论文笔记系列-Simple And Efficient Architecture Search For Neural Networks
摘要
本文提出了一种新方法,可以基于简单的爬山过程自动搜索性能良好的CNN架构,该算法运算符应用网络态射,然后通过余弦退火进行短期优化运行。
令人惊讶的是,这种简单的方法产生了有竞争力的结果,尽管只需要与训练单个网络相同数量级的资源。例如使用该算法,在单个GPU上训练12个小时就可以将CIFAR-10数据集的错误率降低到6%一下,训练一整天后能够降低到5%左右。
1.介绍
背景不再详述,我们可以知道的是传统的优化算法并不能实现神经网络架构的自动搜索是因为其架构搜索空间是 离散的(例如层数、层类型等), 有条件的(例如,定义层的参数的数量取决于层类型)。因此,依赖于可微分或者独立参数的算法是不可行的。
由于上述原因也就使得进化算法和增强算法得到广泛应用,但是这些方法要么消耗巨大,要么无法获得优异的表现。
本文的贡献如下:
- 提出了一种基线方法,该方法 随机构造出网络,并使用SGDR对这些网络训练。该基线方法在CIFAR-10的测试集上能够实现6%-7%的错误率。
- 正式确定并扩展了网络态射的工作(Chen et al。,2015; Wei et al。,2016; Cai et al。,2017),以提供流行的网络构建模块,例如跳过连接和批量规范化。
- 提出 Neural Architecture Search by Hillclimbing (NASH),该算法已在摘要中介绍。
2.相关工作
-
Hyperparameter optimization:
- random search (Bergstra & Bengio, 2012)
- Bayesian optimization (Bergstra et al., 2011; Snoek et al., 2012)
- bandit-based approaches (Li et al., 2016a)
- evolutionary strategies (Loshchilov & Hutter, 2016)
-
Automated architecture search:
- (Bergstra et al., 2011; Mendoza et al., 2016)将架构搜索视为超参数搜索,使用标准的超参数优化算法来优化架构。
- (Baker et al., 2016; Zoph & Le, 2017; Cai et al., 2017)三个方法都采用训练增强学习代理(reinforcement learning agent)的方式。
- Baker et al. (2016)通过训练一个RL Agent来按顺序选择层类型(卷积,池化,全连接)和它们的参数。
- Zoph & Le (2017)使用递归神经网络控制器来按顺序生成用于表示网络架构的字符串。
- 上述两个方法都是从头训练所生成的网络,并且耗时较长。为了解决这些问题,Cai et al. (2017)提出在RL中应用网络变换/态射的概念。
- Real et al. (2017) 和 Suganuma et al. (2017)使用进化算法从小网络来迭代生成强有力的网络。诸如插入一层、修改一层的参数、增加跳跃连接都视为“突变”。其中前者使用大量的计算资源(250GPUs,10天),后者则由于处理大量网络而被限制在相对较小的网络上。前面两种算法中的网络容量会随时间不断增大,而, Saxena & Verbeek(2016)则是在一开始就训练一个大型的网络,然后在最后做剪枝。
-
Network morphism/ transformation.:这是Chen et al. (2015)在迁移学习基础上提出来的。作者介绍了一个函数保留操作,该函数可以使得网络更深("Net2Deeper")或者更宽("Net2Wider"),目的是加速培训和探索网络架构。Wei et al. (2016) 提出了其它的操作,如用于处理非幂等激活函数、改变内核大小,并引入网络态射概念。
3. 网络态射(Network Morphism)
令\(N(X)\)表示定义在\(X \subset{R^n}\)一组神经网络。网络态射是指从参数为\(w∈R^k\)的神经网络\(f^w∈N(x)\)映射为参数为\(\tilde{w}∈R^j\)的神经网络\(g^{\tilde{w}}∈N(x)\),即:
下面会给出几个网络态射的例子以及用于构建神经网络的操作(如添加一个卷积层)是如何表示为网络态射的。为方便说明,令\(f_i^{w_i}(x)\)表示神经网络\(f^w(x)\)的某一个部分,如可能是某一层或者是子集网络。
3.1 Network morphism Type I
使用下式代替\(f_i^{w_i}(x)\)
其中\(\tilde{w}_i=(w_i,A,b)\)。显然当\(A=1,b=0\)时,公式(2)则退化成公式(1)。
这种态射可以用于添加全连接层或者卷积层,因为这些层都是简单的线性映射。Chen et al. (2015) 称这个态射为"Net2DeeperNet"。
除了上面的替换方式,也可以有
其中\(\tilde{w}_i=(w_i,C,d)\)。\(A,b\)是固定的,不可学习的。当\(C=A^{-1},d=-Cb\)时公式(3)变成了公式(1)。批标准化层(或者其他标准化层)可以用上面的表达式表示:\(A,b\)表示批量统计数据,\(C,d\)表示可学习的缩放和位移。
3.2 Network morphism Type II
假设\(f_i^{w_i}(x)=Ah^{w_h}(x)+b\),其中\(h\)为任意函数。
我们使用如下式子代替\(f_i^{w_i}(x)\):
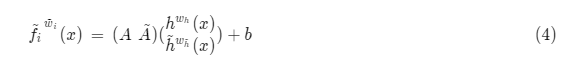
其中\(\tilde{h}^{w_{\tilde{h}}} (x)\)是任意函数。新参数\(\tilde{w}_i=(w_i,w_{\tilde{h}},\tilde{A})\)。同理,当\(\tilde{A}=0\)时依然可以得到公式(1)。
公式(4)可以有两种对NN的修改方式:
- 1.加宽某一层,例如当\(\tilde{h}=h\)时,宽度加倍。
- 2.可以事先跳跃连接(skip connections)。例如假设\(h(x)\)表示一系列的网络层,即\(h(x)=h_n(x)◦···h_0(x)\),那么当\(\tilde{h}(x)=x\)时则实现了从\(h_0\)到\(h_n\)的跳跃连接。
3.3 Network morphism Type III
根据定义,每一个幂等函数\(f_i^{w_i}(x)\)都可以用下面的式子代替:
初始化\(\tilde{w}_i=w_i\)。
幂等(idempotent、idempotence)是一个数学与计算机学概念,常见于抽象代数中。
在编程中一个幂等操作的特点是其任意多次执行所产生的影响均与一次执行的影响相同。
例如f(f(x))=f(x),那么f(x)就是幂等函数。
3.4 Network morphism Type IV
使用下式代替\(f_i^{w_i}(x)\):
\(h\)为任意函数。
这种态射可用于合并任何函数,尤其是任何非线性函数。
4. ARCHITECTURE SEARCH BY NETWORK MORPHISMS
- 1. 最开始使用一个小型的预训练模型
- 2. 将网络态射应用到该初始化网络中,经过训练后可以生成表现更加,更大的网络。所生成的网络可看作是“child”网络,初始网络可看作是“parent”网络。
- 3. 在上面步骤生成的子网络中找到表现最优秀的网络,然后在该网络上继续生成子网络,不断迭代优化。
以上方法即为 Neural Architecture Search by Hill-climbing (NASH)
下图展示了NASH的步骤:

NASH的算法步骤如下:

在实现上图中的算法时,函数ApplyNetMorph(model, n)应用\(n\)个网络态射,每个都是从下面三种情况中均匀随机采样的:
- 使网络更深,即加上"Conv-Batchnorm-Relu"模块。模块所加的位置和kernel大小(\(∈{3,5}\))都是均匀采样的。通道的数量与前一个最近的卷积通道数相等。
- 使网络更宽,即通过使用 网络态射II增加通道数量。需要拓宽的卷积层和拓宽因子(\(∈{2,4}\))都是均匀采样的。
- 通过分别使用网络态射类型II或IV,添加从第i层到第j层的跳跃连接(通过 concatenation 或 addition - 均匀采样)。 层i和j也都是均匀地采样。
5. 实验与结果
具体的实验结果可查阅原论文 Simple And Efficient Architecture Search For Neural Networks。

