华为诺亚AutoML框架-Vega:(2) 代码结构
Vega已更新到1.2版本,所以本教程以1.2版本为准进行介绍。
Vega框架链接:https://github.com/huawei-noah/vega
Vega论文:VEGA: Towards an End-to-End Configurable AutoML Pipeline[1]
Vega QQ讨论群: 833345709
Vega是基于Pipeline的设计思路,这和我们实验室写的AutoML综述思路不谋而合,感兴趣的也可以看看我们的论文:AutoML: A Survey of the State-of-the-art[2]

整体代码架构
之前的华为诺亚实验室AutoML框架-Vega:(1) 介绍 已经介绍了相比于其他的AutoML框架, Vega框架的优点和特性。本文将从代码结构的角度来介绍Vega,帮助大家对Vega有一个全局的了解,主要起到一个帮助索引查找的作用。
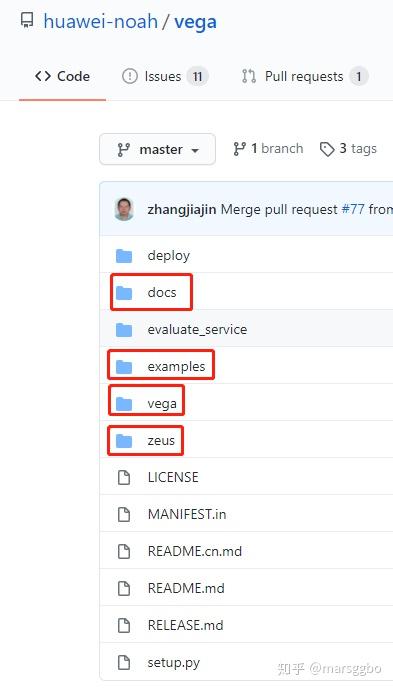
普通开发者用户需要特别关注上图圈出的4个目录:
docs: 该目录下包含丰富的中英文文档说明,不同算法的设置和用法可以通过查阅文档就能轻松解决examples:该目录下包含所有内置的开箱即用的算法,你可以进入该目录来选择运行指定的算法,后面会介绍运行方法vega:很显然,这是Vega的核心部件。zeus:这是一个涵盖数据集、训练、评估等阶段的全Pipeline通用组件,将Pytorch、TensorFlow和MindSpore三个框架做了整合,用户在写好代码之后可以一键切换不同框架。因此如果你想测试不同框架的性能,Zeus一定能助你一臂之力。
看到这你可能会想为什么要叫 Vega呢? Vega名字官方的解释[3]如下:
“ Zhinü (织女, the weaver girl, symbolizing the star Vega) is a fairy in ancient Chinese myths and legends. She's responsible for providing the fairy's clothes and clouds. We hope that Vega will provide AI research and application infrastructure like a weaver girl.
织女是中国古代神话传说中的仙女,织女类比织女星。她负责提供仙女的衣服和云彩。我们希望织女星能像织女一样提供人工智能研究和应用基础设施。
”
那Zeus也很好理解了,因为Zeus是古希腊神话中的众神之王,这里Zeus将三个流行深度学习框架做了深度整合,提供了基础的深度学习训练Pipeline。
Docs提供了什么?
Docs目录下提供了中英双语版本的文档方便用户查阅,这里以中文文档进行介绍。
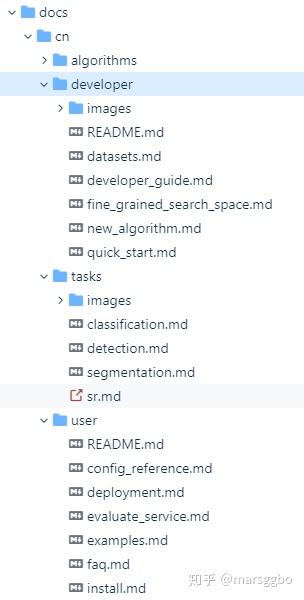
由上图可以看到docs目录主要分成四个部分:
user: 该目录下的内容主要介绍了Vega初学者需要注意的问题,介绍了Vega中引入的新的概念README.md: 对user目录的总结说明config_reference.md: Vega的所有任务都是由yaml文件配置的,该文件主要介绍了如何在yaml文件中配置不同组件(数据集、算法等)。deployment.md:介绍如何部署集群evaluate_service.md: 介绍如何部署服务器的评估服务examples.md: 介绍内置算法的在不同阶段的输入(如配置文件和预训练模型)和输出(如保存日志和checkpoints)faq.md:常见问题和解决办法install.md:Vega安装教程
developer:该目录下的内容主要介绍开发者应当如何实现自定义的功能,如自定义数据集、模型、NAS算法等。developer_guide.md:介绍了Vega的搜索空间、搜索算法和参数配置等基本概念和使用方法datasets.md: 介绍如何自定义数据集fine_grained_search_space: 介绍Vega框架的细粒度搜索空间概念和自定义方式new_algorithm.md:介绍如何自定义算法
algorithms: 该目录下包含了所有Vega框架下内置的算法介绍。tasks:该目录对几个常见的CV任务进行介绍不同场景下的使用。
Zeus代码架构
前面已经提到过了,Zeus是一个提供基础组件的框架,所有组件采样注册机制,因此我们可以通过修改yaml文件设置即可调用不同的组件(如数据集、模型等)。
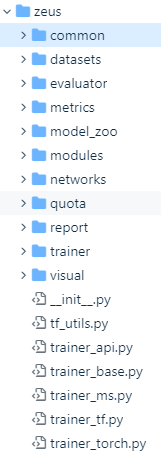
Zeus的代码结构如上图所示,每个模块的作用其实可以看名字也能大概知道,下面对各个模块做一个简单的介绍,后续的教程会做进一步的分析。
common
该目录下主要提供了各种参数配置组件和注册工厂。
config.py: 新建了Config类,该类继承自dict,能够灵活处理yaml、json、py等不同格式的配置文件,同样也可以直接传入一个字典。其代码大致示例如下:
1 class Config(dict): 2 def __init__(self, *args, **kwargs): 3 """Init config class with multiple config files or dictionary.""" 4 super(Config, self).__init__() 5 for arg in args: 6 if isinstance(arg, str): # 可以传入多个配置文件的路径 7 if arg.endswith('.yaml') or arg.endswith('.yml'): 8 ... 9 elif arg.endswith('.py'): 10 ... 11 elif arg.endswith(".json"): 12 ... 13 if kwargs: # 也可以传入一个字典进行处理 14 ...
config_serializable.py: 该文件提供了ConfigSerializable类,该类的作用是提供将类序列化为Config的作用,比如我们定义如下类
class MyDatasetConf(ConfigSerializable): data_dir = './data/cifar10' batch_size = 32 ...
之后我们可以只需要执行如下命令即可把MyDatasetConf这个类转化成Config类。
MyDatasetConf.to_json()user_config.py:该文件中定义了一个UserConfig类,该类是单例模式,可以简单理解成是一个全局信息,因此在整个pipeline过程中都由这个类管理所有配置信息。general.py: 该文件定义了通用的配置信息,如 日志信息、集群配置、任务ID、Backend (可以是Pytorch、TensorFlow或者Mindspore)等。file_ops.py主要是对常用的文件操作做了封装,提供了更加便捷的操作task_ops.py主要管理每次task的ID、日志路径、checkpoint路径等信息class_factory.py:该文件内定义了两个非常重要的类,即ClassType和ClassFactory,Vega的注册机制就是靠这两个类来管理和实现的。ClassType:该类预先定义好了可以注册的组件类别,部分代码示例如下:
class ClassType(object): """Const class saved defined class type.""" DATASET = 'dataset' # 数据集 NETWORK = "network" # 模型 TRAINER = 'trainer' # 训练器 METRIC = 'trainer.metric' # 指标(如accuracy) OPTIMIZER = 'trainer.optimizer' # 优化器 LR_SCHEDULER = 'trainer.lr_scheduler' # 学习率scheduler LOSS = 'trainer.loss' # 损失函数 EVALUATOR = 'evaluator' # 评估器基类,会自动根据设置调用下面不同类别的评估器 GPU_EVALUATOR = 'evaluator.gpu_evaluator' # GPU评估器,即在GPU上对模型等设置进行评估 HAVA_D_EVALUATOR = 'evaluator.hava_d_evaluator' # 华为自研达芬奇芯片评估器 DAVINCI_MOBILE_EVALUATOR = 'evaluator.davinci_mobile_evaluator' # 达芬奇移动端评估器 SEARCH_ALGORITHM = 'search_algorithm' # 搜索算法 PIPE_STEP = 'pipe_step' # GENERAL = 'general' # 通用参数配置 TRANSFORM = 'dataset.transforms' # 数据增强 CALLBACK = 'trainer.callback' # Callback (后面教程会介绍) CONFIG = 'CONFIG' # CODEC = 'search_algorithm.codec' # 编码解码 (比如进化算法会把模型编码成01序列,之后也需要解码) QUOTA = 'quota' # 配额(比如搜索会对时间和flops有要求,可以起到过滤筛选的作用)
ClassFactory可以通过装饰器的方式来注册你想要复用的模块。如下面的代码示例,你自定义了一个数据集MyDataset和模型MyModel,你只需要在上面加上一行ClassFactory.register(<class type>)即可完成注册。
@ClassFactory.register(ClassType.NETWORK) class MyModel(...): ... @ClassFactory.register(ClassType.DATASET) class MyDataset(...): ...
注册之后,你只需要在yaml文件中将模型和数据集的名字改成MyModel和MyDataset,之后会根据名字自动调用对应的类。
modules、 networks、model_zoo
这三个模块提供的都是模型结构,看名字可能会觉得有点搞不清楚,区别在于
modules提供的是一些基础模块,Conv2D、MaxPool2d、ResBlock、StemBlock等等networks提供的通常是一个Zeus内置的完整的网络结构,比如MobileNetV3、FasterRCNN等model_zoo主要有两个作用- 将
torchvision的模型进行了注册,也就是说你可以很方便地调用torchvision.models内置的模型,方法是在你想调用的模型名字前面加上torchvision_前缀即可。假如你想调用ResNet18,你只需要在yaml文件里把模型名称改为torchvision_resnet18。 - 提供了
ModelZoo类,你可以通过调用该类的ModelZoo.get_model(model_desc,pretrained_model_file)方法来得到指定模型, 其中model_desc是模型的描述字典信息,比如{'type':'torchvision_resnet18', 'num_classes':10},这样会自动生成一个ResNet18类,其输出类别是10;pretrained_model_file是预训练模型权重的路径。
trainer
trainer模块下主要有如下两部分组件:
- 一个是
callbacks,目前Zeus内置了丰富的Callback,如lr_scheduler,model_checkpoint,progress_logger(负责管理打印日志信息),model_statistics(计算模型参数量,FLOPS ,latency)等。这些Callback也支持注册机制,因此你可以灵活选择你需要的Callback。
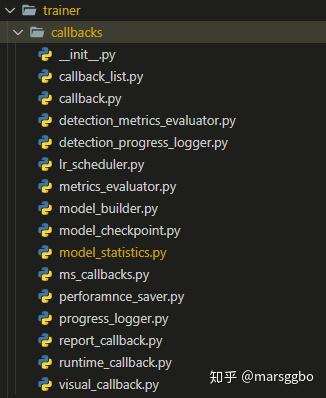
- 另一个是
modules,如下图示主要包含了losses,lr_scheduler,optimizer等。
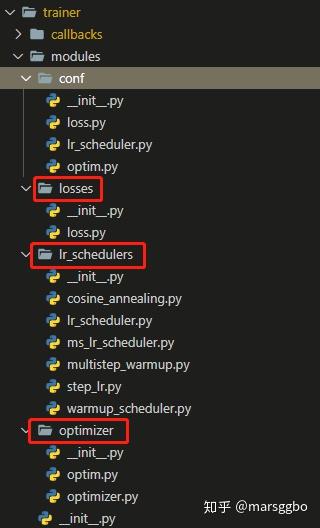
Zeus分别为Pytorch、TensorFlow、MindSpore三个框架实现了trainer组件,他们都继承自trainer_base.py里的TrainerBase类,该类实现了通用的参数初始化设置等操作。
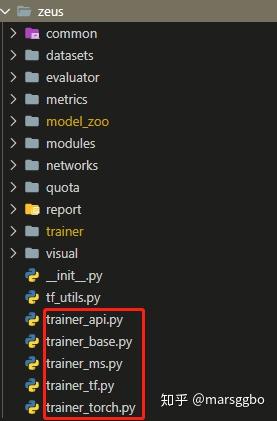
trainer_api.py则是将三个框架的trainer做了整合,会自动根据设置的Backend选择合适的trainer,代码示例如下:
# trainer_api.py @ClassFactory.register(ClassType.TRAINER) class Trainer(TrainerBase): """Trainer class.""" def __new__(cls, model=None, id=None, hps=None, load_ckpt_flag=False, model_desc=None, lazy_build=True, **kwargs): """Create Trainer clss.""" if zeus.is_torch_backend(): from zeus.trainer_torch import TrainerTorch trainer_cls = TrainerTorch elif zeus.is_tf_backend(): from zeus.trainer_tf import TrainerTf trainer_cls = TrainerTf else: from zeus.trainer_ms import TrainerMs trainer_cls = TrainerMs return trainer_cls(model=model, id=id, hps=hps, load_ckpt_flag=load_ckpt_flag, model_desc=model_desc, lazy_build=lazy_build, **kwargs)
Vega
下图是vega目录下的整体代码架构,可以看到很简单只有3个部分组成,下面开始介绍Vega的代码架构设计逻辑。
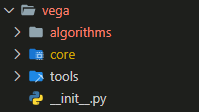
tools
- 提供了一系列的运行脚本,如
run_pipeline.py,full_train.py,benchmark.py,inference.py等 - 提供依赖包安装脚本,
install_pkgs.py
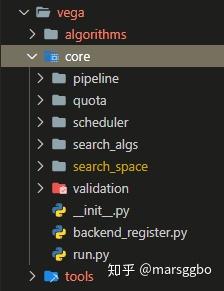
core
下图是core目录下的代码结构
Pipeline
Vega是基于Pipeline的设计思路,这和我们实验室写的AutoML综述思路不谋而合。下图是我们的综述论文中Pipeline示意图,Vega的实现方法则是把每个阶段视为一个PipeStep,通过讲这些阶段串联起来就可以很方便且灵活跑完所有阶段,而不再需要每个阶段跑完后,再手动运行下一个阶段代码。
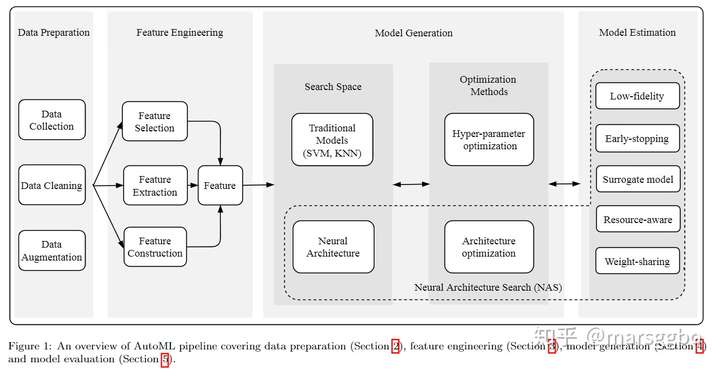
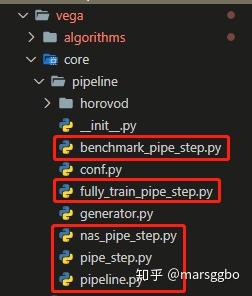
具体而言,整个pipeline由Vega的Pipeline类管理执行,另外Vega中的PipeStep类有三个子类:BenchmarkPipeStep, NasPipeStep和FullyTrainPipeStep,这些定义在vega/core/pipeline中。
为了方便理解,我把Pipeline代码做了简化如下进行介绍
class Pipeline: def run(self): for step_name in PipelineConfig.steps: # 遍历['nas', 'fully_train'] step_cfg = UserConfig().data.get(step_name) # 拿到对应step的参数设置 ... PipeStep().do() # 运行对应Step
可以看到会有一个for循环来遍历PipelineConfig.steps内存储的所有step名称,这个是由yaml文件中的pipeline定义的(如下图示)。
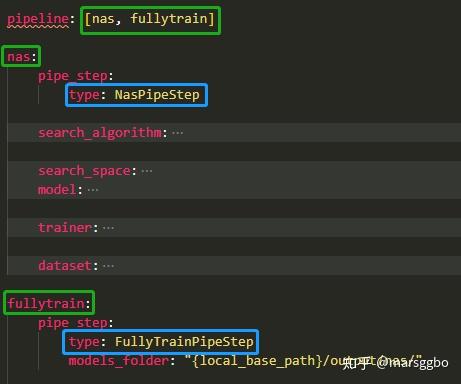
每次遍历会读取出对应名称的step参数,比如首先会把名称为nas的参数读取出来,其实你也可以设置为其他名字,这个名字主要是为了方便人理解,主要用于判断step类型的是上图中蓝色框的部分,因为不同类型的step会有不同的运行方法。
拿到参数后会运行PipeStep().do(),这里面的PipeStep()会通过设计好的__new__函数调用对应的step,例如NasPipeStep,之后会运行NasPipeStep内设置的do函数开始运行,这些细节会在后面的教程中做详细介绍。
search_algs和search_space
search_algs和search_space目录分别定义了搜索算法和搜索空间的基类,为避免文章累赘,这部分内容也会在后面的教程中做详细介绍。
backend_register.py
前面已经介绍过了Zeus将三个通用深度学习框架做了整合,vega下的backend_register.py作用就是设置指定的Backend和设备(如GPU、NPU等)。
在运行代码前必须设置好Backend,否则会报错。因为只有这样才能,才能知道应该调用哪个框架的模型结构。
run.py
这是Vega框架的运行入口,代码如下所示。可以看到在对参数进行验证处理后就会通过_run_pipeline()函数开始运行指定的Pipeline。
# vega/run.py def run(cfg_path): """Run vega automl. :param cfg_path: config path. """ if sys.version_info < (3, 6): sys.exit('Sorry, Python < 3.6 is not supported.') _init_env(cfg_path) _backup_cfg(cfg_path) _adjust_config() _run_pipeline()
微信公众号:AutoML机器学习

MARSGGBO♥原创
如有意合作或学术讨论欢迎私戳联系~
邮箱:marsggbo@foxmail.com
2020-11-21 10:44:27
参考资料
[1] VEGA: Towards an End-to-End Configurable AutoML Pipeline: https://arxiv.org/abs/2011.01507
[2] AutoML: A Survey of the State-of-the-art: https://arxiv.org/abs/1908.00709
[3] Vega名字官方的解释: https://github.com/huawei-noah/vega/issues/74

