详解Pytorch里的pin_memory 和 non_blocking
前言
pin_memory 和 non_blocking的作用分别是什么?网上看了很多解释,只是稀里糊涂的有个感觉,就是用了这玩意速度能变快,但是不知所以然,这篇文章希望能帮助你解惑,也给自己做个笔记,以备日后查阅。
train_sampler = None
train_loader = torch.utils.data.DataLoader(
train_dataset,
...,
pin_memory=True
)
for data, labels in train_loader:
data = data.to('cuda:0', non_blocking=True)
1. pin_memory
1.1 什么是锁页内存(Pinned Memory/PageLocked Memory)?什么是"Pinned"?
通常我们的主机处理器是支持虚拟内存系统的,即使用硬盘空间来代替内存。大多数系统中虚拟内存空间被划分成许多页,它们是寻址的单元,页的大小至少是4096个字节。虚拟寻址能使一个连续的虚拟地址空间映射到物理内存并不连续的一些页。
如果某页的物理内存被标记为换出状态,它就可以被更换到磁盘上,也就是说被踢出内存了。如果下次需要该页了,则重新加载到内存里。显然如果这一页切换的非常频繁,那么会浪费不少时间。
锁页(pinned page)是操作系统常用的操作,就是为了使硬件外设直接访问CPU内存,从而避免过多的复制操作。被锁定的页面会被操作系统标记为不可被换出的,所以设备驱动程序给这些外设编程时,可以使用页面的物理地址直接访问内存,CPU也可以访问上述锁页内存,但是此内存是不能移动或换页到磁盘上的。另外,在GPU上分配的内存默认都是锁页内存,这只是因为GPU不支持将内存交换到磁盘上。
1.2 什么时候设置pin_memory=True?
总结一下上一小节的内容就是:
内存可以分为 没锁的(pageable,可分页的) 和 锁了的(pinned)。
- 锁页内存和GPU显存之间的拷贝速度大约是6GB/s
- 可分页内存和GPU显存间的拷贝速度大约是3GB/s。
- GPU内存间速度是30GB/s,CPU间内存速度是10GB/s
Host(例如CPU)的数据分配默认是pageable(可分页的),但是GPU是没法直接读取pageable内存里的数据的,所以需要先创建一个临时的缓冲区(pinned memory),把数据从pageable内存拷贝pinned内存上,然后GPU才能从pinned内存上读取数据,如下图(左)所示。
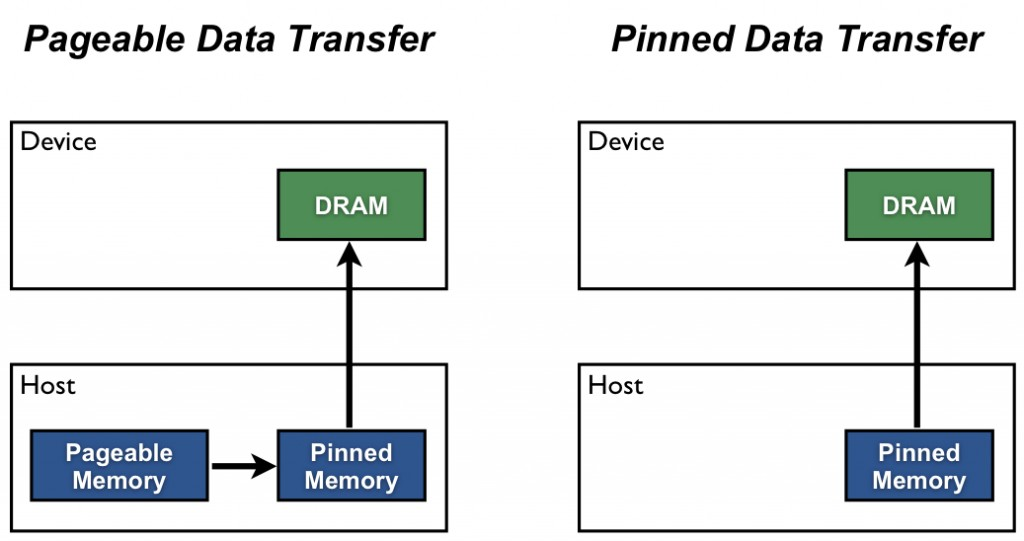
但是CPU将数据从pageable 内存拷贝到 临时的 pinned 内存是有时间开销的,而且这个pinned 内存 还只是临时的,所以用完之后会被销毁。所以为了进一步提高效率,我们需要设置pin_memory=True,作用就是从一开始就把一部分内存给锁住(上图(右)),这样一来就减少了Host内部的开销,避免了CPU内存拷贝时间。
按照官方的建议[1]是你默认设置为True就对了。
2. non_blocking
2.1 CUDA Default Streams
在CUDA里, "Stream"是指一系列的操作,这些操作按照主机代码发出的顺序在设备上执行。同一个Stream里的操作是按顺序执行的,而不同Stream里的操作可以交错执行,并且在可能的情况下,它们甚至可以并发执行。
stream有很多种,无特殊指定的话使用的就是默认stream(default stream,也称作 null stream)。它和其他stream的却比就在于:1)如果其他stream上的操作没结束,null stream就不会开始; 2)在device上的其他stream要开始之前,null stream必须先完成。所以说null stream是设备相关操作的同步流(synchronizing stream)。
我们看下面使用default stream的例子,注意cuda代码有个特点,即代码是在Host和Device上通用的,换句话说有的代码可能运行在Host上,有的是在Device上。
cudaMemcpy(d_a, a, numBytes, cudaMemcpyHostToDevice);
increment<<<1,N>>>(d_a)
cudaMemcpy(a, d_a, numBytes, cudaMemcpyDeviceToHost);
上面3行代码都属于 default stream,因此是按顺序执行的。具体来说从device的角度看,从GPU上启动一个kernel是异步的操作,而data transfer操作是一个blocking或者synchronous操作。
- 第一行是将数据从Host(CPU内存)拷贝到device(GPU显存)。注意此时还是在Host上执行的,也就是说这个时候Host上的CPU在将数据拷贝到Device上,所以必须得等到第一行运行结束后,才会进入到第二行代码
- 第二行代码是在Device上启动(launch)和执行(execute)的。注意分成启动和执行两步骤。一旦第二行启动后,主机上的CPU就会立马执行第三行,并不会再去等执行了
- 第三行代码是将数据从Device拷贝到Host,但是此时的data transfer需要等到第二行Device执行结束才能开始。
通过上面的例子我们知道kernel的启动是异步的,也就是说一旦kernel被启动,Host就可以直接运行下一行代码。比如我们更改一下代码,如下所示。下面代码当第二行kernel启动后,Device就会开始执行increment计算,而Host上的CPU会立马执行第三行。此时Host和Device同时都在干活,假设二者的计算时间相等,那么第四行基本上就可以无缝衔接了。
对于Device而言,上下两个代码示例并无差别,但是对于Host而言,其效率提升了。
cudaMemcpy(d_a, a, numBytes, cudaMemcpyHostToDevice);
increment<<<1,N>>>(d_a)
myCpuFunction(b)
cudaMemcpy(a, d_a, numBytes, cudaMemcpyDeviceToHost);
2.2 Non-default Stream
上面介绍的是default stream,那么就有non-defalut stream,CUDA代码中定义的方法示例如下
cudaStream_t stream1;
cudaError_t result;
result = cudaStreamCreate(&stream1)
result = cudaStreamDestroy(stream1)
为了给non-defalut stream传输数据,我们使用cudaMemcpyAsync()函数,它类似于前一篇示例中讨论的cudaMemcpy()函数,但需要将 stream 标识符作为第五个参数传入,即
// 将数据从Host传输到Device
result = cudaMemcpyAsync(d_a, a, N, cudaMemcpyHostToDevice, stream1)
cudaMemcpyAsync在Host上是 non-blocking 的,也就是说数据传输kernel一启动,控制权就直接回到Host上了,即Host不需要等数据从Host传输到Device了。
non-default stream上的所有操作相对于 host code 都是 non-blocking 的,即它们不会阻塞Host代码。
所以下面代码中的第二行应该是在第一行启动后就立马执行了。Pytorch官方的建议是pin_memory=True和non_blocking=True搭配使用,这样能使得data transfer可以overlap computation。
x = x.cuda(non_blocking=True)
pre_compute()
...
y = model(x)
注意non_blocking=True后面紧跟与之相关的语句时,就会需要做同步操作,等到data transfer完成为止,如下面代码示例
x=x.cuda(non_blocking=True)
y = model(x)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律
2019-03-08 【转载】PyTorch系列 (二):pytorch数据读取
2019-03-08 Pytorch划分数据集的方法
2019-03-08 【转载】大白话Docker入门(二)
2019-03-08 【转载】大白话Docker入门(一)
2018-03-08 计算机四级网络工程师等级考试题库软件---百度云分享