AutoML综述更新 【AutoML:Survey of the State-of-the-Art】
论文: AutoML: Survey of the State-of-the-Art
下面这个网站会不断更新AutoML相关的论文,当然如果你的论文未被收录,你也可以手动上传你的论文让更多人看到:
https://marsggbo.github.io/automl_a_survey_of_state_of_the_art/
1、文章结构
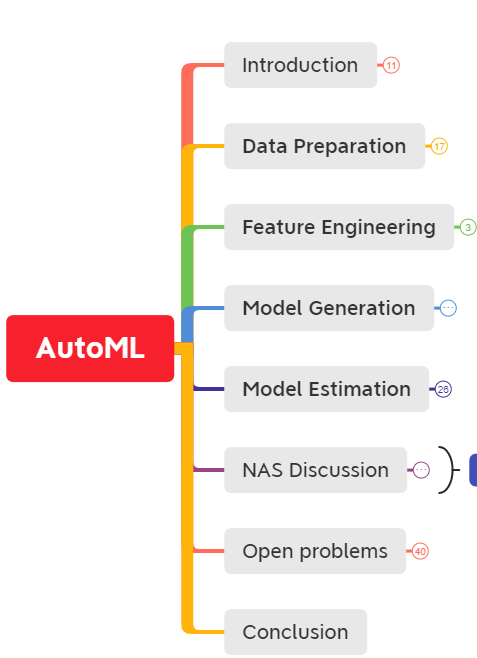
下面是整个AutoML的pipeline,全文也是围绕这个pipeline对AutoML技术做了回顾和总结。
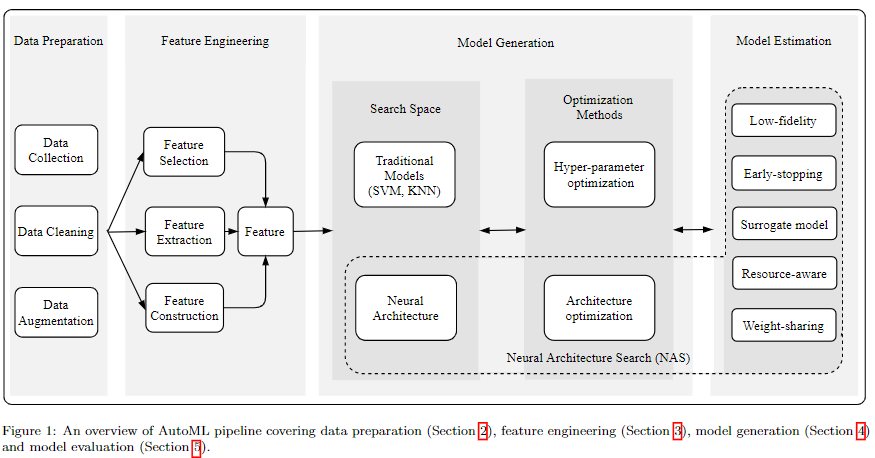
下表总结了目前现有的AutoML相关的综述,我们的survey涵盖了更广的范围,并且将2020年已发表在会议或期刊上的很多论文都整理在内。其他综述写的都很棒,都有很高的参考价值。
下面的内容会对论文做一个简单的总结,不会涉及到太多的细节,感兴趣的朋友可以移步最上面的链接阅读原文。
2、Data preparation
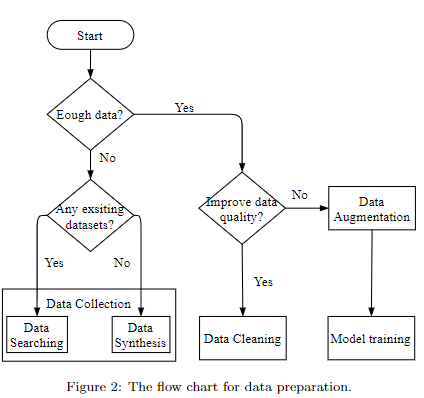
上图是数据准备的流程图,涉及到的技术有:
- data searching
- data synthesis
- data cleaning
- data augmentation
- 这里介绍了一些自动数据增强的算法,即不需要人工设计,而是通过算法为特定任务设计一套数据增强操作。
具体细节可参阅原文。
3、Neural architecture search (NAS)
由前面的pipeline可以看到NAS技术主要有三个部分组成:
- search space:定义了网络结构的范式。我们论文主要关注神经网络架构,因此像SVM这种传统机器学习模型的search space我们没有做过多介绍。
- architecture optimization (AO): 定义了如何搜索网络结构。在一些论文里也称作search strategy或search policy等,也有不少论文称之为architecture optimization,本文选择这个的原因也是为了和hyperparameter optimization (HPO) 统一起来,即二者都是优化算法,只不过HPO一般是指优化像学习率或者batch size这样的超参数,而AO则是优化网络结构。
- model estimation:找到一个模型后,我们需要评估它以此来判断模型的好坏。
在之前版本里,我们将architecture也视为了超参数的一种,这个可能会引起歧义,而且目前NAS社区大多数论文都将architecture和hyperparameter区分开来的,所以为了方便理解,该版本也对architecture和hyperparameter做了区分。
3.1 Search space
主要有如下四种search space:
- entire-structured search space
直接设计出一个完整的网络结构,即每一层代表一个操作,该操作是从预设定的search space里选择的;然后层与层之间可以跳跃连接。这样设计的主要问题是设计出来的模型缺乏可迁移性,不太好扩展。
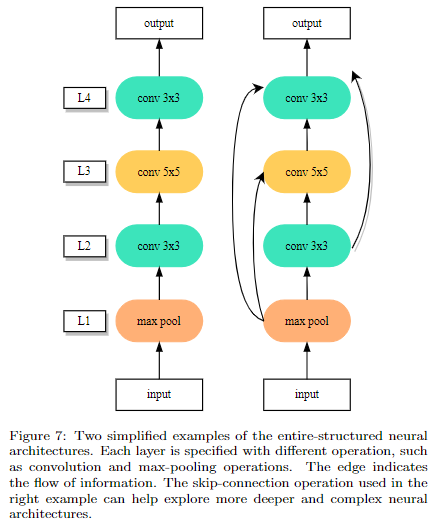
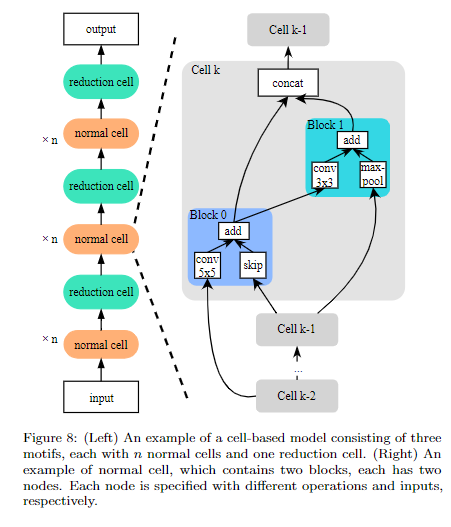
- Cell-based search space
为了解决上个方式的问题,Cell-based,顾名思义,就是先搜索出一个表现最好的cell结构,然后堆叠cell来得到最终的模型。
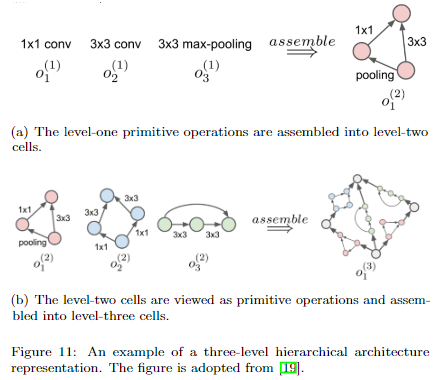
- Hierarchical search space
cell-based 有个缺点就是cell 结构其实是人为固定好的,比如你需要提前设置好一个cell是由几个node组成的。而且最后只是简单地堆叠重复的cell得到最终模型,这样的设计范式也是存在局限性的。下面两种搜索空间使得cell结构的可能性更多。
第一种是将cell分成若干个level,高level的cell由低level的cell组成
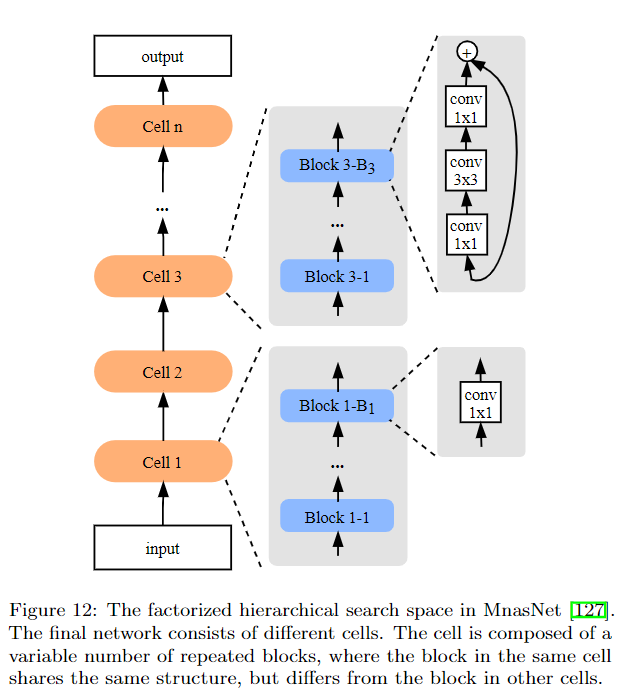
另一种是以MnasNet为代表的方法,即每一层是一个cell,每个cell由若干个block组成,block的数量是可以搜索的。另外每个cell内部的block结构是一样的,但是不同的cell之间的block是不一样的。
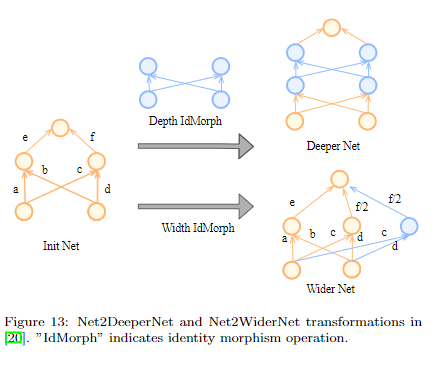
- Morphism-based search space
这种方式简单理解就是可以基于现有的模型进行扩展,比如模型加宽、加深,或者把某一个操作替换成其他操作等。
3.2 Architecture Optimization
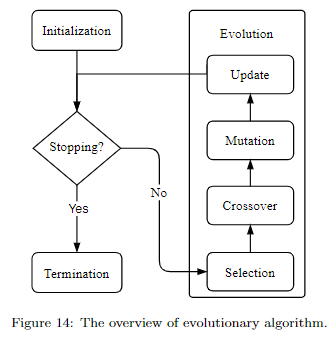
- Evolutionary Algorithm
进化算法其实就是借鉴的生物进化,主要包括四步:
- selection:选择父母网络,用于生成子网络
- crossover:可以简单理解成子网络获取父母网络的信息
- mutation:子网络的部分信息发生突变,这样可以得到更多种类的网络结构
- update:更新网络数量,因为生成的网络越多,消耗的资源也越多。而资源是有限的,所以需要控制网络总数,一般可以通过淘汰表现差的或老的来控制模型的数量。
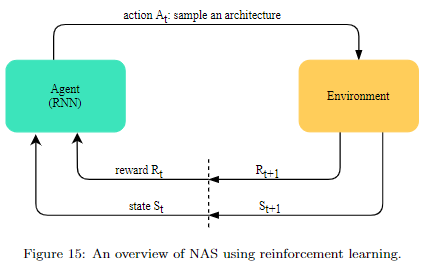
- Reinforcement Learning
如果对这类方法还不熟悉的,建议阅读ENAS论文或之前的文章论文笔记系列-Efficient Neural Architecture Search via Parameter Sharing,这里不做过多介绍。
- Surrogate model-based optimization (SMBO)
SMBO简单理解就使用一个代理模型(比如Gaussian process)来预测生成的模型的性能,进而加快搜索效率。

- Random & Grid search
random search被好几个论文证明了它也是非常有效的,有的时候甚至超过了一些“花里胡哨”的方法。
(真.玄.学)
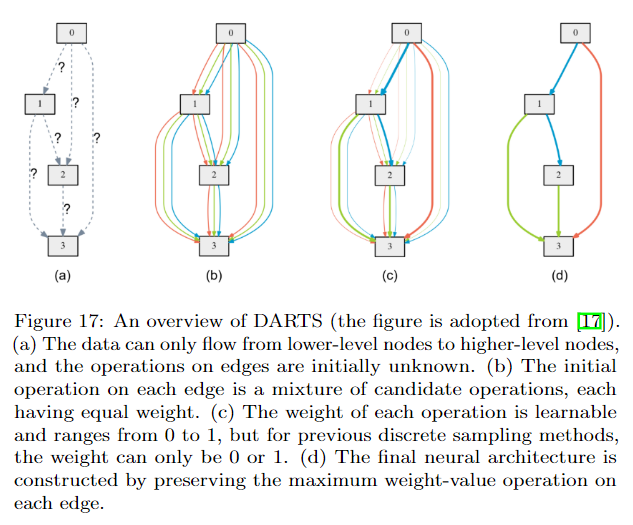
- Gradient descent-based method
DARTS应该是最早提出连续化搜索的方法之一,但是他有一个很大的问题就是内存消耗大,因为它构建了一个supernet,而且每次计算都需要更新这个supernet。因此后续有很多方法来改进。比如GDAS将Gumbel-softmax应用到DARTS上,每次只需要更新supernet的一个子网络即可,因此对内存消耗减少了很多。还有其他很多改进算法详见论文。
3.3 Model estimation
搜索到一个模型后,我们需要对一个模型做评估。最朴素的想法就是训练这个模型直到收敛,然后在验证集上看他的结果怎么样,但是这样既耗时又耗资源。所以需要一些提高效率的方法,下面只是做简单的总结,具体细节详见论文。
1) 低保真度评估
- 使用分辨率更小的图片(比如ImageNet原图一般是224*224,那我们可以用64*64的变体数据集)
- 使用训练集的子集来训练,减少训练时间
- 使用多个低保真的评估,然后将这些评估结果做一个ensemble
2)weight sharing
ENAS 和DARTS都采用了类似的方式,即所有可能的模型都是一个supernet的子模型。这些子模型互相共享权重,因此就不需要每次都重新对子模型进行训练了。
3)Surrogate
我不再去训练模型了,相反我可以使用代理模型来预测模型的性能。但是如何确保代理模型能准确预测是一个需要解决的问题。
4)资源感知
早期NAS工作更多关注在最终的accuracy,而忽略了生成的模型的大小。比如有的模型虽然表现不错,但是模型非常大,换言之这种模型的实用性是有局限的。所以很多论文开始探索如何找到参数不是太多而且表现还不错的模型。
4、NAS讨论
4.1 Performance Comparison
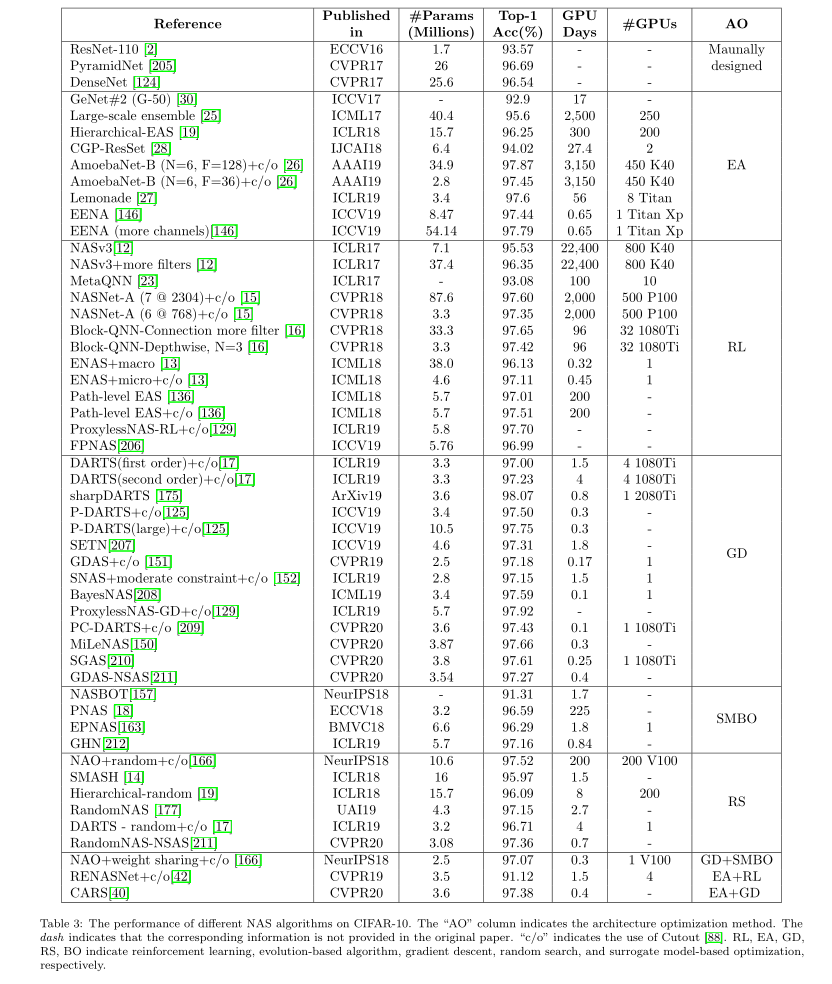
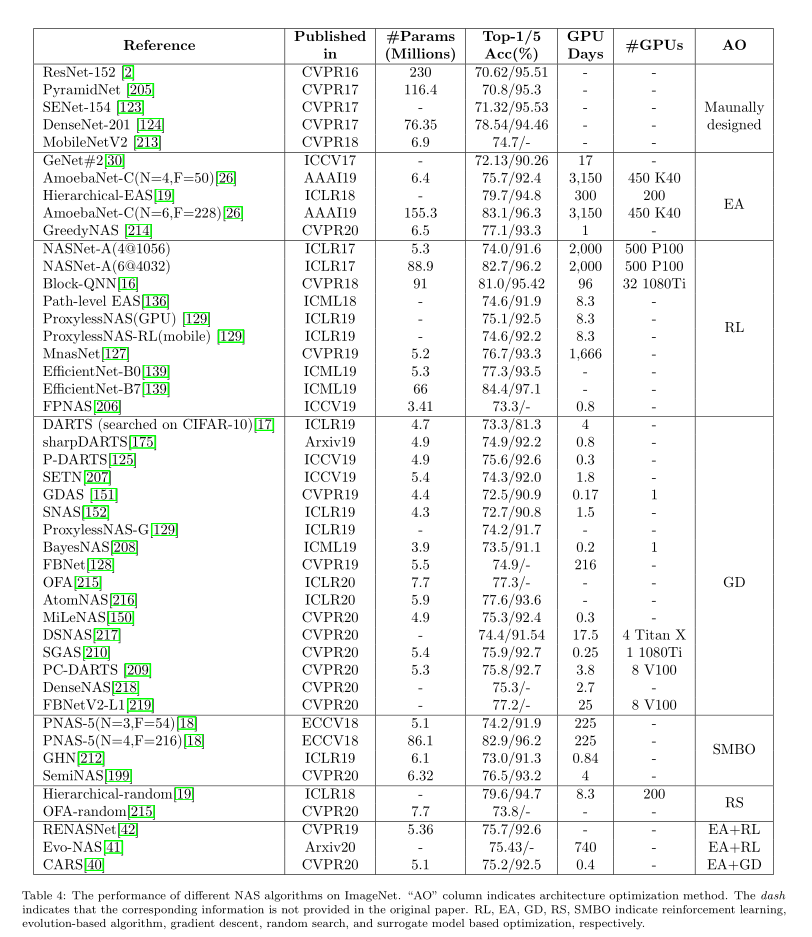
上面两个表格总结了NAS算法在CIFAR-10和ImageNet上的结果。虽然每个论文使用的硬件设备都不太一样,但是大致上我们还是能看到Gradient descent-based methods是非常高效的,不仅使用的资源少,而且效果还很不错,这也是为什么很多后续NAS工作都是沿着这个思路做的。
但是我们也可以看到随机搜索也是一个非常不错的方法,不仅简单,而且结果也可和其他方法相媲美。
1) Kendall Tau
但是上面的都是基于accuracy和搜索时间上做的对比。有不少方法开始寻找其他的NAS算法评价指标,。我们知道大多数NAS其实分成两个步骤,一是搜索最有潜力的模型(搜索阶段);二是验证该模型的表现(评估阶段)。但是很多时候搜索阶段表现最好的,在评估阶段并不是最好的,甚至可能表现很差。 因此一种用的比较多的就是Kendall Tau metric,它会评估两个阶段模型性能的相关性,相关性越高则表示算法越有效,它的计算公式如下:
其中\(N_C,N_D\)分别表示 concordant and discordant pairs。\(\tau\)的大小在-1到1之间:
- \(\tau=1\):算法能很好地找到表现好的模型,即搜索阶段表现最好的模型在评估阶段也是最好的。
- \(\tau=1\): 算法不能很好地找到表现好的模型,即搜索阶段表现最好的模型在评估阶段反而是最差的。
- \(\tau=0\):搜索阶段和评估阶段之间完全没有关系,基本上是随机搜索。
2) NAS-Bench
最近有好几个NAS相关的数据集,如NAS-Bench-101、NAS-Bench-201和NAS-Bench-NLP。简单理解就是这些数据集的每个样本的数据就是某种网络结构和模型大小等信息,对应的标签就是该网络结构的准确率。很多NAS算法都基于这些数据集来验证他们算法的有效性,而且使用这些数据集不需要我们在训练和评估搜索到的网络结构了,效率也更高了。
4.2 Two-stage vs. One-stage NAS
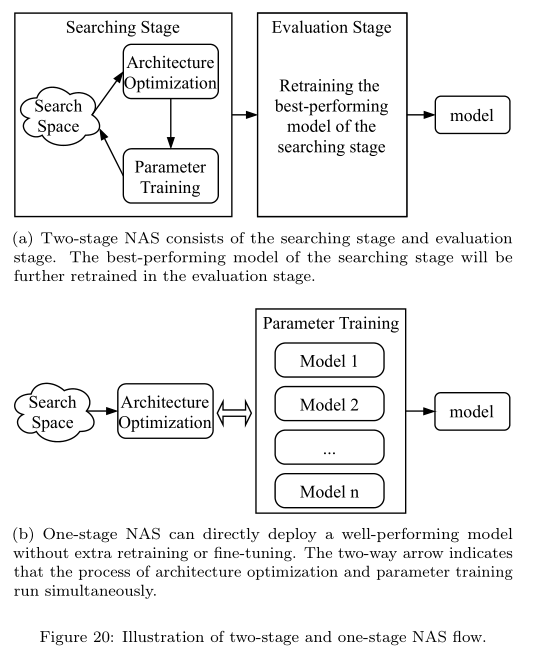
一般的NAS算法都是Two-stage的,即先找到一个比较有潜力的模型,之后在deploy之前基本上还得retrain或者finetune一遍。而one-stage NAS则不需要,即找到模型后即可直接用这个模型来做预测了,这方面的方法有Once-for-all NAS, AutoHAS, FBNetv3等。
4.3 One-shot NAS
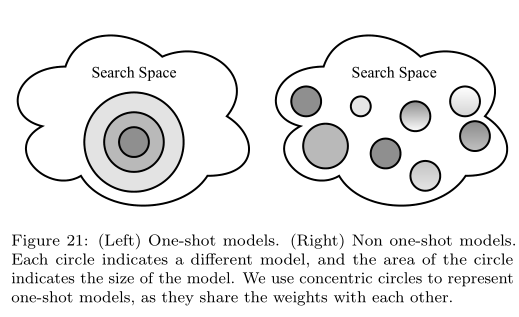
在介绍之前需要说明下:One-shot NAS和One-stage NAS是两回事,二者可能会有重叠的地方,但是分类的方法是不一样的。One-stage NAS强调的是一步到位,即搜索完之后模型可以直接使用,而不再需要retrain等操作;而One-shot NAS指的是那些将search space构造成一个supernet的方法,即对网络结构的搜索其实就是对supernet内部路径的搜索。
我们把 One-shot NAS又进一步划分成了两类:coupled optimization(耦合优化)和decoupled optimization(解耦优化)。
1)耦合优化
耦合优化的包含两个方面的耦合:
- 网络结构和权重的耦合。比如DARTS采用的是bilevel的方式来优化架构和对应权重
- 子网络之间权重耦合。由于子网络之间互相共享权重,更新某一个子网络的权重必然会影响其他子网络的性能
像DARTS、ENAS就是属于耦合优化。
2)解耦优化
解耦优化,就是把架构优化和权重优化分开成两个步骤,即先只训练supernet,之后从supernet中按照设计的优化算法选择和评估。
Understanding and Simplifying One-Shot Architecture Search和Single Path One-Shot Neural Architecture Search with Uniform Sampling这两篇论文是比较经典的解耦优化算法。
4.4 Joint Hyperparameter and Architecture Optimization
文章最前面提到我们将hyperparameter和architecture做了区分,但是究其本质,其实二者是一样的,而且使用的优化算法也很多是通用的,比如随机搜索,SMBO,基于梯度的优化算法等都可以用来优化hyperparameters和architecture。因此为什么不同时优化二者呢?像AutoHAS这些方法在这一方向上做了探索,也取得了不错的效果(详见原论文)。
5、Open problems and Future work
- Flexible search space
目前大多数NAS的search space基本上都是基于人类经验设计的,比如使用卷积操作、假如skip-connection等,虽然效果不错,但是或多或少都引入了人类偏见,或者说仍旧没有跳脱出人类的设计范畴。所以如何设计出不受人类偏见影响的search space是一个值得探索的方向。Auto-Zero在这方向上做出了探索,它只使用一些非常基础的数学计算式子,例如加、减sin,cos,高斯分布等从0开始成功地找到了2层的神经网络结构。
- 可解释性
- 可复现性
- 鲁棒性
目前NAS更多实应用在科研性质的数据集上,而我们都知道现实世界中的数据是有很多噪声的,比如标签错误或者信息不完整等,甚至有的数据加入了人为制造的噪声(如Adversarial data),这些都会影响模型的性能。虽然已经有不少方法可以提高模型的对抗噪声鲁棒性,但是他们都是算是一个后处理的方法,一个理想的方法是在搜索过程我就能搜索到鲁棒性很强的模型,这样就不用再做一些后处理操作了。目前将NAS和鲁棒性结合的论文还不是很多(好像只有三四篇论文),因此还是一个初步探索阶段。
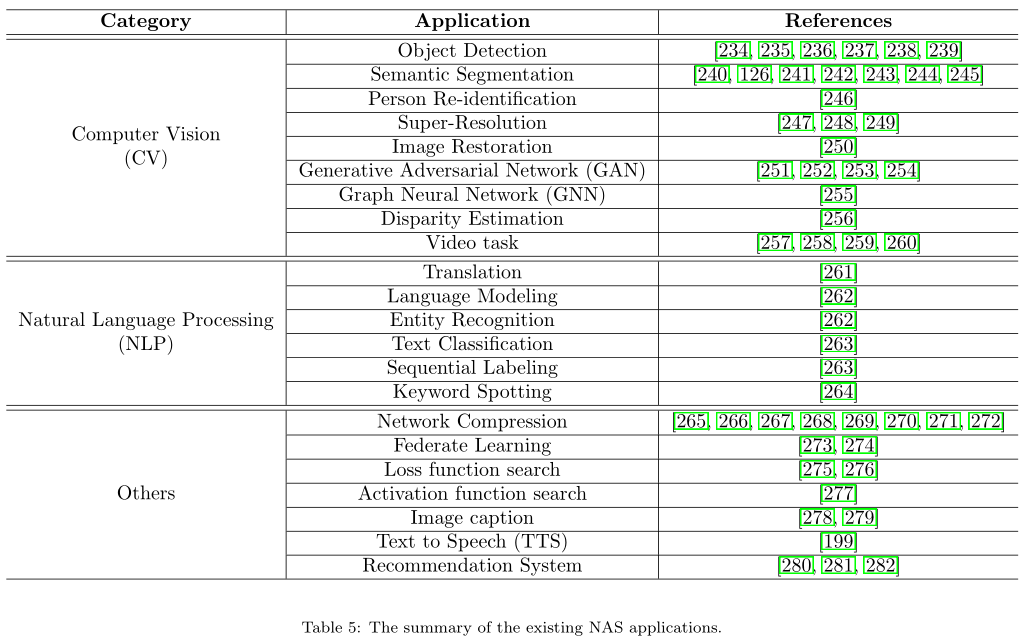
- 将NAS应用到更多领域
下表统计了除了图像分类外,目前NAS所应用的领域
- 完整的AutoML pipeline系统
目前有不少AutoML的开源库了,但是大都只实现了pipeline的一部分。
比如TPOT,Auto-Weka,Auto-Sklearn都是基于传统机器学习模型设计的。Auto-keras则主要侧重NAS。不过微软的NNI和华为最近开源的Vega都提供了非常强大的功能,例如NAS、模型压缩、超参数搜索。NNI最近更新了对Sklearn的支持,Vega还提供了自动化data augmentation功能,很是强大了,因此完全傻瓜式的多模块AutoML系统指日可待了。
- lifelong learning
一个优秀的AutoML系统还应该能够lifelong learning,因为在现实场景中会源源不断的产生新数据,所以换句话说就是能不断学习新数据,同时还能记住旧知识。
对于学习新数据,有两个问题:一是新数据的数量可能会很少,这就涉及到meta-learning技术。最近有不少论文将NAS和meta-learning做了结合,也都取得了不错的效果;二是新数据的标签不完整,这就涉及非监督学习,何凯明团队最新研究成果UnNAS发现非监督NAS也能取得不错甚至比监督NAS更好的结果。
记住旧知识比较经典的算法是learning without forgetting (LwF) 和 iCaRL。
