络结构,常用ResNet或VGG来提取特征
- RPN(region proposal networks): 这个网络的作用是在backbone提取得到的特征的基础上进一步预测出若干个区域,比如faster-rcnn可能会生成2000个proposals,这些proposals中可能存在错误的或者存在些许偏差的,所以还需要进一步由后面的网络处理
- RCNN (region CNN) head: 简单理解就是针对生成的proposal区域做进一步的分类和位置回归。
二、AutoFPN
AutoFPN的创新点在后面两个网络中,如下图示,主要是针对backbone的特征先做自动fusion操作(Auto-fusion),另外就是对head网络使用NAS技术搜索得到一个网络用于分类和回归(Auto-head)。

1. Auto-fusion
Auto-fusion其实是基于之前的一些工作的改进,如下图示:
- 最开始SSD会对不同尺度的特征图做预测
- 之后FPN提出了自上而下的连接方式,将不同尺度的特征图信息进行结合
- PANet通过直接将最底层的特征与最高层的特征图进行连接,进一步增强特征图之间的联系
- Auto-fusion则是通过搜索网络结构来让算法自动找到不同层之间最合适的连接方式。

Auto-fusion搜索方法设计考虑的有如下两个方面:
- 搜索空间覆盖所有的连接方式
- 因为在TridenNet中使用dilated conv得到了不错的效果,所以不同大小的dilated conv加入到了搜索空间中去。搜索空间如下:
- no connection (none)
- skip connection (identity)
- 3×3 dilated conv with rate 2
- 5×5 dilated conv with rate 2
- 3×3 dilated conv with rate 3
- 5×5 dilated conv with rate 3
- 3×3 depthwise-separable conv
- 5×5 depthwise-separable conv
下面结合上图介绍Auto-fusion结构的表示方式。
对于backbone提取的4个特征图我们用 表示,
表示, 表示第0层的第4个特征图,其高宽都比原图的小4倍。那么如果Auto-fusion结构一共有
表示第0层的第4个特征图,其高宽都比原图的小4倍。那么如果Auto-fusion结构一共有 层,则第
层,则第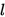 层的特征图可表示为
层的特征图可表示为 。第
。第 层的
层的 节点到第
节点到第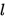 层的
层的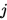 节点的operation可表示为(这里如果不明白先了解一下DARTS这篇论文):
节点的operation可表示为(这里如果不明白先了解一下DARTS这篇论文):

下图给出了Auto-fusion某一层的示意图,可以看到因为要使得不同尺度的特征图能做融合操作,首先都会用conv 1*1的操作,而后再计算不同operation的权重。

Auto-fusion对于one-stage和two-stage目标检测网络都适用。
2. Auto-head
Auto-head其实简单理解就是和DARTS一样搜索得到一个CNN结构,示意图如下

不过有如下几个方面作了修改,有必要提一下:
- Auto-head由
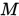 个cell组成,每个cell由7个nodes组成。每个cell有两个inputs,分别是前一个和前前一个cell的outputs。
个cell组成,每个cell由7个nodes组成。每个cell有两个inputs,分别是前一个和前前一个cell的outputs。 - 在DARTS中,最后有两类cell,分别是normal cell和reduction cell。而在Auto-head中每个cell的结构可以不一样,也就是说Auto-head可以由
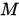 个不同的cell组成
个不同的cell组成 - Auto-head中没有使用reduction cell,因为到了这一步特征图大小已经很小了(如7*7)
- 同上,涉及到卷积的操作也不用dilated conv了,但是为了更好地提取特征,在每个operation后面还会加上3*3和5*5的卷积操作。
3. Resource constraint
AutoFPN还加入了资源约束,这样既可以避免生成的模型过大,也能够加速搜索和训练过程。很直观的一种想法是将forward时间作为约束条件,但是测得的forward时间相对于模型参数并不是可微的,所以考虑如下三个方面来对资源约束建模:
- 模型大小
- FLOPs
- memory access cost (MAC)
公示表示如下:
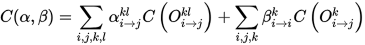
那么总的loss表达式如下:
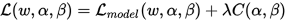
其中 表示模型参数,即我们常说的卷积核参数或者全连接层参数等,
表示模型参数,即我们常说的卷积核参数或者全连接层参数等, 表示模型结构参数,即记录了不同operation的权重。值得一提的是
表示模型结构参数,即记录了不同operation的权重。值得一提的是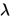 这个参数,因为通过修改这个参数的大小,我们能够控制模型的相对大小,例如如果我们令
这个参数,因为通过修改这个参数的大小,我们能够控制模型的相对大小,例如如果我们令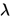 比较大,那么最终得到的网络大小就会相对小一些,反之则大一些。在论文中,给出了三个等级的效果,具体结果看下一节。
比较大,那么最终得到的网络大小就会相对小一些,反之则大一些。在论文中,给出了三个等级的效果,具体结果看下一节。
三、实验结果
1. Auto-fusion和Auto-head搜索结果
下图给出了Auto-fusion和Auto-head搜索结果,可以看到identity和conv_5*5在两个结构中用的最多。

2. 不同大小模型的结果对比
按照文中的说法是分别Auto-fusion和Auto-head是分别进行搜索的,所以最后的AutoFPN是将二者最好的结果进行组合得到的。可以看到在不同的数据集上搜索得到的网络结构更小,而且结果也能更好。
不过我看这结果有几个疑问,就是结果的提升到底算不算显著呢?结构的提升有多少其实是炼丹炼出来而不是搜网络结构搜出来的呢?ε=(´ο`*)))唉


3. NAS baseline比较结果
最后文中还给出了不同搜索策略的结果对比,可以看到基于梯度下降的效果还是很不错的。

4. 训练tricks大放送
作者很良心给出了5个训练技巧:
- 先训练初始化结构一段时间,然后再开始搜索网络结构:Starting optimizing architecture parameters in the middle of training can improve the results by 1%;
- 在搜索阶段固定backbone参数:Freezing the backbone parameters during searching not only accelerates the training but also improves the performance;
- 搜错阶段不要用BN:Searching with BN will decrease the performance by 1.7%;
- 在搜索head结构时,最好使用训练好的neck结构:During searching for the head, loading the pretrained neck will boost the performance by 2.9%;
- 大模型对neck部分性能有些许提升,但是对head好像并没有:Without resource constraints, our method becomes larger with only a small im- provement in neck but no improvement in head.

