ICLR2020 | 解决长尾分布的解耦学习方法
Decoupling representation and classifier for long-tailed recognition
代码链接:https://github.com/facebookresearch/classifier-balancing
1. 主要贡献
长尾分布数据集是目前训练模型的一个很大的挑战,模型在这类数据集上通常会在 head-classes (即数量较多的类别)上overfitting,而在tail-classes(即数量较少的类别)上under-fitting。解决imbalanced的问题常用的方法有:1)re-sampling dataset;2)re-weighting loss function; 3)把head-classes的特征迁移给tail-classes等。
该论文通过设置一系列的实验,发现以下现象:
- 把训练过程解耦成了两部分:1)representations learning (即特征提取)和 2) classification 能够有效提高模型在长尾分布数据集上的性能
- 作者发现以下两种方法(在 representations learning 过程中同时优化训练分类器)能提高性能:
- 固定feature,然后使用class-balanced 采样策略retrain分类器
- 对分类器的权重加约束(正则)也可以提高性能
- 以上方式用在像ResNet这些常用模型上也能在Long-Tailed (LT)数据集上取得不错的效果
2. Representations Learning
2.1 Data Re-sampling
每个样本被采样的概率可以表示成如下:\(C\)表示类别数量, \(n_j\)表示第 j 类的样本数,\(q\in\{0,1,0.5\}\)分别表示不同的采样策略。
- Instance-balanced (IB) sampling:这个就是最普通也是最常用的采样策略,即每个样本被采样的概率均等,对应公式(1)中的 \(q=1\)。
- Class-balanced (CB) sampling: 这个就是说每个类别被采样的概率相等,比如我们总共有4类,每次采样的batch包含64个样本,那么每个batch中一定包含4个类别,每个类别的数量都是16,只不过类别里的样本被采样的概率就是相等的。具体的实现可以参考
catalyst.data.sampler.BatchBalanceClassSampler[代码]。公式(1)中\(q=0\)时表示每个类别被采样的概率相等 - Progressively-balanced sampling:这个其实就是将上面 Instance-和Class- balanced做了结合,即下式, \(t,T\)分别表示当前的epoch和总的epoch数。
- Square-root sampling: 对应公式(1)中\(q=0.5\)
2.2 Loss re-weighting
比较常见的方法有 focal loss,或者给tail-classes赋予更高的权重等
3. Classification
上一节总结了常用的学习特征的训练方法,这一节总结常用的训练分类器的方法。
- Classifier Re-training (cRT): 这个就是比较常规的做法,即把 feature representations固定住,然后使用class-balanced sampling 对classifier做finetune
- Nearest Class Mean classifier (NCM): 这个是非参数方法,即先使用训练集计算出 \(C\) 个类别的中心 feature tensor,然后每次做预测的时候使用 cosine similarity或者 MSE loss计算出每个样本离这些中心feature的距离,离谁更近就预测属于哪一类,这类似于KNN算法
- \(\tau\)-normalized classifier :我们知道在 TL 数据集上,模型在预测的时候会倾向于把样本都预测成类别多的那一类,极端情况甚至全都预测成同一类。假设这一类是第 \(i\) 类,这个时候很有可能是因为最后预测器(即全连接层)的第 \(i\) 类的权重值远大于其他类别的权重,所以一种解决办法就是给分类器的权重加上正则项,公式如下,\(\tau\) 是一个超参数,当\(\tau=1\)时,下式就等价于普通的 L2正则。一般取值是在0到1之间。
- Learnable weight scaling (LWS):公式3中的分母是依赖于权重值,当然我们也可以让分母设置成一个可学习的参数 \(f_i\),它的初始值和公式3一致(如下式)。在优化 \(f_i\)的过程中,representations和classifier的参数都是固定住的。
4. 实验
4.1 实验设置
因为长尾分布数据集中有的类别可能只有几张图片,有的可能有上千张图片,所以之前常用的Acc并不能有效表达出模型性能的好坏,所以后面论文给出了不同类别的分类准确率
- All: 所有类别的acc
- Many-shot: 图片数量大于100的类别的acc
- Medium-shot:图片数量在20到100之间的类别的acc
- Few-shot:图片数量小于20的类别的acc
4.2 Sampling Strategies & Decoupled Learning

从Figure1我们能看到一下几个现象:
- 只看4个图像的 Joint (即backbone和classifier同时训练)那一列,我们可以看到随着采样策略的改善(从Instance到Progressively-balanced),Medium和Few 类别以及整体(All)的accuracy是稳步提升的。但是对于 Many类别,它的accuracy在 Instance-balanced情况下是最高的,这个也符合预期,因为这个时候模型会更加侧重于数据多的类别。所以实验结果表明 对于Joint的训练模式,数据采样非常重要。
- 论文中给出了3个decoupled learning的方法,分别是 NCM, cRT和\(\tau\)-norm。上图可以看到除了Many-shot,这三个方法在其他3个类别上都比Joint训练模式表现更好
- 一个很有意思的实验结果是,在3个解耦学习的方法上,IB 采样策略训练得到的模型反而表现最好。换句话说,如果我们使用解耦的训练方式,我们可能不用太花心思在数据采样上。
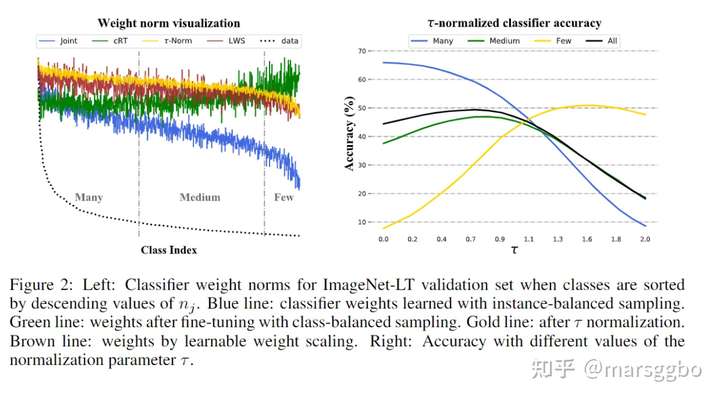
Figure 2 (左) 给出了不同训练模式下 classifier权重的norm值。图中Class Index是按照类别包含的样本数降序排列的,即class-0含有组多样本。
- 可以看到对于Joint模式,weight norm值是逐渐减少的,即class-0的norm值最大。显然当这个norm值远大于其他类别的norm值时,模型很可能会将所有样本都只预测成class-0。
- cRT, \(\tau\)-norm和LWS都有效提高了Medium和Few classes的weight norm。
Figure 2 (右) 给出了 \(\tau\)-norm方法\(\tau\)对结果的影响。可以看到增加τ的大小能明显改善 Few classes的准确率,但是同时Many classes会对应减少。Medium和All 的准确率先增后降,而且后期降得特别厉害,所以τ值的选择也比较重要。
4.3 实验结果对比
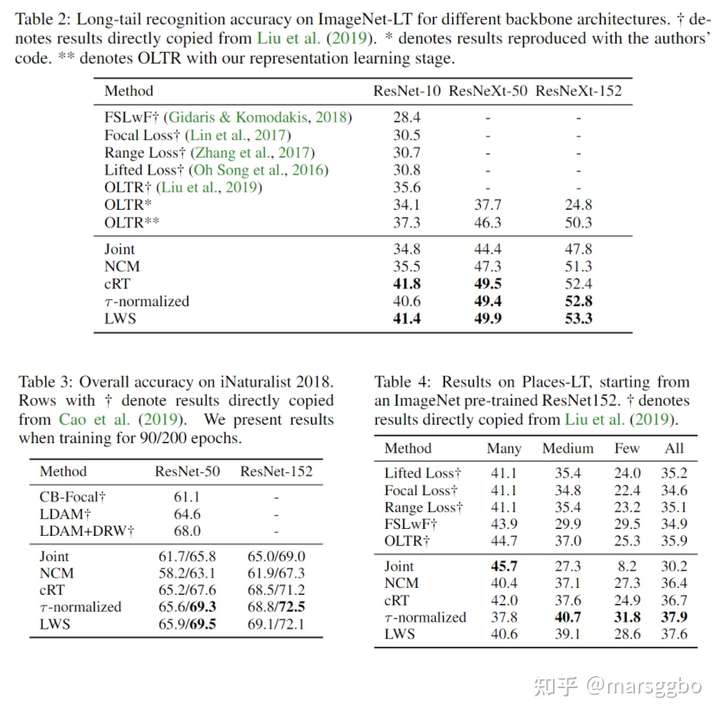
作者在3个TL数据集上做了实验,可以看到提升效果都比较明显。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号