论文笔记系列-Neural Network Search :A Survey
论文笔记系列-Neural Network Search :A Survey
注:本文主要是结合自己理解对原文献的总结翻译,有的部分直接翻译成英文不太好理解,所以查阅原文会更直观更好理解。
本文主要就Search Space、Search Strategy、Performance Estimation Strategy三个方面对Neural Network Search(NAS)的发展进行了阐述。
Search Space用来定义网络的表达形式,而Search Strategy则根据定义以及一定的策略构建出某种模型,然后Performance Estimation Strategy将对生成的模型进行判断,然后将判断的结果反馈给Search Strategy,Search Strategy根据反馈重新生成模型,以此迭代下去直到找到满足要求的模型结构,三者的关系如下图所示。

1. Search Space
Search Space就是指需要寻找的Network该以何种形式表达。下面分别介绍都具有哪些表达方式。
1.1 chain-structured neural network
比较简单的Space是链式结构的神经网络(chain-structured neural network),这种结构也就是常见的神经网络结构,就如同搭积木一般,越搭越深。这种Space主要有以下结构组成:
- 最大的层数
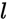 (当然也可能没有限制)
(当然也可能没有限制) - 每层执行的操作(operation),如Pooling,convolution,depthwise separable Convolution,或者dilated convolution
- 与每层所执行的operation相关的超参数,如filter size, filter num等
1.2 cell-structured neural network
如今NAS寻找模型的方法很多都借鉴了人类构建模型(如Residual Network,DenseNet)的思路。
还有的人为设计的模型采取的策略是重复一些motifs,受到这一做法的启发,Zoph et al.(2018) Zhong et al.(2018a) 将那些重复的motif称为cells或者blocks,所以模型搜索就简化成了对这些cell的搜索。。
Zoph et al.(2018)将cell划分成两类:normal cell用来保存输入的维度,reduction cell用于降低空间维度。最终的示意图如下:

相比于直接搜索整体网络结构,搜索cell有两个好处:一是搜索空间可以小很多,二是搜索得到cell能够很容易迁移到其他数据集,例如 Zoph et al.(2018)就将运用在CIFAR10上的cell迁移到了ImageNet上,而且表现不凡。
当然虽然cell找到了,但是网络还是没有搭建起来,所以关于如何将找到的这些cell结合构建得到网络涉及两个问题:一是cell数量如何确定,二是cell连接方式如何选择。
上述的两个问题是个值得思考的方向。另外基于cell的网络构建方式存在这些问题:一是网络是不连续的,二是得到的网络结构参数相对来说是高维的,因为要想表现更佳,一般而言网络就需要构建的更加复杂,因此设计网络时的选择也就更多。
2. Search Strategy
搜索策略主要包括以下方法:random search(RS)、Bayesian optimization、evolutionary methods、reinforcement learning(RL)、gradient-based methods。
进化算法在几十年前就已经用来进化神经网络了,(Evolving artificial neural network)对2000年以前的进化算法做了literature review,可以参考查阅。
2.1 Bayesian optimization
Bayesian Optimization(BO)是超参数优化最受欢迎的算法之一,但是因为典型的BO toolboxes都是基于高斯过程,并且主要关注于低维连续优化问题,所以在NAS上没有应用。直到2013年,开始有了一些动作,Swersky et al.使用GP-based的BO算法来推导出用于搜索网络结构的核函数,但是迄今为止都没能找到state-of-the-art的模型。相反一些使用tree-based模型的方法,例如使用treed Parzen estimators的Bergstra et al. 2011,以及使用随机森林的Hutter et al. 2011等都成功地在一系列问题上找到了高维条件空间并且取得了最优的表现
BO自从2013年开始在NAS领域取得早期的成功,如(Bergstra et al. 2013)得到了最先进的视觉模型,(Domhan et al. 2015)所构建的模型在CIFAR10(没有data augmentation)上取得了最好成绩,(Mendoza et al. 2016)是第一个自动化调参的神经网络模型,并且在与人类专家比赛中获得胜利。
2.2 Reinforcement Learning
Zoph and Le ,2017使用一个RNN结构来作为policy(或者称为search strategy),然后根据生成的模型在测试集上的表现,结合RL技术对生成的模型进行奖励或者惩罚,最终在CIFAR10和Penn Treebank数据集上表现优异,是的NAS成为了一个火热的研究话题。但是他们的方法消耗了大量计算资源(800 GPUS跑了3到4个星期),所以为了提高计算效率,相继提出了很多算法。例如还是Zoph et al.等人在2018年使用Proximal Policy Optimization(PPO)。Baker et al. 2017a使用Q-learning来训练policy,这个policy适用于选择每层的类型以及对应参数。
因为policy选择每层执行的操作以及对应的超参数这一过程其实是一个顺序决策过程,而且reward是在最后一个action结束后获得,所以也可以将这一过程视为单个action的顺序生成过程,因此RL问题也简化成了无状态的多臂赌博机问题(stateless multi-armed bandit problem)。
Cai et al. 2018a提出了相关的方法,他们将NAS定义为一系列的决策过程:在他们的方法中
- state表示当前的架构
- reward表示对架构表现的评估
- action对应于一个function-preserving突变的应用,被称为network morphism(Chen et al. 2016,Wei et al. 2017),也可以简单地理解成下一个时刻(迭代)模型的参数
- policy简单理解就是用来生成action的部分
2.3 Neural Evolutionary
将进化算法用于优化神经结构的最早可追溯的是Miller et al. 1989,该篇论文使用genetic algorithm来生成结构,并使用反向传播算法优化权重。
自此很多neuro-evolutionary算法都同时用genetic algorithm来优化网络结构和权重。(Angeline et al., 1994; Stanley and Miikkulainen, 2002; Stanley et al., 2009)
然而,当扩展到具有数百万权值用于监督学习任务的现代神经结构时,基于sgd的权重优化方法目前的性能优于进化优化方法。所以近期的一些neuro-evolutionary算法 (如Real et al., 2017; Suganuma et al., 2017; Liu et al., 2018b; Real et al., 2018; Miikkulainen et al., 2017; Xie and Yuille, 2017; Elsken et al., 2018) 又重新使用进化算法来优化网络结构,使用gradient-based方法来优化权重。
Neuro-evolutionary methods可按如下分类:
- sample parent的方式
- Real et al., 2017;Liu et al., 2018b; Real et al., 2018等使用tournament selection(由Goldberg and Deb提出)来sample parents
- Elsken et al., 2018 sample parents from a multi-objective Pareto front using an iverse density
- update populations的方式
- Real et al., 2017 remove worst from population
- Real et al., 2018 remove oldest from population
- Liu et al., 2018b do not remove individual at all
- generate offsprings的方式
- randomly initialize
- Elsken et al., 2018应用拉马克式遗传(Lamarckian inheritance),即通过network morphism将父辈的知识传递给子辈,从而生成offsprings。
- Real et al., 2017也让offspring继承父辈的所有参数,其中这些父辈不受突变的影响。这一方法虽然并不是严格意义上的function-preserving(可以理解成保持父类模型的特性),但是相比于随机初始化,这个方法能加速学习。另外他们也会将学习率进行突变,这也可以视为在网络结构搜索中的一种优化学习率的方式。
2.4 Hierarchical manner
结构搜索空间也以分层的方式(Hierarchical manner)进行了探索,例如结合进化论(Liu et al., 2018b)或基于顺序模型的优化(Liu等人,2018 a)。
Negrinho and Gordon 2017 and Wistuba 2017开发了搜索空间的树状结构,并且使用Monte Carlo Tree Search。Elsken al et. 2017提出了一种简单但性能良好的爬山算法,通过贪婪地向更好的架构方向移动而不需要更复杂的探索机制来发现高质量的架构。
与上面的无梯度优化方法相比,Liu et al 2018c提出了搜索空间的连续松弛以实现基于梯度的优化:作者不再是在某一层上固定用来执行的单个操作,而是计算一组操作的凸组合。更确切地说,给定某一层的输入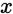 ,该层的输出
,该层的输出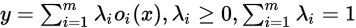 ,这里
,这里 能有效的参数化网络结构。之后通过梯度下降算法,在训练集上优化权重,在测试集上优化网络参数
能有效的参数化网络结构。之后通过梯度下降算法,在训练集上优化权重,在测试集上优化网络参数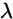 。最后对每一层采取如下计算
。最后对每一层采取如下计算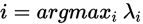 来选择该层的操作
来选择该层的操作 。
。
Shi et al. 2018和Ahmed and Torresani 2018也应用基于梯度下降的优化方法来进行结构搜索,但是前者只是考虑优化层的超参数,后者只是考虑连接模式(connectivity patterns)。
3. Performance Estimation Strategy
上面一节总结了网络结构搜索的策略,而找出网络后还需要使用一定的评判标准来评估网络性能,最简单的就是在训练集上训练网络模型,然后在验证集上评估性能。但是这种方法通常会消耗大量资源,因为每次在训练集上从头开始训练一个模型都是费时费力。
3.1 Lower fidelity
为了减少这种计算负担,可以根据充分训练后实际性能的较低保真度(lower fidelity)来估计性能(也称为代理度量)。这种较低的保真度包括更短的训练时间(Zoph等,2018; Zela等,2018),对数据子集的训练(Klein等,2017b),低分辨率图像(Chrabaszcz等, 2017),或每层使用较少的过滤器(Zoph et al.(2018); Real et al., 2018;)。 虽然这些低保真近似值降低了计算成本,但它们也会在估计中引入偏差,因为性能通常会被低估。 只要搜索策略仅依赖于对不同体系结构进行排名并且相对排名保持稳定,这可能不成问题。 然而,最近的结果表明,当廉价近似(cheap approximation)与“完全”评估(full evaluation)之间的差异太大时,这种相对排名会发生显着变化(Zela等,2018),认为保真度逐渐增加。
3.2 Curve Extrapolation
另一种评估架构性能的方法是基于学习曲线外推(curve extrapolation).
Domhan et al., 2015建议对初始学习曲线进行外推,并终止那些预测性能较差的曲线,以加快体系结构搜索过程。Swersky et al., 2014;Klein et al., 2017a; Baker et al., 2017b; Rawal and Miikkulainen, 2018也考虑了结构超参数来预测哪些部分学习曲线最有前途。Liu et al. 2018a还提出了一种预测新型体系结构性能的代理模型,他们不使用学习曲线外推法,但支持基于架构/单元属性的预测性能,并外推比训练中看到的更大的架构/单元。预测神经体系结构性能的主要挑战是,为了加快搜索过程,需要基于相对较少的评估,在相对较大的搜索空间中进行良好的预测。
3.3 Network Morphism
另一种加速性能评估的方法是根据以前训练过的其他架构的权重来初始化新架构的权重。其中一种可以实现这个的是Network Morphism(Wei et al. 2016)。这样就可以连续地提高网络的容量,并保持高性能,而无需从头开始进行训练。这些方法的优点是,它们允许搜索空间,而不受体系结构大小的固有上限限制。但是另一方面,严格的网络模式只能使体系结构变得更大,从而可能导致过于复杂的体系结构。这可以通过使用允许收缩体系结构的近似网络结构来减少架构大小(Elsken et al. 2018)。
3.4 One-Shot Architecture Search
One-Shot Architecture Search是加速性能评估的另一种很有效的方法,它将所有的体系结构视为一个Supergraph(One-Shot模型)的不同subgraph,并且在具有该Supergraph的相同边的体系结构之间共享权重(Saxena和Verbeek, 2016;Brock等人,2017;Pham等人,2018年;刘等人,2018c;本德等人,2018年)。
只有单个one-shot模型的参数才需要训练,并且One-shot的subgraphs可以通过继承One-shot的权重,从而即使没有训练也可以进行评估。这大大加快了架构的性能评估,因为不需要训练(只需要在验证数据上评估性能)。但是这种方法通常会带来很大的偏差,因为它严重低估了体系结构的实际性能;然而,它可靠地允许排名体系结构,因为估计的性能与实际性能密切相关(Bender et al. 2018)。
另外不同的one-shot NAS方法在如何训练one-shot模型上有所不同:ENAS学习了一个RNN控制器,该控制器从搜索空间中采样架构,并根据通过增强得到的近似梯度训练one-shot模型。DARTS优化了one-shot模型的所有权重,并通过在one-shot模型的每条边放置混合的候选操作,连续松弛了搜索空间。Bender et al. 2018只训练一次,并证明了在使用path dropout训练时随机停用模型的部分时,这已经足够了。ENAS和DARTS在训练过程中优化了体系结构上的分布,而Bender et al. 2018的方法可以看作是使用固定的分布。Bender et al.(2018)方法所获得的高性能表明,权重共享和固定分布的组合也可能是One-shot NAS 的 only required ingredients。与这些方法相关的是超网络的元学习,它为新架构生成权重,因此只需要训练超网络,而不需要训练架构本身。这里的主要区别是权值不是严格共享的,而是由共享的超网络生成的(取决于采样的体系结构)。
One-shot NAS很普遍的一个限制Supergraph定义了先验条件将搜索空间限制为其子图。而且有的算法需要将所有Supergraph驻留在GPU内存中,那么这种算法就会对应地选择相对较小的supergraph和搜索空间,并且通常会和cell-based搜索空间结合。尽管权值共享已经大大降低了计算资源的需求,但是如果架构的采样分布和One-shot模型一起优化的话,此时就不太清楚在搜索过程中引入了何种误差。比如说在最开始时可能在搜索空间的A区域引入了误差,然后One-shot模型的权重又刚好在这引入的误差的区域表现更好,那么反过来又会加强对这一部分区域的搜索误差,这可能导致NAS的过早收敛,也可能解释为什么Bender et al. 2018固定采样分布能表现不错。
总而言之,对不同性能估计器引入的偏差进行更系统的分析将是未来工作的理想方向。
4. Future Directions
4.1 Domain
上面所讨论的大多数文献都是基于图像分类这一领域来进行NAS的。一方面,因为在图像分类这一块,人类已经设计出了不少优秀的模型,所以想通过NAS来设计出性能更加优越的模型会非常具有挑战性。另一方面其实很多通过NAS找到的模型其本质上和人类设计的模型类似,因为或多或少都有借鉴人类的经验。因此可能未来将NAS应用到其他还未探索的领域会更加重要,例如language modeling (Zoph and Le, 2017 ), music modeling
(Rawal and Miikkulainen, 2018), image restoration (Suganuma et al., 2018),network
compression (Ashok et al., 2018);在强化学习、生成对抗性网络、语义分割或传感器融合等方面的应用可能是未来的发展方向。
4.2 Multi-tasks & Multi-objective Problems
另一个方向是开发用于多任务问题的NAS方法(Liang et al. 2018;Meyerson和Miikkulainen, 2018)以及多目标问题(Elsken et al2018;Dong et al 2018年;(Zhou et al., 2018),在这些问题中资源效率指标以及对不可见数据的预测性能被用作衡量对象。同样,扩展RL/bandit方法(如第3节中讨论的方法)来学习以编码任务属性/资源需求(即,将场景转换为上下文bandit)为条件的策略(policy)。Ramachandran和Le(2018)遵循了类似的方向,扩展了One-shot NAS,以根据任务或动态实例生成不同的体系结构。此外,将NAS应用于搜索比对抗性示例更健壮的体系结构(Cubuk et al., 2017)是一个有趣的最新方向。
4.3 Definition of search space
另外一个未来的研究方向是定义更一般和更灵活的搜索空间的研究。比如,cell-based搜索空间提供了在不同图像分类任务中很高的可迁移性,但是它还是主要基于人类经验,并且不容易推广到其他领域(如hard-coded hierarchical structure没有应用的领域,例如语义分割和对象检测)。(Liu et al. 2018b)在将搜索空间实现表达和识别更一般的层次结构的方向上的首次尝试。
4.4 The benchmark for comparisiom
对于NAS的不同方法的比较是复杂的,因为一个体系结构性能的度量取决于架构本身以外的许多其他因素。虽然大多数作者在cifar-10数据集上报告结果,但在搜索空间、计算预算、数据增强、培训过程、正则化和其他方面实验往往有所不同。 例如,对于CIFAR-10,为使性能大幅提高,有使用余弦退火时学习速率策略(Loshchilov Hutter,2017),使用CutOut进行数据增强(Devries and Talyoe,2017),MixUp(Zhang et al .,2017)或由多种因素结合(Cubuk et al .,2018),和使用ShakeShake正规算法进行正规化(Gastaldi,2017)或预设drop-path(Zoph et al .,2018)。
可以很明显的看到,与其说是NAS找到了优秀的模型,还不如说是这些优化措施对最终结果起到了重要作用。所以这一方向的第一步是定义一个基准,用于联合架构和超参数搜索,以寻找具有两个隐藏层的完全连接的神经网络(Klein et al., 2018)。在这个基准测试中,需要优化9个离散超参数,以控制体系结构和优化/正则化。所有62.208可能的超参数组合都进行了预先评估,从而可以将不同的方法与低计算资源进行比较。然而,与大多数NAS方法使用的空间相比,搜索空间仍然非常简单。不孤立的,而是以完全开源的AutoML系统(超参数(Mendoza et al., 2016;Real et al., 2017;Zela等,2018)和数据增强管道(Cubuk et al .,2018)和NAS一起优化。)的一部分来评估NAS方法也是一个很有趣的研究方向。
4.5 Interpretability
NAS已经取得了不错的成绩,但是至于为什么有的网络可以表现优异有的不可以,在这点上还没有很直观的解释。所以网络的可解释性也是未来一个很重要的研究方向。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号