论文笔记系列-Efficient Neural Architecture Search via Parameter Sharing
Summary
本文提出超越神经架构搜索(NAS)的高效神经架构搜索(ENAS),这是一种经济的自动化模型设计方法,通过强制所有子模型共享权重从而提升了NAS的效率,克服了NAS算力成本巨大且耗时的缺陷,GPU运算时间缩短了1000倍以上。在Penn Treebank数据集上,ENAS实现了55.8的测试困惑度;在CIFAR-10数据集上,其测试误差达到了2.89%,与NASNet不相上下(2.65%的测试误差)
Research Objective 作者的研究目标
设计一种快速有效且耗费资源低的用于自动化网络模型设计的方法。主要贡献是基于NAS方法提升计算效率,使得各个子网络模型共享权重,从而避免低效率的从头训练。
Problem Statement 问题陈述,要解决什么问题?
本文提出的方法是对NAS的改进。NAS存在的问题是它的计算瓶颈,因为NAS是每次将一个子网络训练到收敛,之后得到相应的reward,再将这个reward反馈给RNN controller。但是在下一轮训练子网络时,是从头开始训练,而上一轮的子网络的训练结果并没有利用起来。
另外NAS虽然在每个节点上的operation设计灵活度较高,但是固定了网络的拓扑结构为二叉树。所以ENAS对于网络拓扑结构的设计做了改进,有了更高的灵活性。
Method(s) 解决问题的方法/算法
ENAS算法核心
回顾NAS,可以知道其本质是在一个大的搜索图中找到合适的子图作为模型,也可以理解为使用单个有向无环图(single directed acyclic graph, DAG)来表示NAS的搜索空间。
基于此,ENAS的DAG其实就是NAS搜索空间中所有可能的子模型的叠加。
下图给出了一个通用的DAG示例

如图示,各个节点表示本地运算,边表示信息的流动方向。图中的6个节点包含有多种单向DAG,而红色线标出的DAG则是所选择的的子图。
以该子图为例,节点1表示输入,而节点3和节点6因为是端节点,所以作为输出,一般是将而二者合并求均值后输出。
在讨论ENAS的搜索空间之前,需要介绍的是ENAS的测试数据集分别是CIFAR-10和Penn Treebank,前者需要通过ENAS生成CNN网络,后者则需要生成RNN网络。
所以下面会从生成RNN和生成CNN两个方面来介绍ENAS算法。
1.Design Recurrent Cells
本小节介绍如何从特定的DAG和controller中设计一个递归神经网络的cell(Section 2.1)?
首先假设共有\(N\)个节点,ENAS的controller其实就是一个RNN结构,它用于决定
- 哪条边需要激活
- DAG中每个节点需要执行什么样的计算
下图以\(N=4\)为例子展示了如何生成RNN。

假设\(x[t]\)为输入,\(h[t-1]\)表示上一个时刻的输出状态。
- 节点1:由图可知,controller在节点1上选择的操作是tanh运算,所以有\(h_1=tanh(X_t·W^{(X)}+h_{t-1}·W_1^{(h)})\)
- 节点2:同理有\(h_2 = ReLU(h_1·W_{2,1}^{(h)})\)
- 节点3:\(h_3 = ReLU(h_2·W_{3,2}^{(h)})\)
- 节点4:\(h_4 = ReLU(h_1·W_{4,1}^{(h)})\)
- 节点3和节点4因为不是其他节点的输入,所以二者的平均值作为输出,即\(h_t=\frac{h_3+h_4}{2}\)
由上面的例子可以看到对于每一组节点\((node_i,node_j),i<j\),都会有对应的权重矩阵\(W_{j,i}^{(h)}\)。因此在ENAS中,所有的recurrent cells其实是在搜索空间中共享这样一组权重的。
2.1 Design Convolutional Networks
本小节解释如何设计卷积结构的搜索空间
回顾上面的Recurrent Cell的设计,我们知道controller RNN在每一个节点会做如下两个决定:a)该节点需要连接前面哪一个节点 b)使用何种激活函数。
而在卷积模型的搜索空间中,controller RNN也会做如下两个觉得:a)该节点需要连接前面哪一个节点 b)使用何种计算操作。
在卷积模型中,(a)决定 (连接哪一个节点) 其实就是skip connections。(b)决定一共有6种选择,分别是3*3和5*5大小的卷积核、3*3和5*5大小的深度可分离卷积核,3*3大小的最大池化和平均池化。
下图展示了卷积网络的生成示意图。

2.2 Design Convolutional Cell
本文并没有采用直接设计完整的卷积网络的方法,而是先设计小型的模块然后将模块连接以构建完整的网络(Zoph et al., 2018)。
下图展示了这种设计的例子,其中设计了卷积单元和 reduction cell。

接下来将讨论如何利用 ENAS 搜索由这些单元组成的架构。
假设下图的DAG共有\(B\)个节点,其中节点1和节点2是输入,所以controller只需要对剩下的\(B-2\)个节点都要做如下两个决定:a)当前节点需要与那两个节点相连 b)所选择的两个节点需要采用什么样的操作。(可选择的操作有5种:identity(id,相等),大小为3*3或者5*5的separate conv(sep),大小为3*3的最大池化。)
可以看到对于节点3而言,controller采样的需要连接的两个节点都是节点2,两个节点预测的操作分别是sep 5*5和identity。

3.Training ENAS and Deriving Architectures
本小节介绍如何训练ENAS以及如何从ENAS的controller中生成框架结构。(Section 2.2)
controller网络是含有100个隐藏节点的LSTM。LSTM通过softmax分类器做出选择。另外在第一步时controller会接收一个空的embedding作为输入。
在ENAS中共有两组可学习的参数:
- 子网络模型的共享参数,用\(w\)表示。
- controller网络(即LSTM网络参数),用\(θ\)表示。
而训练ENAS的步骤主要包含两个交叉阶段:第一部训练子网络的共享参数\(w\);第二个阶段是训练controller的参数\(θ\)。这两个阶段在ENAS的训练过程中交替进行,具体介绍如下:
子网络模型共享参数\(w\)的训练
在这个步骤中,首先固定controller的policy network,即\(π(m;θ)\)。之后对\(w\)使用SGD算法来最小化期望损失函数\(E_{m~π}[L(m;w)]\)。
其中\(L(m;w)\)是标准的交叉熵损失函数:\(m\)表示根据policy network \(π(m;θ)\)生成的模型,然后用这个模型在一组训练数据集上计算得到的损失值。
根据Monte Carlo估计计算梯度公式如下:
其中上式中的\(m_i\)表示由\(π(m;θ)\)生成的M个模型中的某一个模型。
虽然上式给出了梯度的无偏估计,但是方差比使用SGD得到的梯度的方差大。但是当\(M=1\)时,上式效果还可以。
下面我们结合下图来理解参数共享到底是什么意思(之前看文章一直没明白什么意思,今天重新看居然恍然大悟。。。。)
可以看到下图中的DAG由6个节点组成,不同节点和数据流向的组合可以得到不同的子网络。下图展示了两个不同的网络结构,为方便说明,我们把由红色箭头组成的网络叫A网络,把蓝色箭头组成的叫B网络。以节点3为例,假设在A网络中节点3的operation是3*3卷积,恰巧在B网络也是这个操作,那么其实就可以重用这个卷积核的权重。
你可能会想,如果A网络的节点3的operation是5*5的卷积怎么办,没关系啊,因为如果下次采样的网络C的数据流向和B一样,刚好节点3的operation也是5*5卷积,那么此时A和C网络就共享这个节点的权重了。

训练controller参数θ
在这个步骤中,首先固定\(w\),之后通过求解最大化期望奖励\(E_{m~π}[R(m;w)]\)来更新\(θ\)。
导出模型架构
首先使用\(π(m,θ)\)生成若干模型。
之后对于每一个采样得到的模型,直接计算其在验证集上得到的奖励。
最后选择奖励最高的模型再次从头训练。
当然如果像NAS那样把所有采样得到的子模型都先从头训练一边,也许会对实验结果有所提升。但是ENAS之所以Efficient,就是因为它不用这么做,原理继续看下文。
Evaluation 评估方法
1.在 Penn Treebank 数据集上训练的语言模型


2.在 CIFAR-10 数据集上的图像分类实验

由上表可以看出,ENAS的最终结果不如NAS,这是因为ENAS没有像NAS那样从训练后的controller中采样多个模型架构,然后从中选出在验证集上表现最好的一个。但是即便效果不如NAS,但是ENAS效果并不差太多,而且训练效率大幅提升。
下图是生成的宏观搜索空间。

ENAS 用了 11.5 个小时来发现合适的卷积单元和 reduction 单元,如下图所示。

Conclusion
ENAS能在Penn Treebank和CIFAR-10两个数据集上得到和NAS差不多的效果,而且训练时间大幅缩短,效率大大提升。
下面内容转自一文看懂JeffDean等提出的ENAS到底好在哪?,感觉写的很好:
前面一直介绍的是 NAS,为了让大家了解 NAS 只是一种搜索算法。NAS 没有学会建模也不能替代算法科学家设计出 Inception 这样复杂的神经网络结构,但它可以用启发式的算法来进行大量计算,只要人类给出网络结构的搜索空间,它就可以比人更快更准地找到效果好的模型结构。
ENAS 也是一种 NAS 实现,因此也是需要人类先给出基本的网络结构搜索空间,这也是目前 ENAS 的一种限制(论文中并没有提哦)。ENAS 需要人类给出生成的网络模型的节点数,我们也可以理解为层数,也就是说人类让 ENAS 设计一个复杂的神经网络结构,但如果人类说只有 10 层那 ENAS 是不可能产出一个超过 10 层网络结构,更加不可能凭空产生一个 ResNet 或者 Inception。当然我们是可以设计这个节点数为 10000 或者 1000000,这样生成的网络结构也会复杂很多。那为什么要有这个限制呢?这个原因就在于 ENAS 中的 E(Efficient)。
大家大概了解过 ENAS 为什么比其他 NAS 高效,因为做了权值共享 (Parameter sharing),这里的权值共享是什么意思呢?是大家理解的模型权重共享了吗,但 ENAS 会产生和尝试各种不同的模型结构,模型都不一样的权重还能共享吗?实际上这里我把 Parameter sharing 翻译成权值共享就代表则这个 Parameter 就是模型权重的意思,而不同模型结构怎样共享参数,就是 ENAS 的关键。ENAS 定义了节点(Node)的概念,这个节点和神经网络中的层(Layer)类似,但因为 Layer 肯定是附着在前一个 Layer 的后面,而 Node 是可以任意替换前置输入的。
下面有一个较为直观的图,对于普通的神经网络,我们一般每一层都会接前一层的输入作为输出,当然我们也可以定义一些分支不一定是一条线的组合关系,而 ENAS 的每一个 Node 都会一个 pre-node index 属性,在这个图里 Node1 指向了 Node0,Node2 也指向了 Node0,Node3 指向了 Node1。
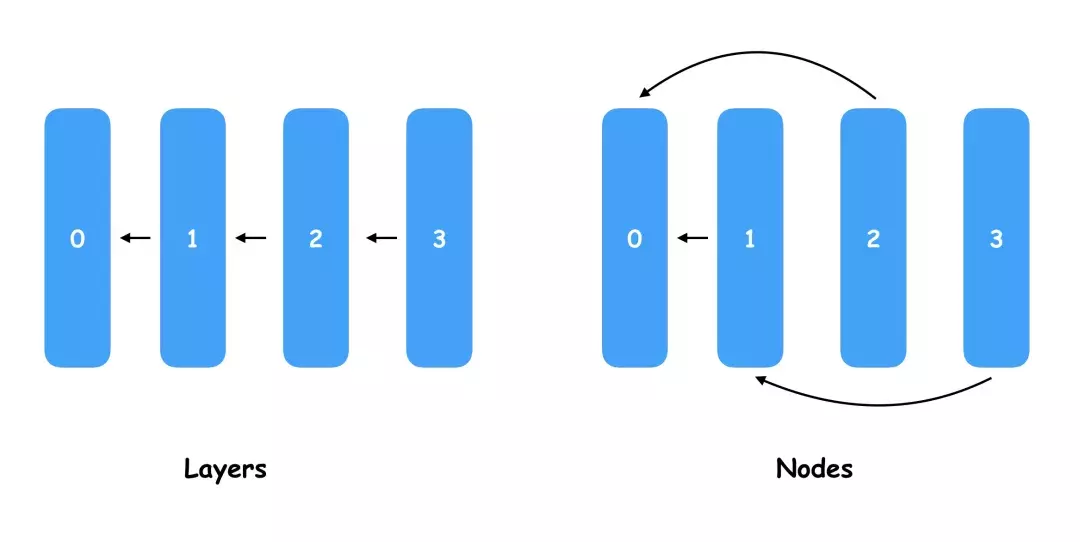
事实上,ENAS 要学习和挑选的就是 Node 之间的连线关系,通过不同的连线就会产生大量的神经网络模型结构,从中选择最优的连线相当于“设计”了新的神经网络模型。如果大家理解了可能觉得这种生成神经网路的结构有点 low,因为生成的网络结构样式比较相似,而且节点数必须是固定的,甚至很难在其中创造出 1x1 polling 这样的新型结构。是的,这些吐槽都是对的,目前 ENAS 可以做的就是帮你把连线改一下然后生成一个新的模型,但这个就是 ENAS 共享权重的基础,而且可以以极低的代码量帮你调整模型结构生成一个更好的模型,接下来就是本文最核心的 ENAS 的 E(Efficient)的实现原理介绍了。
我们知道,TensorFlow 表示了 Tensor 数据的流向,而流向的蓝图就是用户用 Python 代码定义的计算图(Graph),如果我们要实现上图中所有 Layer 连成一条直线的模型,我们就需要在代码中指定多个 Layer,然后以此把输入和输出连接起来,这样就可以训练一个模型的权重了。当我们把上图中所有 Layer 连成一条直线的模型改成右边交叉连线的模型,显然两者是不同的 Graph,而前一个导出模型权重的 checkpoint 是无法导入到后一个模型中的。但直观上看这几个节点位置本没有变,如果输入和输出的 Tensor 的 shape 不变,这些节点的权重个数是一样的,也就是说左边 Node0、Node1、Node2、Node3 的权重是可以完全复制到右边对应的节点的。
这也就是 ENAS 实现权重共享的原理,首先会定义数量固定的 Node,然后通过一组参数去控制每个节点连接的前置节点索引,这组参数就是我们最终要挑选出来的,因为有了它就可以表示一个固定神经网络结构,只要用前面提到的优化算法如贝叶斯优化、DQN 来调优选择最好的这组参数就可以了。那评估模型也是先生成多组参数,然后用新的网络结构来训练模型得到 AUC 等指标吗?答案是否定的,如果是这样那就和普通的 NAS 算法没什么区别了。因为训练模型后评估就是非常不 Efficient 的操作,这里评估模型是指各组模型用相同的一组权重,各自在未被训练的验证集中做一次 Inference,最终选择 AUC 或者正确率最好的模型结构,其实也就是选择节点的连线方式或者是表示连线方式的一组参数。
稍微总结一下,因为 ENAS 生成的所有模型节点数是一样的,而且节点的输入和输出都是一样的,因此所有模型的所有节点的所有权重都是可以加载来使用的,因此我们 只需要训练一次模型得到权重后,让各个模型都去验证集做一个预估,只要效果好的说明发现了更好的模型了。实际上这个过程会进行很多次,而这组共享的权重也会在一段时间后更新,例如我找到一个更好的模型结构了,就可以用这个接口来训练更新权重,然后看有没有其他模型结构在使用这组权重后能在验证机有更好的表现。
回到前面 TensorFlow 实现 ENAS 的问题,我们知道 TensorFlow 要求开发者先定义 Graph,然后再加载权重来运行,但定义 Graph 的过程与模型训练过程是分开的,而 ENAS 要求我们在模型训练过程中不断调整 Graph 的结构来尝试更好的 Graph 模型结构。这在声明式(Declarative)编程接口的 TensorFlow 上其实不好实现,而命令式(Imperative)编程接口的 PyTorch 上反而更好实现。当然这里可以为 TensorFlow 正名,因为 ENAS 的作者就提供了基于 TensorFlow 的 ENAS 源码实现,开源地址 https://github.com/melodyguan/enas 。我们也深入看了下代码,作者用了大量 tf.case()、tf.while() 这样的接口,其实是 在 TensorFlow 的 Graph 中根据参数来生成最终训练的 child 模型的 Graph,因此没有用 Python 代码定义所有 child 模型的 Graph 的集合,也不需要每次都重新构建 Graph 来影响模型训练的性能。
除了 Node 之间的连线外,ENAS 论文里面可以训练的超参数还包括上图中的激活函数,也是通过 controller 模型输出的一组参数来决定每个 Node 使用的激活函数,而这些激活函数不需要重新训练,只需要直接加载共享权重然后做一次 Inference 来参与模型评估即可。

很多人可能觉得目前共享的权重比较简单,只能实现矩阵乘法和加法,也就是全连接层的作用,但在图像方面会用到更多的卷积网络,也会有 filter size、polling kernel size 等参数需要选择。实际上 ENAS 已经考虑这点了,这些 Node 拥有的权重以及使用权重的方法被称为 Cell,目前已经提供乘法和卷积这两种 Cell,并且在 PTB 和 Cifar10 数据集上做过验证,当然未来还可以加入 RNN 等 Cell,甚至多种 Cell 一起混用,当然这个在实现上例如前置节点的连线上需要有更复杂的判断和实现。
对于 ENAS 的 controller 模型的参数调优,论文中使用的是增强学习中的 Policy gradient,当然正如前面所提到的,使用贝叶斯优化、DQN、进化算法也是没问题的。不过目前 ENAS 的 controller 模型和共享权重的实现放在了一起,因此要拓展新的 controller 提优算法比较困难,未来我们希望把更多的调优算法集成到 Advisor 中(目前已经支持 Bayesian optimization、Random search、Grid search,正在计划支持 Policy gradient、DQN、Evolution algorithm、Particle swarm optimization 等),让 ENAS 和其他 NAS 算法也可以更简单地使用已经实现的这些调优算法。
总体而言,ENAS 给我们自动超参调优、自动生成神经网络结构提供了全新的思路。通过权值共享的方式让所有生成的模型都不需要重新训练了,只需要做一次 Inference 就可以获得大量的 state 和 reward,为后面的调优算法提供了大量真实的训练样本和优化数据。这是一种成本非常低的调优尝试,虽然不一定能找到更优的模型结构,但在这么大的搜索空间中可以快速验证新的模型结构和调优生成模型结构的算法,至少在已经验证过的 PTB 和 CIFAR-10 数据集上有了巨大的突破。
当然也不能忽略 ENAS 本身存在的缺陷(这也是未来优化 ENAS 考虑的方向)。首先是为了共享权重必须要求 Node 数量一致会限制生成模型的多样性;其次目前只考虑记录前一个 Node 的 index,后面可以考虑连接多个 Node 制造更大的搜索空间和更复杂的模型结构;第三是目前会使用某一个模型训练的权重来让所有模型复用进行评估,对其他模型不一定公平也可能导致找不到比当前训练的模型效果更好的了;最后是目前基于 Inference 的评估可以调优的参数必须能体现到 Inference 过程中,例如 Learning rate、dropout 这些超参就无法调优和选择了。
总结
最后总结下,本文介绍了业界主流的自动生成神经网络模型的 NAS 算法以及目前最为落地的 ENAS 算法介绍。在整理本文的时候,发现 NAS 其实原理很简单,在一定空间内搜索这个大家都很好理解,但要解决这个问题在优化上使用了贝叶斯优化、增强学习等黑盒优化算法、在样本生成上使用了权值共享、多模型 Inference 的方式、在编码实现用了编写一个 Graph 来动态生成 Graph 的高级技巧,所以要 读好一篇 Paper 需要有一对懂得欣赏的眼睛和无死角深挖的决心。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号