ICLR2022 | UniNet: Unified Architecture Search with Convolution, Transformer, and MLP
1. 主要创新
《UniNet: Unified Architecture Search with Convolution, Transformer, and MLP》是ICLR2022的一篇投稿论文,目前还没出结果。这里总结一下该工作的主要创新和贡献点:
- UniNet是第一个将卷积,Transformer和MLP统一起来进行搜索的工作
- 论文发现在融合上述三种不同模块的时候,传统的下采样模块(如stride=2的卷积)会成为模型性能的瓶颈。所以作者提出了 context-aware down-sampling modules (DSM), 包含 local-global-DSM (LG_DSM) 和 global-DSM (G-DSM)
- UniNet性能超过了efficientnet和SwinTransformer
2. 相关工作
-
混合模型:
-
ConViT (ICML2021) [1] :unify convolution and self-attention with gated positional self-attention (GPSA) and is more sample-efficient than self-attention.
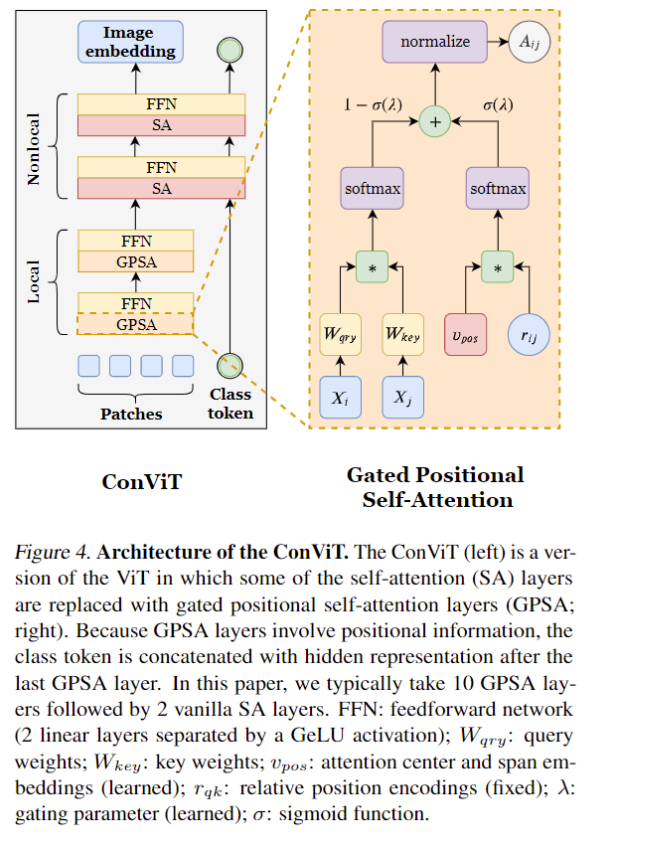
-
CvT (ICCV2021) [2]:incorporate self-attention and convolution by generating Q, K, and V in self-attention with convolution.
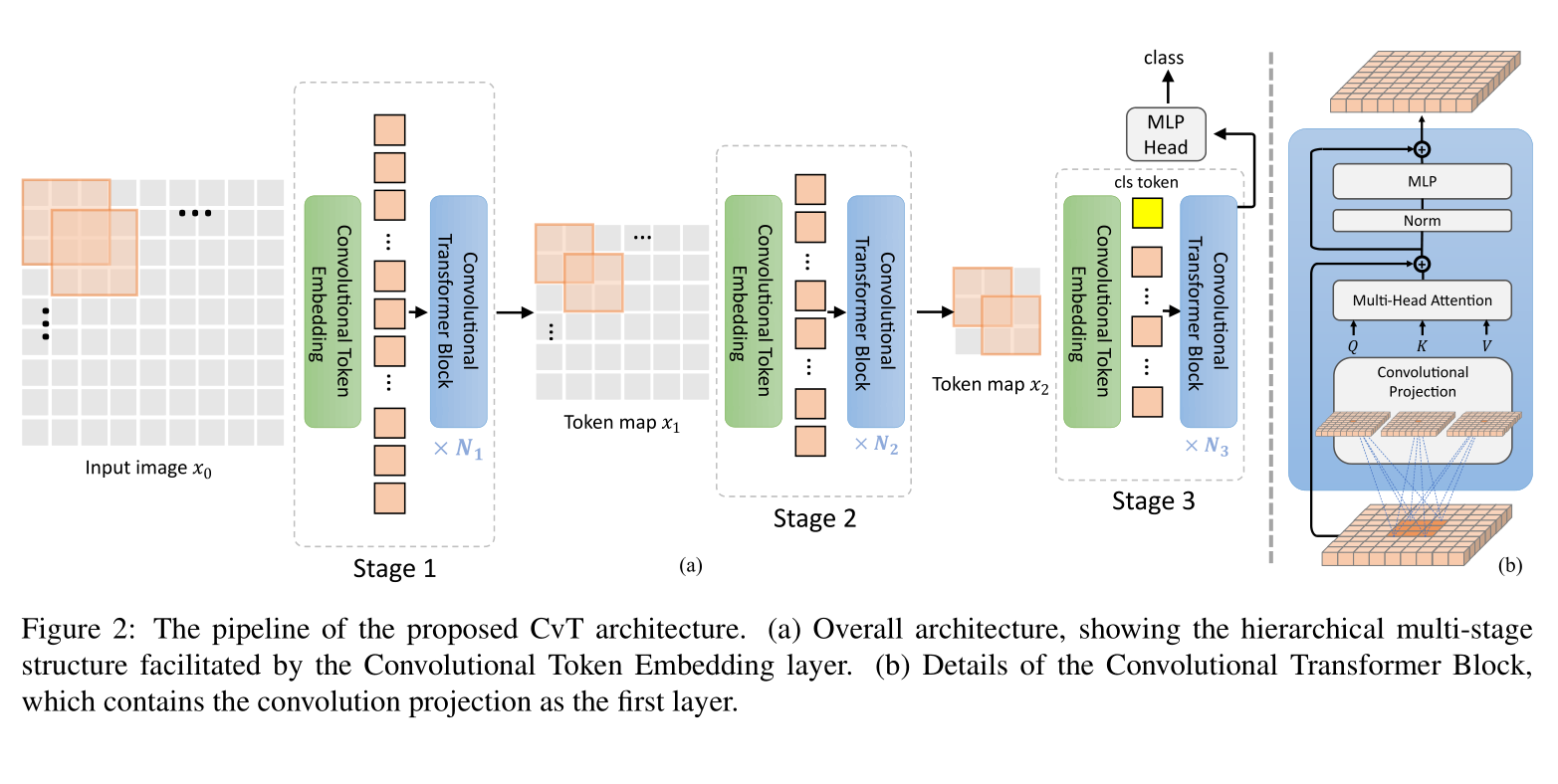
- CeiT [3]:replace the original patchy stem with convolutional stem and add depth-wise convolution to FFN layer, which obtains fast convergence and better performance.
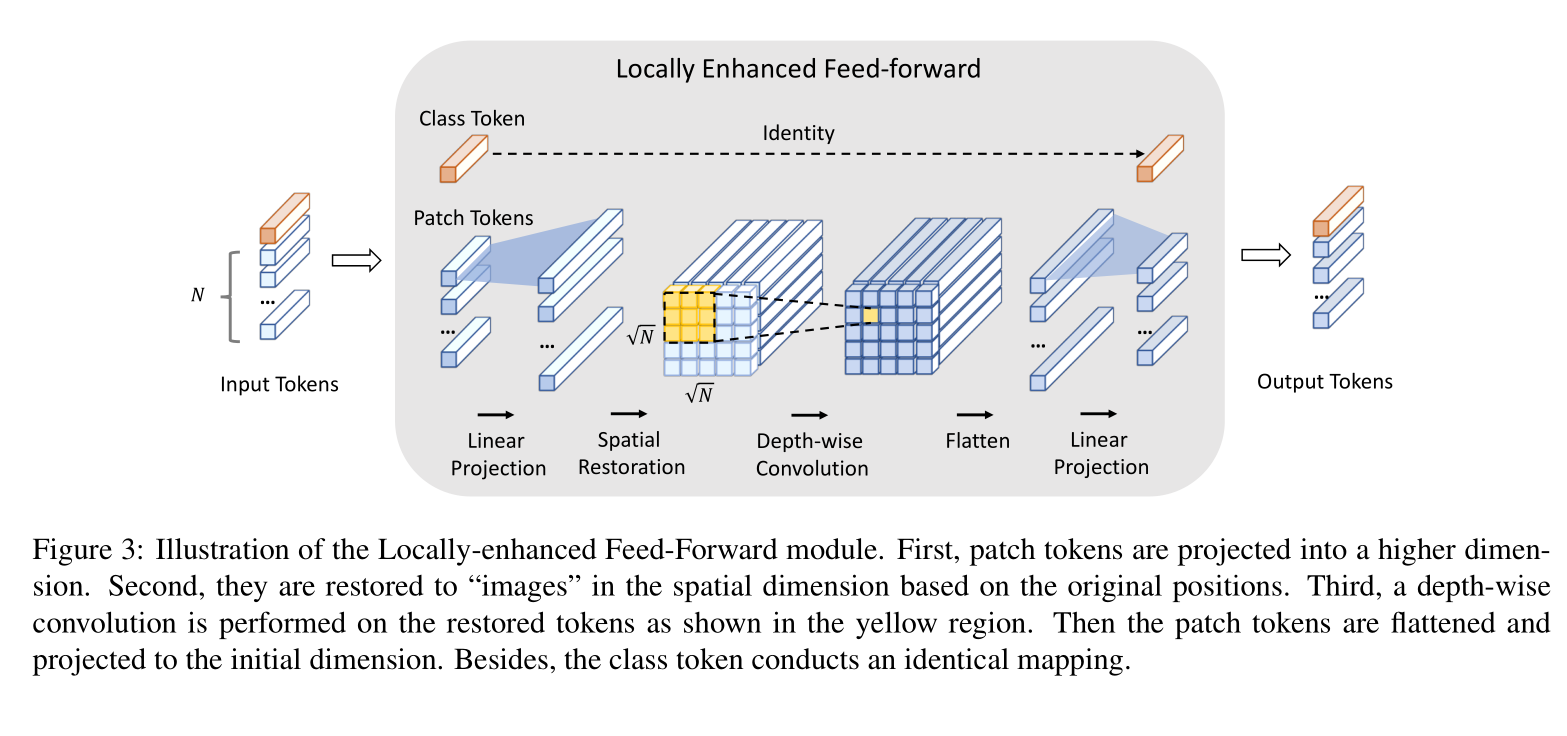
-
3. 方法
3.1 Unified Search Space
搜索空间如下图所示。
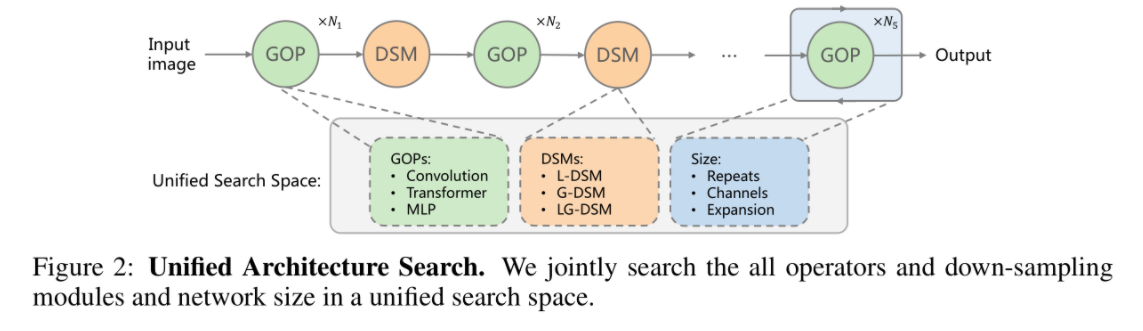
- GOP (General Operations):包含 Convolution, transformer,和 MLP。三种操作都之采用了类似inverted residual的设计方式,即先把原来的通道数c 通过映射扩大ec,然后在通过映射还原为 c,各操作公式如下:
- conv: \(y=x+op(x),\) 其中 \(op(x) = Proj_{ec\rightarrow{c}}(Conv(Proj_{c\rightarrow{ec}}(x)))\)
- transformer: \(y=y'+FFN(y')\),其中 \(y'=x+SelfAttention(x)\), \(FFN(y')=Proj_{ec\rightarrow{c}}(Conv(Proj_{c\rightarrow{ec}}(y')))\)
- MLP: \(y=y'+FFN(y')\),其中 \(y'=x+MLP(x)\), \(FFN(y')=Proj_{ec\rightarrow{c}}(Conv(Proj_{c\rightarrow{ec}}(y')))\)
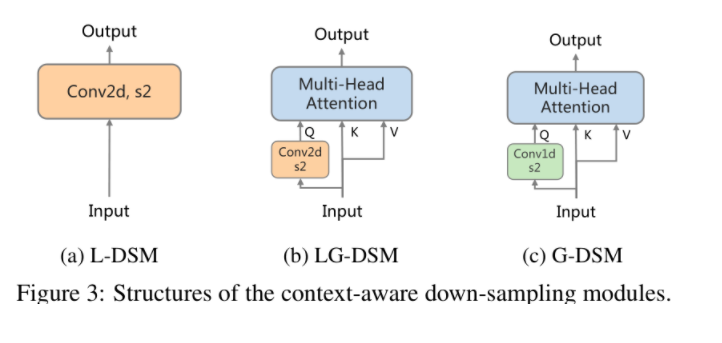
- DSM (Down-sampling Modules)
- L-DSM: 这个就是常规的下采样模块,比如stride=2的卷积操作或者 max-pooling。这些是对local context做下采样
- LG-DSM: 是局部和全局信息都会考虑的下采样模块。可以看到下采样是通过一个stride=2的卷积操作实现的,这里应该就是提取的local context。而attention机制呢就是一个全局的信息了。因为是2d卷积,所以需要先把input reshape成spatial grid,卷积计算完之后再flatten成原来的形状。
- G-DSM:和LG-DSM的区别就是用了1d的卷积操作,但是论文里并没有解释为什么这个时候就不会保留local context了。
完整的搜索空间参数设置如下:
- GOP:
- e (通道数expansion比例):
- 模型是基于efficientnet搜索的,
- 通道 channel缩放比例搜索空间:
- 堆叠个数 repeats:
- 总共有 K=5 个stages,每个stage的搜索空间大小是 (#channels * #repeats) 5*5=125
3.2 搜索算法
搜索算法基于强化学习 PPO算法,所有候选操作借鉴 Fnas: Uncertainty-aware fast neural architecture search [4] 的做法把搜索空间映射成了一组tokens。论文也没有给很多细节,感兴趣的可以看看FNAS那篇论文。
4. 实验结果
4.1 模型结构
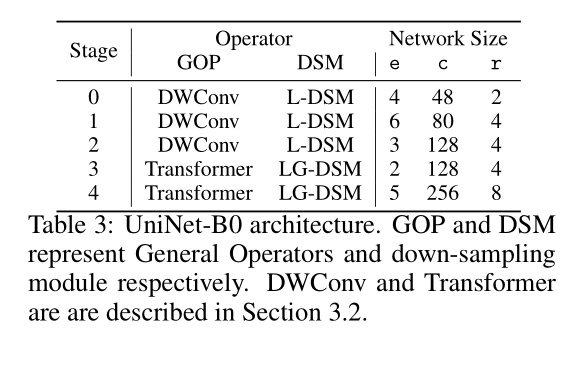
搜素到的模型结构如下表,可以看到每个stage的GOP都是固定的,这样一来搜索空间其实要少很多了,本来还以为是每一层的操作都要搜索。不过可以看到的是shallow stage采用的都是卷积操作,DSM也是传统的L-DSM(即stride=2的卷积层),可以理解成,浅层还是需要卷积来提取特征。
到了深层,GOP就选了Transformer和LG-DSM,可以理解成此时模型倾向于去提取全局的信息,这个也比较符合直觉。
不过有意思的是MLP貌似被遗忘在角落了。。。
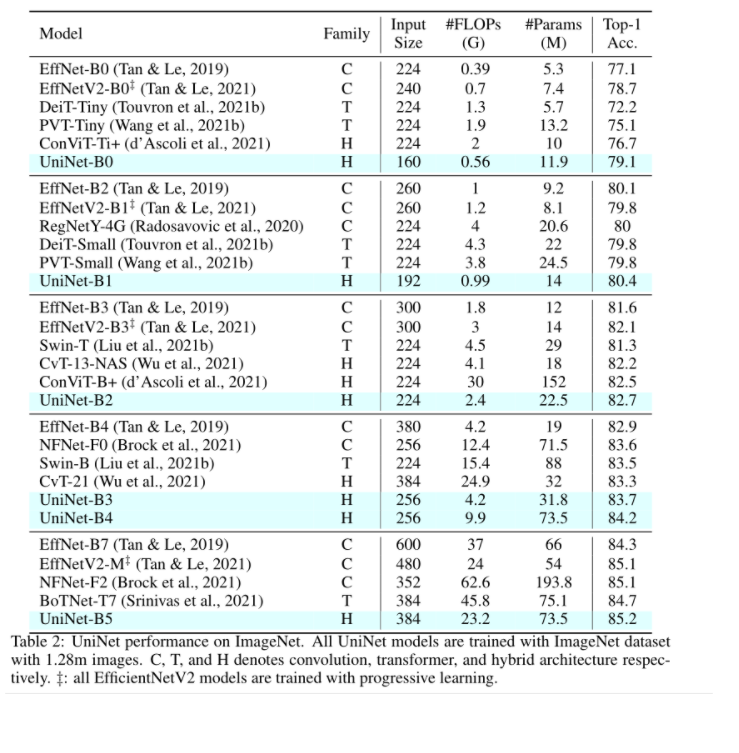
4.2 ImageNet上的结果
结果一个字:好。就完事了hhh
5. Ablation Study
作者做了实验去证明他们提出的 GOP和 DSM模块的有效性。
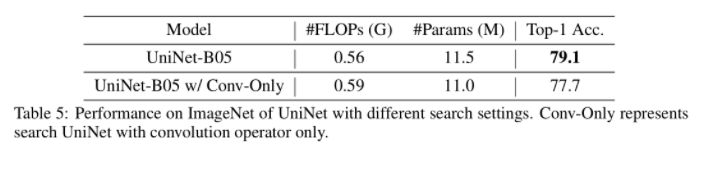
5.1 GOP vs. 纯Conv
可以看到用GOP比纯Conv高了1.4个点。
5.2 不同DSM模块的有效性验证和迁移性实验
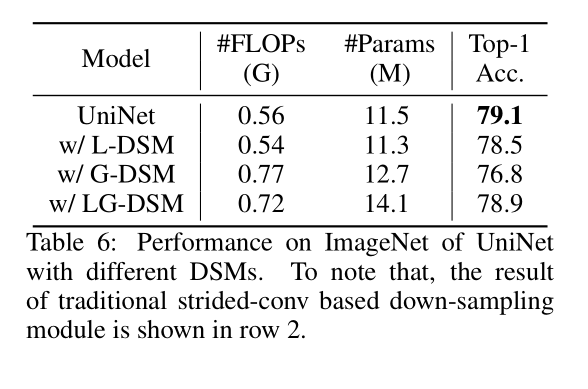
Table 6 对比了将 DSM全都替换成某一种下采样模块后模型的性能变化,可以看到如果替换成 G-DSM后性能掉的最多,而LG-DSM性能保持的还不错,但是FLOPs和参数量都有一定的增加。L-DSM效果也还不错的亚子
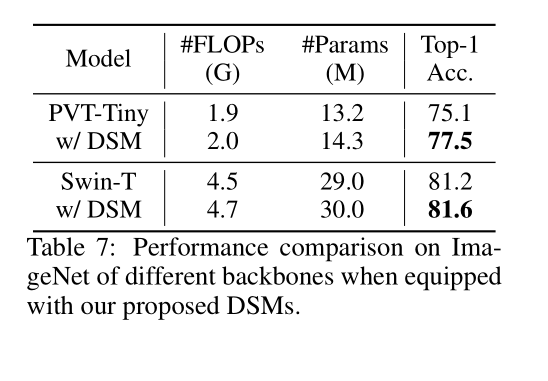
作者还将DSM模块放到了Swin-Transformer (ST)和PVT-Tiny 这些模型上去,这两个模型都是总共由4个stage组成,所以作者把前两个stage的下采样模块替换成了L-DSM,最后两个stage替换成了 LG-DSM,结果如Table 7所示,可以看到都有一定的性能提升。
References
- [1] St´ephane d’Ascoli, Hugo Touvron, Matthew Leavitt, Ari Morcos, Giulio Biroli, and Levent Sagun. ConViT: Improving vision transformers with soft convolutional inductive biases. arXiv preprint arXiv:2103.10697, 2021.
- [2] Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Yuan, and Lei Zhang. CvT:
Introducing convolutions to vision transformers. arXiv preprint arXiv:2103.15808, 2021. - [3] Kun Yuan, Shaopeng Guo, Ziwei Liu, Aojun Zhou, Fengwei Yu, and Wei Wu. Incorporating convolution designs into visual transformers. arXiv preprint arXiv:2103.11816, 2021.
- [4] Jihao Liu, Ming Zhang, Yangting Sun, Boxiao Liu, Guanglu Song, Yu Liu, and Hongsheng Li. Fnas: Uncertainty-aware fast neural architecture search. arXiv preprint arXiv:2105.11694, 2021a.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号