理解Pytorch中LSTM的输入输出参数含义
本文不会介绍LSTM的原理,具体可看如下两篇文章
1、举个栗子
在介绍LSTM各种参数含义之前我们还是需要先用一个例子(参考LSTM神经网络输入输出究竟是怎样的?Scofield的回答)来理解LSTM。
Recurrent NNs,一般看的最多的图是这个:
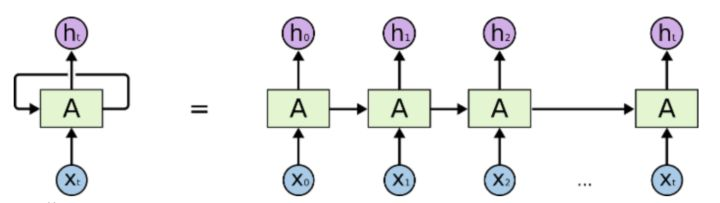
rnn但是这个图对初学者相当不太友好。个人认为,目前所有的关于描述RecurrentNNs的图都画得不好,不够明确,里面的细节丢失了。(事实上里面一个"A"仅仅表示了一层的变换,具体如下图所示。)
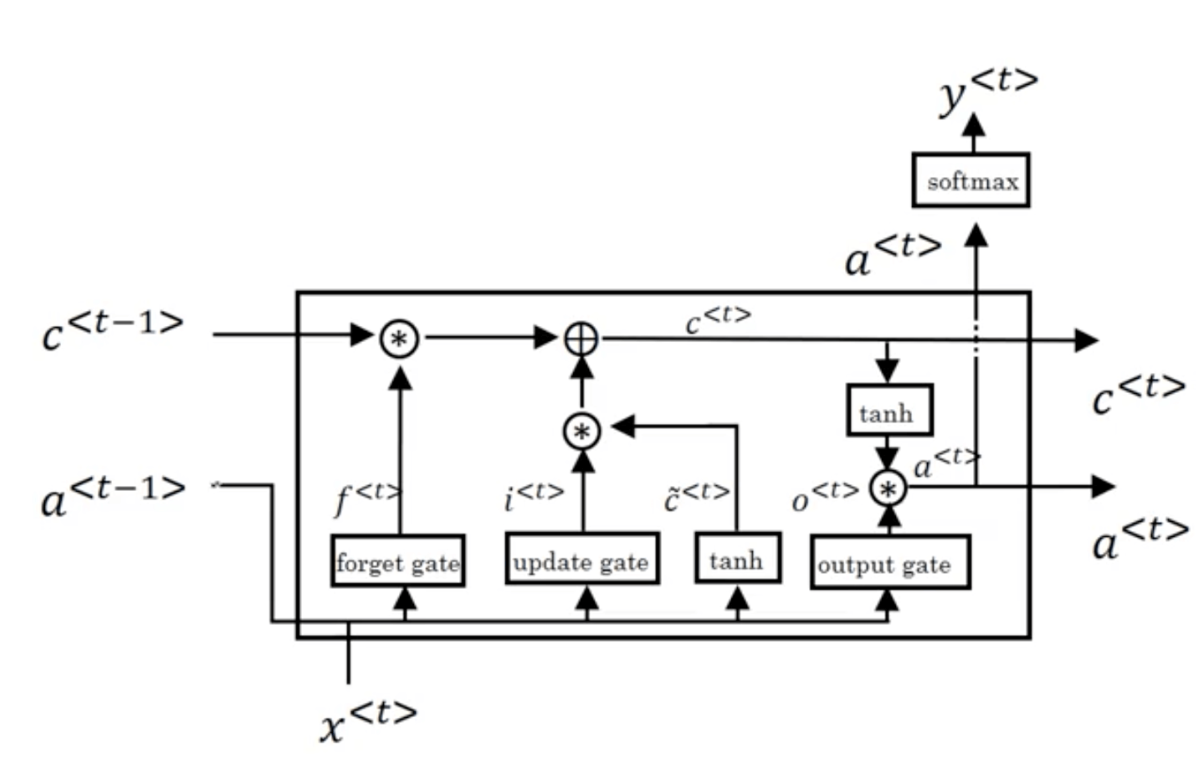
非常清楚,这是很多初学者不能理解RecurrentNNs的根本原因,即在于Recurrent NNs是在time_step上的拓展的这一特性。MLP好理解,CNN也好理解,但Recurrent NNs,就是无法搞清楚里面的拓扑结构,跟MLP联系不上。
先看看MLP,很好理解,就是一张网络清楚地显示了张量流向。
general MLP是这样的拓扑:
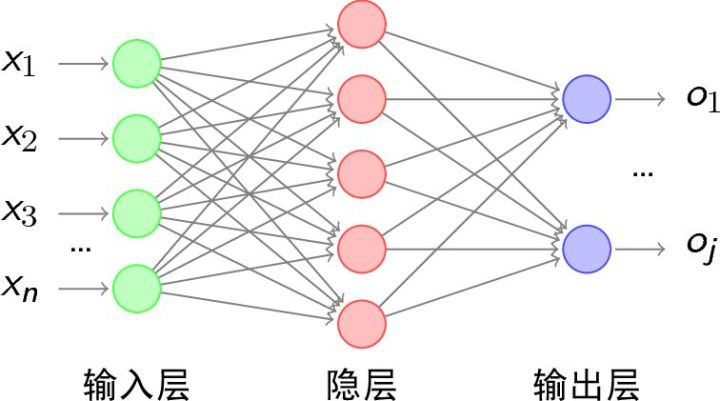
mlp然后CNN也好理解,跟MLP无差若干,只是权重运算由\(*\)变为\(\otimes\)。CNN是这样的拓扑:

但RecurrentNNs的拓扑发生了一个很大的改动,即一个MLP会在time_step这个维度上进行延伸,每个时序都会有input。
所以RecurrentNNs的结构图应该这样画,在理解上才会更清晰些,对比MLP,也一目了然。(为了简约,只画了4个time-steps )……
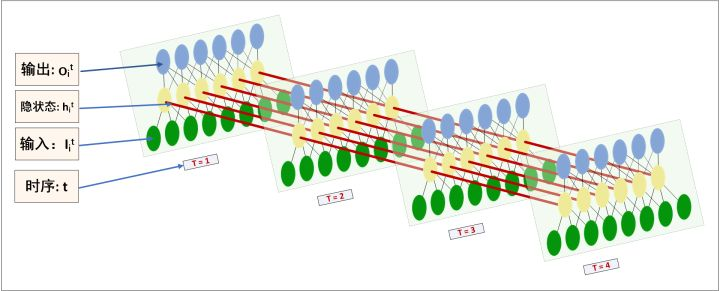
如上图所示,
- 每个时序\(t\) 的输入\(T_i^t\),也就是说一次time_step输入一个input tensor。
- 隐状态\(h_i^t\)也就代表了一张MLP的hidden layer的一个cell,可以看到中间黄色圈圈就表示隐藏层.
- 输出\(O_i^t\)理解无异,可以看到每个时序的输出节点数是等于隐藏节点数的。注意,红色的箭头指向仅仅表示数据流动方向,并不是表示隐藏层之间相连。
再结合一个操作实例说明。如果我们有一条长文本,我们给句子事先分割好句子,并且进行tokenize, dictionarize,接着再由look up table 查找到embedding,将token由embedding表示,再对应到上图的输入。流程如下:
- step1, raw text (语料库如下):
接触LSTM模型不久,简单看了一些相关的论文,还没有动手实现过。然而至今仍然想不通LSTM神经网络究竟是怎么工作的。…… - step2, tokenize (中文得分词):
- sentence1: 接触 LSTM 模型 不久 ,简单 看了 一些 相关的 论文 , 还 没有 动手 实现过 。
- sentence2: 然而 至今 仍然 想不通 LSTM 神经网络 究竟是 怎么 工作的。
- ……
- step3, dictionarize:
- sentence1: 1 34 21 98 10 23 9 23
- sentence2: 17 12 21 12 8 10 13 79 31 44 9 23
- ……
- step4, padding every sentence to fixed length:
- sentence1: 1 34 21 98 10 23 9 23 0 0 0 0 0
- sentence2: 17 12 21 12 8 10 13 79 31 44 9 23 0
- ……
- step5, mapping token to an embeddings:
- sentence1:\(\left[\begin{array}{cccc}{0.341} & {0.133} & {0.011} & {\cdots} \\ {0.435} & {0.081} & {0.501} & {\cdots} \\ {0.013} & {0.958} & {0.121} & {\ldots} \\ {\cdots} & {\cdots} & {\cdots} & {\cdots}\end{array}\right]\),每一列代表一个词向量,词向量维度自行确定(假设一个单词由长度为100的向量表示);矩阵列数固定为time_step length。
- sentence2: ...
- ……
- step6, feed into RNNs as input:
假设 一个RNN的time_step 确定为\(l\),则padded sentence length(step5中矩阵列数)固定为 \(l\)。一次RNNs的run只处理一条sentence。每个sentence的每个token的embedding对应了每个时序 的输入 。一次RNNs的run,连续地将整个sentence处理完。简单理解就是每次传入RNN的句子长度为\(l\),换句话就是RNN横向长度为\(l\) - step7, get output:
看图,每个time_step都是可以输出当前时序\(t\)的隐状态\(h_i^t\);但整体RNN的输出\(O_i^t\)是在最后一个time_step\(t=l\)时获取,才是完整的最终结果。 - step8, further processing with the output:
我们可以将output根据分类任务或回归拟合任务的不同,分别进一步处理。比如,传给cross_entropy&softmax进行分类……或者获取每个time_step对应的隐状态\(h_i^t\),做seq2seq 网络……或者搞创新……
2、Pytorch源代码参数理解
2.1 LSTM模型参数含义
通过源代码中可以看到nn.LSTM继承自nn.RNNBase,其初始化函数定义如下
class RNNBase(Module):
...
def __init__(self, mode, input_size, hidden_size,
num_layers=1, bias=True, batch_first=False,
dropout=0., bidirectional=False):
我们需要关注的参数以及其含义解释如下:
- input_size – 输入数据的大小,也就是前面例子中每个单词向量的长度
- hidden_size – 隐藏层的大小(即隐藏层节点数量),输出向量的维度等于隐藏节点数
- num_layers – recurrent layer的数量,默认等于1。
- bias – If False, then the layer does not use bias weights b_ih and b_hh. Default: True
- batch_first – 默认为False,也就是说官方不推荐我们把batch放在第一维,这个CNN有点不同,此时输入输出的各个维度含义为 (seq_length,batch,feature)。当然如果你想和CNN一样把batch放在第一维,可将该参数设置为True。
- dropout – 如果非0,就在除了最后一层的其它层都插入Dropout层,默认为0。
- bidirectional – If True, becomes a bidirectional LSTM. Default: False
2.2 输入数据
下面介绍一下输入数据的维度要求(batch_first=False):
输入数据需要按如下形式传入 input, (h_0,c_0)
- input: 输入数据,即上面例子中的一个句子(或者一个batch的句子),其维度形状为 (seq_len, batch, input_size)
- seq_len: 句子长度,即单词数量,这个是需要固定的。当然假如你的一个句子中只有2个单词,但是要求输入10个单词,这个时候可以用
torch.nn.utils.rnn.pack_padded_sequence()或者torch.nn.utils.rnn.pack_sequence()来对句子进行填充或者截断。 - batch:就是你一次传入的句子的数量
- input_size: 每个单词向量的长度,这个必须和你前面定义的网络结构保持一致
- seq_len: 句子长度,即单词数量,这个是需要固定的。当然假如你的一个句子中只有2个单词,但是要求输入10个单词,这个时候可以用
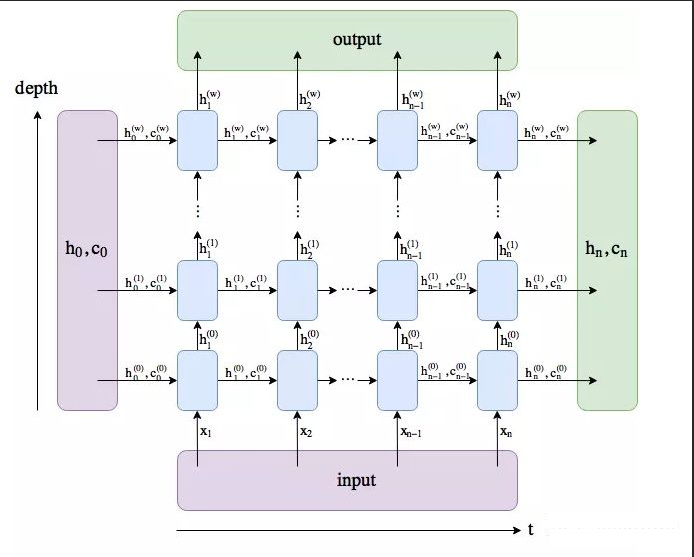
- h_0:维度形状为 (num_layers * num_directions, batch, hidden_size):
- 结合下图应该比较好理解第一个参数的含义num_layers * num_directions, 即LSTM的层数乘以方向数量。这个方向数量是由前面介绍的
bidirectional决定,如果为False,则等于1;反之等于2。 - batch:同上
- hidden_size: 隐藏层节点数
- 结合下图应该比较好理解第一个参数的含义num_layers * num_directions, 即LSTM的层数乘以方向数量。这个方向数量是由前面介绍的
- c_0: 维度形状为 (num_layers * num_directions, batch, hidden_size),各参数含义和h_0类似。
当然,如果你没有传入(h_0, c_0),那么这两个参数会默认设置为0。
2.3 输出数据
- output: 维度和输入数据类似,只不过最后的feature部分会有点不同,即 (seq_len, batch, num_directions * hidden_size)
- 这个输出tensor包含了LSTM模型最后一层每个time step的输出特征,比如说LSTM有两层,那么最后输出的是\([h^1_0,h^1_1,...,h^1_l]\),表示第二层LSTM每个time step对应的输出。
- 另外如果前面你对输入数据使用了
torch.nn.utils.rnn.PackedSequence,那么输出也会做同样的操作编程packed sequence。 - 对于unpacked情况,我们可以对输出做如下处理来对方向作分离
output.view(seq_len, batch, num_directions, hidden_size), 其中前向和后向分别用0和1表示Similarly, the directions can be separated in the packed case.
- h_n:(num_layers * num_directions, batch, hidden_size),
- 只会输出最后个time step的隐状态结果(如下图所示)。
- Like output, the layers can be separated using h_n.view(num_layers, num_directions, batch, hidden_size) and similarly for c_n.
- c_n :(num_layers * num_directions, batch, hidden_size),只会输出最后个time step的cell状态结果(如下图所示)。
3、 代码示例
rnn = nn.LSTM(10, 20, 2) # 一个单词向量长度为10,隐藏层节点数为20,LSTM有2层
input = torch.randn(5, 3, 10) # 输入数据由3个句子组成,每个句子由5个单词组成,单词向量长度为10
h0 = torch.randn(2, 3, 20) # 2:LSTM层数*方向 3:batch 20: 隐藏层节点数
c0 = torch.randn(2, 3, 20) # 同上
output, (hn, cn) = rnn(input, (h0, c0))
print(output.shape, hn.shape, cn.shape)
>>> torch.Size([5, 3, 20]) torch.Size([2, 3, 20]) torch.Size([2, 3, 20])
参考:

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步