Andrew Ng机器学习课程笔记--week3(逻辑回归&正则化参数)
Logistic Regression
一、内容概要
- Classification and Representation
- Classification
- Hypothesis Representation
- Decision Boundary
- Logistic Regression Model
- 损失函数(cost function)
- 简化损失函数和梯度下降算法
- Advanced Optimization(高级优化方法)
- Solving the problem of Overfitting
- 什么是过拟合?
- 正则化损失函数(cost function)
- 正则化线性回归(Regularized Linear Regression)
- 正则化逻辑回归(Regularized Logistic Regression)
二、重点&难点
1. Classification and Representation
1) Hypothesis Representation
这里需要使用到sigmoid函数--g(z):
\[\begin{equation}
h_θ(x) = g(θ^Tx)
\end{equation}
\]
\[\begin{equation}
z = θ^Tx
\end{equation}
\]
\[\begin{equation}
g(z) = \frac{1}{1+e^{-z}}
\end{equation}
\]

2) Decision Boundary
决策边界:
\[h_θ(x) ≥ 0.5 → y=1
\]
\[h_θ(x) < 0.5 → y=0
\]
等价于
\[g(z) ≥ 0.5 → y=1
\]
\[g(z) < 0.5 → y=0
\]
等价于
\[z ≥0 → y=1
\]
\[z < 0 → y=0
\]
2. Logistic Regression Model
1) 逻辑回归的损失函数
这里之所以再次提到损失函数,是因为线性回归中的损失函数会使得输出呈现起伏,造成许多局部最优值,也就是说线性回归中的cost function在运用到逻辑回归时,将可能不再是凸函数。
逻辑回归的cost function如下:
\[J_θ = \frac{1}{m} \sum {Cost}( h_θ(x^{(i)}, y^{(i)} ) )
\]
\[{Cost}(h_θ(x), y) ) = - log(h_θ(x)) \quad \quad if \quad y=1
\]
\[{Cost}(h_θ(x), y) ) = - log(1 - h_θ(x)) \quad if \quad y=0
\]
结合图来理解:
- y=1
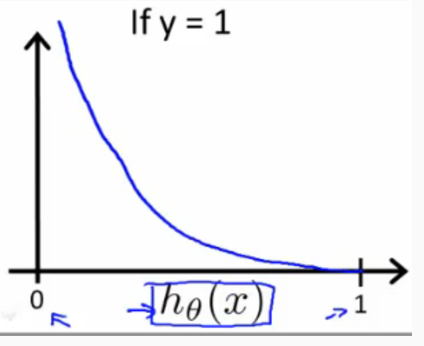
由上图可知,y=1,hθ(x)是预测值,
- 当其值为1时,表示预测正确,损失函数为0;
- 当其值为0时,表示错的一塌糊涂,需要大大的惩罚,所以损失函数趋近于∞。
- y=0
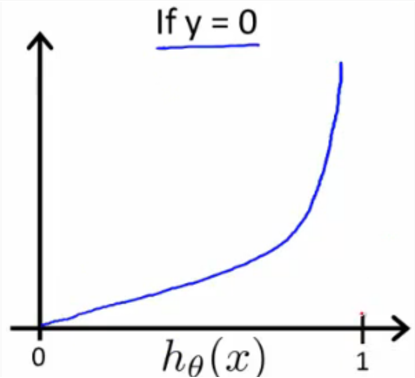
上图同理
2) Simplified Cost Function and Gradient Descent
- 损失函数
cost function
\[Cost(h_θ(x), y) = -ylog(h_θ(x)) - (1-y)log(1-h_θ(x))
\]
Jθ
\[J_θ=-\frac{1}{m} \sum Cost(h_θ(x), y)
\]
\[\quad =-\frac{1}{m} \sum [-y^{i}log(h_θ(x^{(i)})) - (1-y^i)log(1-h_θ(x^{(i)}))]
\]
- 梯度函数

3)高级优化方法

如图左边显示的是优化方法,其中后三种是更加高级的算法,其优缺点由图邮编所示:
优点
- 不需要手动选择α
- 比梯度下降更快
缺点
- 更加复杂
后面三种方法只需了解即可,老师建议如果你不是专业的数学专家,没必要自己使用这些方法。。。。。。当然了解一下原理也是好的。
3. Solving the problem of Overfitting
1) 过拟合
主要说一下过拟合的解决办法:
1)减少特征数量
- 手动选择一些需要保留的特征
- 使用模型选择算法(model selection algorithm)
2)正则化 - 保留所有特征,但是参数θ的数量级(大小)要减小
- 当我们有很多特征,而且这些特征对于预测多多少少会由影响,此时正则化怎能起到很大的作用。
2) 正则化损失函数
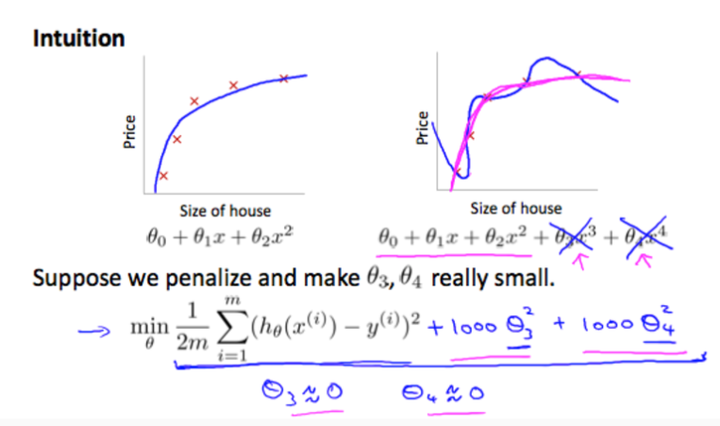
图示右边很明显是过拟合,因此为了纠正加入了正则化项:1000·θ32,为了使得J(θ)最小化,所以算法会使得θ3趋近于0,θ4也趋近于0。
正则化损失函数表达式:
\[J(θ)=\frac{1}{2m} [\sum_{i=1}^m( h_θ(x^{(i)}) - y^{(i)})^2 + λ\sum_{j=1}^n θ_j^2]
\]
\[min_θ [\frac{1}{2m} (\sum_{i=1}^m( h_θ(x^{(i)}) - y^{(i)})^2 + λ\sum_{j=1}^n θ_j^2)]
\]
3) 正则化线性回归
- 正则化梯度下降:
\[J(θ)=\frac{1}{2m} [\sum_{i=1}^m( h_θ(x^{(i)}) - y^{(i)})^2 + λ\sum_{j=1}^n θ_j^2]
\]
\[\frac{∂J_θ}{∂θ_j} = \frac{1}{m} \sum_{i=1}^m( h_θ(x^{(i)} ) - y^{(i)} )x_j^{(i)} + \frac{λ}{m}θ_j
\]
Repeat{
\[θ_0 := θ_0 - α\frac{1}{m}\sum_{i=1}{m}( h_θ(x^{(i)} ) - y^{(i)} )x_0^{(i)}
\]
\[θ_j := θ_j - α[(\frac{1}{m}\sum_{i=1}{m}( h_θ(x^{(i)} ) - y^{(i)} )x_0^{(i)} ) + \frac{λ}{m}θ_j ] \quad j∈\{1,2,3……n\}
\]
}
- 正则化正规方程
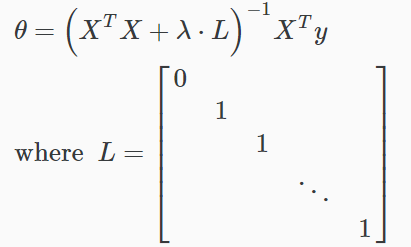
前面提到过,若m< n,那么XTX是不可逆的,但是加上λ·L后则变为可逆的了。
4) 正则化逻辑回归
\[J(θ)=-\frac{1}{m} \{\sum_{i=1}^m[ y^{(i)} log(h_θ(x^{(i)}))+(1-y^{(i)})log(1-h_θ(x^{(i)}))]\} + \frac{λ}{2m}\sum_{j=1}^n θ_j^2
\]
梯度下降过程


 浙公网安备 33010602011771号
浙公网安备 33010602011771号