真的超详细又好懂的梯度下降优化算法概览
参考 https://ruder.io/optimizing-gradient-descent/ 。
本文不是简单地翻译,而是真的花了一天的时间和心思来写,这一过程中我也重新复习了一遍,而且对不太容易理解的地方都做了详细的解释和说明,如果看了本文还不清楚,那。。。那你就来我公众号后台私信我交流!!!记得加个关注,最好是打赏支持一下哈哈哈,共勉!
1. 为什么有了Mini-batch SGD还不满足?
朴素(Vanilla) mini-batch梯度下降优化算法虽然在大多时候都够用,但是还有不少问题为解决:
- 我们很难选择一个合适的学习率。因为太小的话收敛太慢,太大则可能会使得损失函数在局部最低点震荡(fluctuate)甚至是不收敛。
- 学习率不能根据数据集的特点灵活变动。虽然我们有时会使用learning rate scheduler来调整学习率,但是调整的规则需要事先定义好。
- 所有的权重使用的是同样的学习率。如果我们的数据是sparse的,或者说数据特征之间的频率 [1] 差别很大,我们肯定不希望他们的更新幅度保持一样。
- 另一个很难解决的问题是极端情况下的非凸损失函数。常说的陷于局部最优点倒是其次,鞍点(saddle point) 才是最难解决的问题,因为鞍点附近的梯度接近于0,此时常规的SGD算法很难逃出鞍点。
因此为了解决这些问题,或者说是挑战,有很多改进版的优化算法被相继提出。
下面我会尽可能直观地对这些改进算法进行介绍。
2. Momentum
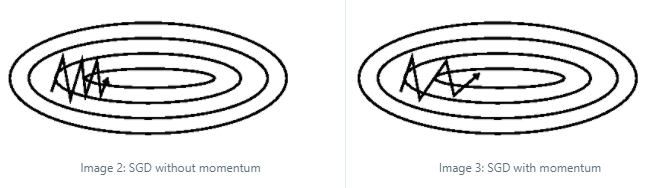
在介绍结合Momentum的优化器时,经常能看到如上两张图。一般的解释是Vanilla SGD会在ravine(峡谷)区域震荡的特别厉害,加了momentum之后就会改善很多。其实基于上面的图我是不太理解这个所谓的震荡是什么意思,以及为什么它就震荡了,所以我画了下面的图帮助理解。
Ravine的定义 [2] 是:Ravines are areas where the surface curves much more steeply in one dimension than in another.
黑色箭头表示优化方向和步长,可以看到相比于下半段,上半段的红色曲线部分变化幅度更加陡峭,因此SGD的更新也是一会朝上一会朝下,这就是所谓的震荡。到了下半段之后,红色曲线平缓一些了,所以黑色箭头的方向也都是朝下。
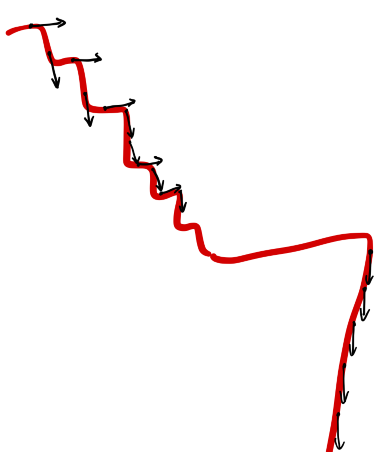
但是从全局的角度来看,上半段的震荡式更新很慢,Momentum的提出就是为了帮助SGD在相关方向上加速,从而抑制震荡(dampen oscillations)。
Momentum计算公式如下:
可以看到相比于公式(1),Momentum会把之前的更新幅度也考虑进来。我们举一个具体的例子来帮助理解。
假设第一次更新幅度\(v_0=0.6\)(因为第一次没有\(v_{t-1}\),所以就等于梯度值)。也就是说第一次更新方向是正方向,步长是0.6。
第二次的梯度值是 -0.2,如果是朴素SGD,那么就会往回走0.2,但是因为因为了momentum,那么此次的更新幅度就是 +0.34,也就是说还是会继续往正方向更新。
到了第三次,梯度值为 -0.8, 此时总的更新幅度变成了 -0.494,更新方向发生了改变。
3. Nesterov accelerated gradient
我们可以把Momentum优化器简单理解成一个在山坡上滚动的球,如果山坡一直是朝下的,那么小球的速度会越来越快。但是这样就会有一个新的问题,如果突然有一段很长的上升的坡,那么小球则会因为惯性冲上去,这显然是我们不想要的。

Nesterov accelerated gradient (NAG) [3] 的解决思路是让这个小球能够意识到自己大概处在什么位置,从而能预测在上升坡到来之前先减慢速度。
NAG在Momentum的基础上做了很小的改动就能实现上面的想法,公式如下:
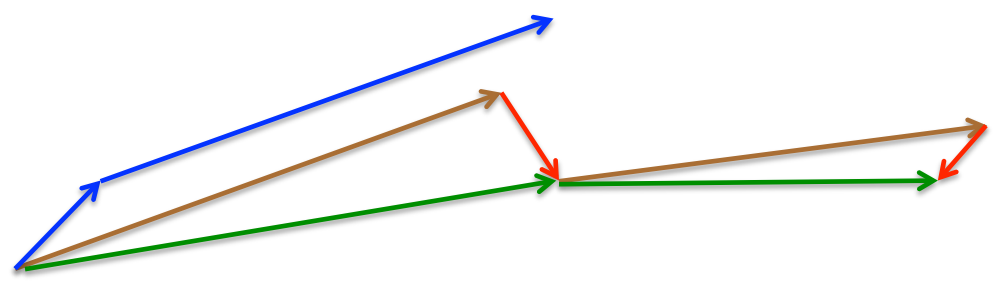
可以看到变化的地方只是把\(\theta\)换成了\(\theta - \gamma v_{t-1}\),这样做是什么意思呢?我们结合下图[4]来理解。
短一点的蓝色箭头表示当前时刻的梯度值,长一点的蓝色箭头表示Momentum计算得到的累积梯度(即\(v_{t-1}\))。NAG首先是基于上一时刻的梯度对参数进行计算(棕色箭头,其与长蓝色箭头平行),之后基于该点计算用于纠正的梯度值(红色箭头),最后总的更新方向和幅度就是绿色箭头。
4. Adagrad
前面提到的Vanilla SGD,SGD-Momentum,NAG都是采用同样的学习率来更新所有参数。Adagrad则可以对不同的参数使用不同的学习率进行更新:对于那些出现频率较多出现(frequently occuring)的特征会使用较小的学习率,而对那些较少出现的特征使用较大的学习率。因此,Adagrad十分适合处理sparse data。
下面介绍Adagrad的计算方式,首先给定符号定义:
- \(\theta\)表示所有的参数,\(\theta_i\)表示某一个参数。Adagrad是对每一个参数采用不同的学习率。
- \(g_t\)表示在\(t\)时刻的梯度,而\(g_{t,i}\)则表示\(t\)时刻每一个参数\(\theta_i\)对应的梯度,即\(g_{t,i}=\eta \nabla_\theta J( \theta_{t,i})\)
那么Vanilla SGD的表达形式则是:
Adagrad对上面公式中的\(\eta\)做了修正:
\(G_{t} \in \mathbb{R}^{d \times d}\)是一个对角矩阵,对角线上的元素\(G_{t, ii}\)是从初始时刻到t时刻为止,所有关于\(\theta_i\)的梯度的平方和,即\(G_{t, ii}=\sum_{k=0}^{t-1} \sqrt{G_{k, ii}}\)。 \(\epsilon\) 是噪声值,通常大小为\(1e-8\),主要是为了避免分母为0。有实验表明,如果不计算平方根,Adagrad的效果会很差。
上面的式子是针对每个元素的计算方式,下面我们使用矩阵计算( \(\odot\) 表示矩阵乘法)的表达方式推广到所有元素,即
使用Adagrad的主要优点是我们无需在手动调整学习率,一般来说只需要把学习率设置为0.01就好了,不再需要调用lr scheduler。
Adagrad的缺点也很明显,由于分母是从初始时刻到t时刻所有梯度的平方和,也就是说分母会随着时间不断变大,那么一定时间后,分母会特别大,以至于学习率接近于0,此时更新幅度也基本上停止了,那么啥东西也没法学了。所以下面的Adadelta算法就是为了解决这个问题。
5. Adadelta
Adagrad是把前面所有时刻的梯度做了平方和的计算,那么一个很直观且naive的想法是我们只选取前\(W\)个时刻的梯度做平方和计算即可。
Adadelta的确采用了类似的做法,它借鉴了Momentum的思路,即当前时刻的滑动平均\(E[g^2]_t\)依赖于上一时刻的滑动平均\(E[g^2]_{t-1}\)和当前时刻的梯度值\(g_t\),即:
\(\gamma\)类似于Momentum term,通常设置在0.9左右。当\(\gamma=0.5\)时,上式就变成了梯度平方和。
那么Adadelta的参数更新公式为:
通常\(\sqrt{E[g^2]_t + \epsilon}\)也会简写成\(RMS[g]_t\), (RMS是root mean squared的缩写)
所以
此时Adadelta还是依赖全局学习率的,所以作者还进一步定义了另一个指数衰减平均,这次不是梯度平方,而是参数的平方的更新:
类似地有
最后通过一通骚操作(一阶近似Hessian方法 [5] )后,式(5.3)近似为如下:
至此,Adadelta介绍结束了,我们通过上式可以看到,学习率\(\eta\)消失了,换句话说有了Adadelta之后,我们甚至可以不用设置默认的学习率。(机器之心震惊体可以用起来了!!!)
6. RMSprop
RMSprop是由Geoff Hinton大佬在其Coursera课堂的课程中提出的,换句话说它还是一个尚未发表的自适应学习率的算法,
RMSprop和Adadelta几乎是在在相同的时间里被独立的提出,都是为了解决Adagrad的极速递减的学习率问题。RMSprop可以算作Adadelta的一个特例,即式子(5.3)。也就是说,RMSprop还是依赖于全局学习率,非常适合处理非平稳目标(对RNN效果会比较好)。
常用的参数设置如下:
Hinton建议将\(\gamma\)设置为0.9,对于学习率\(\eta\),推荐设置为0.001。
7. Adam
终于到Adam神器了,其全称是Adaptive Moment Estimation [6]。 Adam也是会给每个参数计算动态的学习率。
除了像Adadelta和RMSprop那样需要计算过去平方梯度\(v_t\)的指数衰减平均值外,Adam还需要类似于Momentum的做法来保存过去梯度\(m_t\)的指数衰减平均值,简单理解就是Adam = RMSprop + Momentum。
不同论文的符号不一样,所以看起来会有点混乱,这里Adam的\(v_t\)就是前面Adadelta中的\(E[g^2]_t\),\(m_t\)就是Momentum公式中的\(v_t\)。\(\beta_1,\beta_2\)则类似前面的\(\gamma\)
一般而言,一个向量通常是初始化为0向量,但是在这里,如果我们也把\(v_t,m_t\)初始化为\(\vec{0}\),那么有如如下推导 [7](下面的推导很多教程根本都不提!!!),
所以我们得到t时刻
进一步可以得到
第一行到第二行是一个近似,所以后面需要加一个误差值\(\zeta\)。最后我们可以看到\(E[m_t]\)和\(E[g_t]\)之间有一个偏差\(1-\beta_1^t\),所以为了修正偏差(\(v_t\)修正同理),有
通常\(\beta_1=0.9, \beta_2=0.999,\eta=10^{-8}\)最后将\(\hat{m}_{t}\)和\(\hat{v}_{t}\)代入公式(6)后,Adam梯度更新算法公式为
Adam的python实现代码如下
for t in range(num_iterations):
g = compute_gradient(x, y)
m = beta_1 * m + (1 - beta_1) * g
v = beta_2 * v + (1 - beta_2) * np.power(g, 2)
m_hat = m / (1 - np.power(beta_1, t))
v_hat = v / (1 - np.power(beta_2, t))
w = w - step_size * m_hat / (np.sqrt(v_hat) + epsilon)
8. AdaMax
AdaMax是在Adam的基础上做了一丢丢的改进。由公式(7.1)可以知道Adam在计算\(v_t\)时采用的\(\ell_2\) norm,即
那么很自然地我们会想是否可以推广到任意的norm呢?所以AdaMax的做法是
注意,上式中\(\beta_2\)也引入了\(\ell_p\) norm。当\(p\)值较大时,norm计算起来不稳定,所以这也是为什么1-norm和2-norm是最常用的。但是AdaMax作者发现\(\ell_\infty\)表现更好,所以这也是为什么叫做AdaMax了。
为了避免和Adam混淆,我们使用\(u_t\)来表示无穷范数约束的\(v_t\),即
将\(u_t\)代入公式(7.5)可得
推荐的参数设置如下:
\(\eta=0.002,\beta_1=0.9,\beta_2=0.999\)
9. Nadam
Adam = RMSprop + Momentum
Nadam [8] = NAG + Adam
9.1 NAG→Nadam
我们先介绍如何引入NAG算法。不过在此之前我们回顾一下Momentum更新算法的公式:
所以momentum的更新方向是 前一时刻的momentum 加上 当前时刻的梯度 这两个矢量的方向。
之后的NAG算法对更新方向做了修正,解决momentum刹不住车的问题。公式如下,可以看到上一时刻的momentum \(m_{t-1}\)被使用了两次,一次是用来更新\(g_t\),一次是用来更新\(\theta_{t+1}\)。
NAG的思想主要是在计算梯度\(g_t\)时使用了未来位置:\(\theta_t - \gamma m_{t-1}\)。换句话说,只要计算梯度时考虑了未来的因素,那应该也能达到NAG的效果 [9]。 因此在Nadam中,\(g_t\)的计算仍然使用原来的计算方式,即\(g_t = \nabla_{\theta_t}J(\theta_t)\),但是在迭代更新\(\theta_{t+1}\)时则使用未来时刻的momentum \(m_{t+1}\)也就行了,所以引入NAG后的计算公式为:
(9.3)的第3行你可能会好奇为什么未来时刻的momentum \(m_{t+1}\approx \gamma m_{t} + \eta g_t\),推理如下:
- 因为 \(m_t = \gamma m_{t-1} + \eta g_t\),那么\(m_{t+1} = \gamma m_{t} + \eta g_{t+1}\)
- 假设连续两次的梯度变化不大,那么则有\(g_{t+1}\approx g_t\)
- 所以\(m_{t+1}\approx \gamma m_{t} + \eta g_t\)
所以(9.1)变成(9.3)并不是简单地理解成把\(m_{t-1}\)替换成\(m_t\)。不过上面的分析也可以知道Nadam使用的场景是梯度不会发生剧烈变化,否则上边的式子就不成立了。
9.2 Adam→Nadam
由9.1节可以知道,引入NAG的方法简单理解就是在更新\(\theta_{t+1}\)的时候,把\(m_{t-1}\)替换成\(m_t\)(注意,只是为了方便后面那说明才这么写,其实并不是简单替换,9.1节最后已经说明过了),那么下面就是把Adam引入进来,在介绍之前还是回顾一下Adam的计算规则:
简单理解,引入NAG时把\(m_{t-1}\)替换成了\(m_t\),同样地我们也可以对(9.4)最后一行做同样操作后则可以得到Nadam最终的计算规则了:
码字不易,给个赞或打个赏吧。有问题欢迎公众号后台讨论或者评论区留言,谢谢!
Sutton, R. S. (1986). Two problems with backpropagation and other steepest-descent learning procedures for networks. Proc. 8th Annual Conf. Cognitive Science Society. ↩︎
Nesterov, Y. (1983). A method for unconstrained convex minimization problem with the rate of convergence o(1/k2). Doklady ANSSSR (translated as Soviet.Math.Docl.), vol. 269, pp. 543– 547. ↩︎
Source: G. Hinton's lecture ↩︎
自适应学习率调整:AdaDelta: https://www.cnblogs.com/neopenx/p/4768388.html ↩︎
Kingma, D. P., & Ba, J. L. (2015). Adam: a Method for Stochastic Optimization. International Conference on Learning Representations, 1–13. ↩︎
https://towardsdatascience.com/adam-latest-trends-in-deep-learning-optimization-6be9a291375c ↩︎
Dozat, T. (2016). Incorporating Nesterov Momentum into Adam. ICLR Workshop, (1), 2013–2016. ↩︎
从 SGD 到 Adam —— 深度学习优化算法概览(一)
https://zhuanlan.zhihu.com/p/32626442 ↩︎

 浙公网安备 33010602011771号
浙公网安备 33010602011771号