论文笔记系列-DARTS: Differentiable Architecture Search
Summary
我的理解就是原本节点和节点之间操作是离散的,因为就是从若干个操作中选择某一个,而作者试图使用softmax和relaxation(松弛化)将操作连续化,所以模型结构搜索的任务就转变成了对连续变量\(α={α^{(i,j)}}\)以及\(w\)的学习。(这里\(α\)可以理解成the encoding of the architecture)。
之后就是迭代计算\(w\)和\(α\),这是一个双优化问题,具体处理细节参见3.Approximation
Research Objective
作者的研究目标
在连续域内进行模型搜索,这样就可以使用梯度下降对模型进行优化。
Problem Statement
- 离散域的结构搜索问题
NAS,ENAS其本质都是在离散空间对模型进行搜索,而文中是这么diss这些方法的:那些方法 把结构搜索当做在离散域内的黑盒优化问题处理,这就导致了需要采样大量的模型进行评估才能选出合适的模型,所以计算量都很大。
原文:
An inherent cause of inefficiency for the dominant approaches, e.g. based on RL, evolution, MCTS (Negrinho and Gordon, 2017), SMBO (Liu et al., 2017a) or Bayesian optimization(Kandasamy et al., 2018), is the fact that architecture search is treated as a black-box optimization problem over a discrete domain, which leads to a large number of architecture evaluations required.
- 早期的连续域结构搜索问题
DARTS并不是最早引入连续域搜索的方法,(Saxena and Verbeek, 2016; Ahmed and Torresani, 2017; Shin et al., 2018)也都是在连续域内做的结构搜索,它们主要是对模型结构的特定属性做微调,例如卷积核大小,分支模式等。但是DARTS和这些方法还是有一些区别的:DARTS可以在丰富的搜索空间中发现具有复杂图形拓扑的高性能体系结构,而且可以生成RNN和CNN模型。
Method(s)
本节思路如下:
1.首先以一般形式描述搜索空间。
2.之后为搜索空间引入了一个简单的连续松弛方案(continuous relaxation scheme)[1],从而为结构及其权重的联合优化提供了一个可微学习的目标。
3.最后提出一个近似方法来使算法在计算上可行且有效。
1.Search Space
根据前人的经验,本文使用了 Cell作为模型结构搜索的基础单元。所学习的单元可以堆叠成卷积网络,也可以递归连接形成递归网络。
一个Cell是由\(N\)个有序节点组成的有向非循环图。每一个节点\(x^{(i)}\)就是一个 latent representation(例如CNN中的feature map),而\(o^{(i,j)}\)表示有向边\((i,j)\)关于\(x^{(i)}\)的操作。
假设每个Cell有两个输入节点和一个输出节点。对于卷积单元而言,输入节点定义为前两层的输出(Zoph et al., 2017)。对于递归单元而言,输入节点就是当前的输入和上移时刻的状态。单元输出是通过对所有中间节点做 reduction operation(例如concatenation) 得到的。其中每个中间节点表达式如下:
\(o^{(i,j)}\)中有一个特殊的操作,即\(zero\)操作,该操作表示两个节点之间没有连接。所以学习构建Cell的任务就简化成了各个edge上的操作。
2.Continuous Relaxation and Optimization
令\(\mathcal{O}\)表示一组候选操作集合(如卷积,最大池化等),而每一个操作用\(o(·)\)表示。
为了使的搜索空间连续,我们将特定操作的分类选择放宽为所有可能操作的softmax,公式如下:
其中,一对节点(i,j)的操作混合权重由维度\(|\mathcal{O}|\)的矢量α参数化。
经过上面公式的松弛(relaxation)之后,模型结构搜索的任务就转变成了对连续变量\(α={α^{(i,j)}}\)的学习,那么\(α\)即为模型结构的编码(encoding)如下图所示。

搜索到最后,我们需要通过将最大可能操作(即\(o^{(i,j)}=argmax_{o∈\mathcal{O}} \,\,α_o^{(i,j)}\))代替混合操作(即\(\overline{o}\))从而得到一个离散的网络结构参数,
为了在所有混合操作中共同学习体系结构α和权重w,DARTS使用梯度下降的方法来优化损失值。
下面将\(\mathcal{L}_{train},\mathcal{L}_{val}\)分别表示训练集和验证集损失值。二者均由\(α\)和\(w\)决定。最终的优化目标是找到在满足\(w^*=argmin_w \,\, \mathcal{L}_{train}(w,α)\)的前提下找到使得\(\mathcal{L}_{val}(w^*,α^*)\)最小化的\(α^*\),用公式表示如下:
s.t. = subject to,表示需要满足后面的条件,即公式(1)需要在满足公式(2)的情况下计算
3.Approximation
精确的计算双层优化问题是很困难的,因为只要α发生任何变化,就需要通过求解公式(2)来重新计算\(w^*(α)\)。
所以本文提出了近似迭代优化过程,其中w和α通过分别在权重和架构空间中的梯度下降步骤之间交替来优化(算法见下图Alg.1)。

算法说明:
假设在第k步,给定当前网络结构\(α_{k-1}\),我们通过\(\mathcal{L}_{train}(w_{k-1},α_{k-1})\)计算梯度更新得到\(w_k\)。然后固定\(w_k\),通过更新网络结构\(a_k\)来最小化验证集损失值(公式3),其中\(\xi\)表示学习率。
网络结构梯度是通过将公式3对\(α\)求导得到的,结果如公式4(为方便书写,用于表示步骤的k已省略)所示:
公式4 推导过程如下(为避免和偏微分符号混淆,下面推导过程将β替换了α)
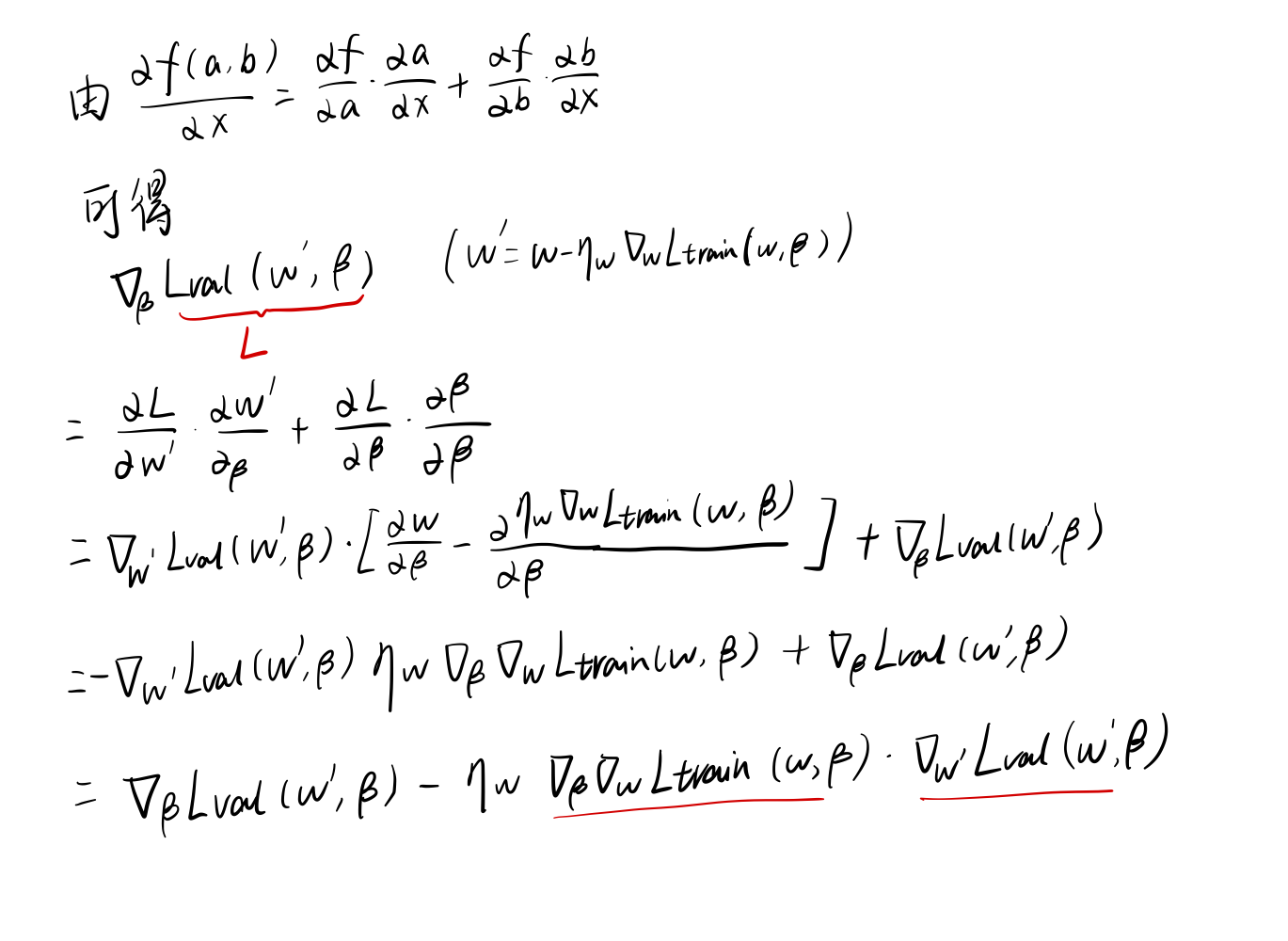
上式中的第二项包含一个矩阵向量积,这是非常难计算的。但是我们知道微分可以通过如下公式进行近似:
所以有:
其中\(w^{+}=w+\epsilon \nabla_{w'}\mathcal{L}_{val}(w',α),w^{-}=w-\epsilon \nabla_{w'}\mathcal{L}_{val}(w',α)\)
公式7推导过程如下
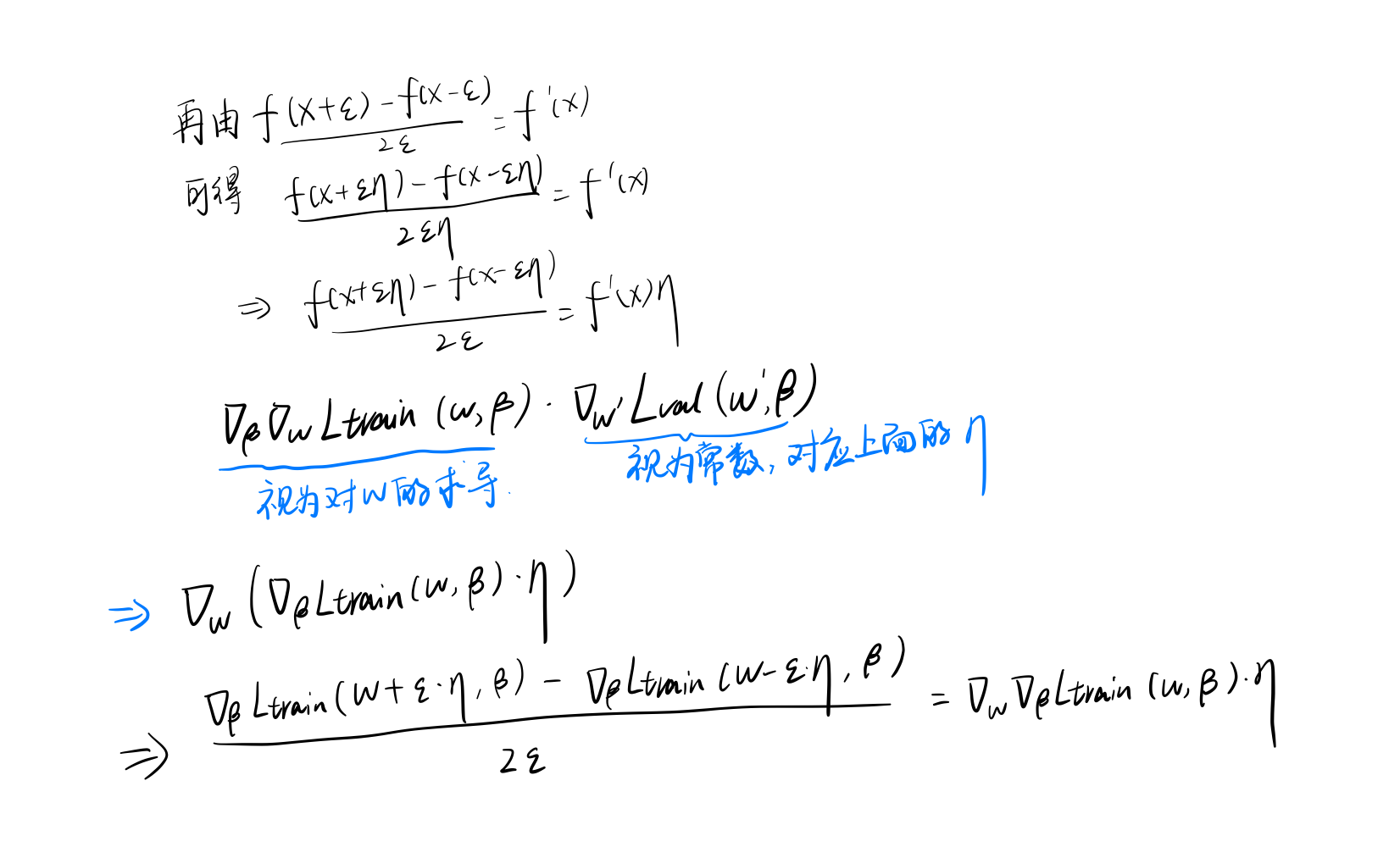
计算有限差分只需要两次权值前传和两次向后传递(α),复杂度从\(\mathcal{O}(|α||w|)\)降低为\(\mathcal{O}(|α|+|w|)\)。
4.Deriving Discrete Architecture
在求得连续模型结构编码\(α\)之后,离散网络结构求解方式如下:

Evaluation
作者如何评估自己的方法,有没有问题或者可以借鉴的地方
Conclusion
贡献如下:
- 引入了一种适用于卷积和循环结构的可微分网络体系结构搜索的新算法。
- 通过实验表明我们的方法具有很强的竞争力。
- 实现了卓越的结构搜索效率(4个GPU:1天内CIFAR10误差2.83%; 6小时内PTB误差56.1),这归因于使用基于梯度的优化而非非微分搜索技术。
- 我们证明DARTS在CIFAR-10和PTB上学习的体系结构可以迁移到ImageNet和WikiText-2上
Notes
疑问:relaxation操作是什么意思?为什么使用softmax能将操作连续化?即公式(1)是什么意思?\(α\)又是什么?

