

python之路-网络编程
一. 楔子
两个程序之间想要传递一个数据,需要用到网络通信.
二. 软件开发的架构:
第一种: 应用类: qq,微信,网盘,优酷 这一类是属于需要安装的桌面应用.
第二种: web类: 百度,知乎,博客园,等使用浏览器访问就可以直接使用的应用.
这些应用的本质其实就是两个程序之间的通讯,而这两个分类又对应了两个软件开发的架构.
1.C/S 架构
C/S即: client与server,中文意思: 客户端与服务器端架构,这种架构也是从用户层面,(也是物理层面划分的).
2.B/S 架构
B/S即:browser和server,中文意思:浏览器端与服务器端架构,这种架构是从用户层面来划分.
browser浏览器,其实也是一种client客户端,只是这个客户端不需要大家去安装什么应用程序,只是需要通过http请求服务器端相关的资源(网页资源),客户端browser浏览器就能进行增删改查.
三. 网络基础.
1. osi七层模型.
2.socket概念
socket是应用层与TCP/IP协议族通信的中间软件抽象层,他是一组接口.在设计模式中,socket其实就是一个门面模式,它把复杂的TCP/IP协议族隐藏在socket接口后面,对用户来说,一组简单的接口就是全部,让socket去组织数据,以符合指定的协议.
其实站在你的角度上看,socket就是一个模块.我们通过调用模块中实现的方法
建立两个进程之间的连接和通信. 也有人将socket说成ip+port,因为ip是用来标识互联网中的一台主机的位置,
而port是用来标识这台机器上的一个应用程序,
所以我们只要确立了ip和port就能找到一个应用程序,并且使用socket模块来与之通信.
3. tcp协议和udp协议
TCP 可靠的.面向连接的协议,传输效率低全双工通信(发送缓存,接收缓存),面向字节流.
使用TCP的应用: web浏览器;电子邮件;文件传输程序.
UDP 不可靠的,无连接的服务,传输效率高(发送钱延迟小),一对一,一对多,多对多,面向报文,尽最大努力服务,无拥塞控制,使用UDP的应用: 域名系统(DNS); 视频流,IP语音.

四.套接字(socket)初使用.
1. 基于TCP协议的socket
tcp是基于连接的,必须先启动服务器,然后再启动客户端去连接服务器.
server端


import socket sk = socket.socket() sk.bind(('127.0.0.1',8898)) #把地址绑定到套接字 sk.listen() #监听链接 conn,addr = sk.accept() #接受客户端链接 ret = conn.recv(1024) #接收客户端信息 print(ret) #打印客户端信息 conn.send(b'hi') #向客户端发送信息 conn.close() #关闭客户端套接字 sk.close() #关闭服务器套接字(可选)
client端
import socket sk = socket.socket() # 创建客户套接字 sk.connect(('127.0.0.1',8000)) # 尝试连接服务器 sk.send(b'hello') ret = sk.recv(1024) # 对话(发送/接收) print(ret) sk.close() # 关闭客户套接字
问题: 重启服务端时可能会遇到,

解决方法:
# 加入一条socket配置,重用ip和端口. import socket from socket import SOL_SOCKET,SO_REUSEADDR sk = socket.socket() sk.setsockopt(SQL_SOCKET,SO_REUSEADDR,1) # 就是它,在bind前加. sk.bind('127.0.0.1',8000) #把地址绑定到套接字 sk.listen() #监听链接 conn,addr = sk.accept() #接收客户端链接 ret = conn.recv(1024) #接收客户端信息 print(ret) # 打印客户端信息 conn.send(b'hi') # 向客户端发送信息 conn.close() # 关闭客户端套接字 sk.close() # 关闭服务器套接字(可选)
2.基于UDP协议的socket
udp是无链接的,启动服务之后可以直接接收消息,不需要提前建立链接.
简单使用
server端
import socket udp_sk = socket.socket(type=socket.SOCK_DGRAM) # 创建一个服务器的套接字 udp_sk.bind(('127.0.0.1',9000)) # 绑定服务器套接字 msg,addr = udp_sk.recvfrom(1024) print(msg) udp_sk.sendto(b'hi',addr) #对话(接收与发送) udp_sk.close() #关闭服务器套接字
client端
import socket ip_port = ('127.0.0.1',9000) udp_sk = socket.socket(type=socket.SOCK_DGRAM) udp_sk.sendto(b'hello',ip_port) back_msg,addr = udp_sk.recvfrom(1024) print(back_msg.decode('utf-8'),addr)
3. socket参数的详解
socket.socket(family=AF_INET,type=SOCK_STEAM,proto=0,fileno=None)
创建socket对象的参数说明:
| family | 地址系列应为AF_INET(默认值),AF_INET6,AF_UNIX,AF_CAN或AF_RDS。 (AF_UNIX 域实际上是使用本地 socket 文件来通信) |
| type | 套接字类型应为SOCK_STREAM(默认值),SOCK_DGRAM,SOCK_RAW或其他SOCK_常量之一。 SOCK_STREAM 是基于TCP的,有保障的(即能保证数据正确传送到对方)面向连接的SOCKET,多用于资料传送。 SOCK_DGRAM 是基于UDP的,无保障的面向消息的socket,多用于在网络上发广播信息 |
| proto | 协议号通常为0,可以省略,或者在地址族为AF_CAN的情况下,协议应为CAN_RAW或CAN_BCM之一. |
| fileno | 如果指定了fileno,则其他参数将被忽略,导致带有指定文件描述符的套接字返回。 与socket.fromfd()不同,fileno将返回相同的套接字,而不是重复的。 这可能有助于使用socket.close()关闭一个独立的插座 |
五.黏包
1.黏包现象
让我们基于tcp先制作一个远程执行命名的程序(命令ls -l; llllll,pwd)
res = subprocess.Popen(cmd.decode('utf-8'), shell=True, stderr=subprocess.PIPE, stdout=subprocess.PIPE) 结果的编码是以当前所在的系统为准的,如果是windows,那么res.stdout.read()读出来的就是gbk编码的,在接收端需要gbk解码 且只能从管道里读一次结果
同时执行多条命令之后,得到的结果很可能这样一部分,在执行其他命令的时候又接收之前执行的另一部分结果,这种显现就是黏包.
2. 基于tcp协议实现的黏包
tcp-server
tcp - server from socket import * import subprocess ip_port = ('127.0.0.1',8888) BUFSIZE = 1024 tcp_socket_server = socket(AF_INET,SOCK_STREAM) tcp_socket_server.setsockopt(SOL_SOCKET,SO_REUSEADDR,1) tcp_socket_server.bind(ip_port) tcp_socket_server.listen(5) while True: cmd = conn.recv(BUFSIZE) if len(cmd) == 0:break res = subprocess.Poen(cmd.decode('utf-8'), shell=True, stdout=subprocess.PIPE, stdin=subprocess.PIPE, stderr=subprocess.PIPE ) stderr = res.stderr.read() stdout = res.stdout.read() conn.send(stderr) conn.send(stdout)
tcp-client
# tcp-client import socket BUFSIZE = 1024 ip_port = ('127.0.0.1',8888) s = socket.socket(socket.AF_INET,socket.SOCK_STREAM) res = s.connect_ex(ip_port) while True: msg = input('>>:').strip() if len(msg) == 0:continue if msg == 'quit':break s.send(msg.encode('utf-8')) act_res = s.recv(BUFSIZE) print(act_res.decode('utf-8'),end='')
注意: 只要TCP有黏包现象.UDP永远不会黏包.
3.黏包成因
1.TCP协议中的数据传递,
tcp协议的拆包机制.
当发送端缓冲区的长度大于网卡的MTU时,tcp会将这次发送的数据拆成几个数据包发送出去.
MTU是Maximum Transmission Unit的缩写. 意思是网络上传送的最大数据包. MTU的单位是字节,大部分网络设备的MTU都是1500.如果本机的MTU比网关的MTU大,
大的数据包就会被拆开传送,这样会产生数据包碎片,增加丢包率,降低网络速度.
面向流的通信特点和Nagle算法
TCP(transport control protocol,传输控制协议)是面向连接的,面向流的,提供高可靠性服务。
收发两端(客户端和服务器端)都要有一一成对的socket,因此,发送端为了将多个发往接收端的包,更有效的发到对方,使用了优化方法(Nagle算法),将多次间隔较小且数据量小的数据,合并成一个大的数据块,然后进行封包。
这样,接收端,就难于分辨出来了,必须提供科学的拆包机制。 即面向流的通信是无消息保护边界的。
对于空消息:tcp是基于数据流的,于是收发的消息不能为空,这就需要在客户端和服务端都添加空消息的处理机制,防止程序卡住,而udp是基于数据报的,即便是你输入的是空内容(直接回车),也可以被发送,udp协议会帮你封装上消息头发送过去。
可靠黏包的tcp协议:tcp的协议数据不会丢,没有收完包,下次接收,会继续上次继续接收,己端总是在收到ack时才会清除缓冲区内容。数据是可靠的,但是会粘包。
会发生黏包的两种情况
情况一 , 发送方的缓存机制.
发送端需要等缓冲区满才发送出去,造成黏包(发送数据时间间隔很短,数据了很小,会合到一起,产生黏包)
服务端
from socket import * ip_port = ('127.0.0.1',8080) tcp_socket_server = socket(AF_INET,SOCK_STEARM) tcp_socket_server.bind(ip_port) tcp_socket_server.listen(5) conn,addr = tcp_socket_server.accept() data1 = conn.recv(10) data2 = conn.recv(10) print('----->',data1.decode('utf-8')) print('----->',data2.decode('utf-8')) conn.close()
客户端
import socket BUFSIZE = 1024 ip_port = ('127.0.0.1',8080) s = socket.socket(socket.AF_INET,socket.SOCK_STREAM) res = s.connect_ex(ip_port) s.send('hello'.encode('utf-8')) s.send('egg'.encode('utf-8'))
情况二,接收方的缓存机制
接收方不及时接收缓存区的包,造成多个包接收(客户端发送了一段数据,服务端只收了一小部分,服务端下次再收的时候还是从缓存区拿上次遗留的数据,产生黏包)
服务端
from socket import * ip_port = ('127.0.0.1',8080) tcp_socket_server = socket(AF_INET,SOCK_STREAM) tcp_socket_server.bind(ip_port) tcp_socket_server.listen(5) conn,addr = tcp_socket_server.accept() data1 = conn.recv(2) # 一次没有收完整 data2 = conn,recv(10) # 下次收的时候,会先取旧的数据,然后取新的. print('----->',data1.decode('utf-8')) print('----->',data2.decode('utf-8')) conn.close()
客户端
import socket BUFSIZE = 1024 ip_port = ('127.0.0.1',8080) s = socket.socket(socket.AF_INET,socket.SOCK_STREAM) res = s.connect_ex(ip_port) s.send('hello egg'.encode('utf-8'))
总结:
黏包现象只发生在tcp协议中:
1.从表面上看,黏包问题主要是因为发送方和接收方的缓存机制,tcp协议面向流通信的特点.
2. 实际上,主要还是因为接收方不知道消息之间的界限,不知道一次性提取多少字节的数据造成的.
4.黏包的解决方案
解决方案一
问题的根源在于,接收端不知道发送端将要传送的字节流的长度,所以解决黏包的方法就是围绕,如何让发送端在发送数据前,把自己将要发送的字节流总大小让接收端知晓,然后接收端来一个死循环接收完所有数据.
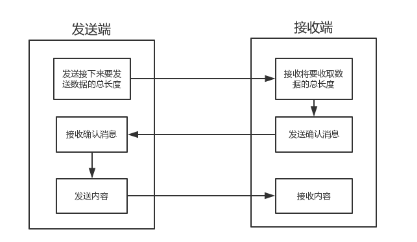
服务端
import socket,subprocess ip_port = ('127.0.0.1',8080) s = socket.socket(socket.AF_INET,socket.SOCK_STRMAM) s.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1) s.bind(ip_port) s.listen(5) while True: conn,addr = s.accept() print('客户端',addr) while True: msg = conn.recv(1024) if not msg:break res = subprocess.Popen(msg.decode('utf-8'), shell=True, stdin=subprocess, stderr=subprocess.PIPE, stdout=subprocess.PIPE) err = res.stderr.read() if err: ret = err else: ret = res.stdout.read() data_length = len(ret) conn.send(str(data_length).encode('utf-8')) data = conn.recv(1024).decode('utf-8') if data == 'recv_ready': conn.sendall(ret) conn.close()
客户端
import socket,time s = socket.socket(socket.AF_INET,socket.SOCK_STREAM) res = s.connect_ex(('127.0.0.1',8080)) while True: msg = input('>>:').strip() if len(msg) == 0:continue if msg == 'quit':break s.send(msg.encode('utf-8')) length = int(s.recv(1024).decode('utf-8')) s.send('recv_ready'.encode('utf-8')) send_size = 0 recv_size = 0 data = b'' while recv_size < length: data += s.recv(1024) recv_size += len(data) print(data.decode('utf-8'))
存在的问题:
程序的运行速度远快于网络传输速度,所以在发送一段字节前,先用send去发送该字节流长度,这种方式会放大网络延迟带来的性能损耗.
5. 解决方案进阶.
刚刚的方法,问题在于我们在发送. 我们可以借助一个模块,这个模块可以要发送的数据长度转换成固定长度的字节,这样客户端每次接收消息之前只要先接收这个固定长度字节的内容看一看接下来要接收的信息大小,那么最终接收的数据只要达到这个值就停止,就能刚好不多不少的接收完整的数据了.
struct模块
该模块可以把一个类型,如数字,转成固定长度的bytes
>>> struct.pack('i',11111111) struct.error: 'i' format requires -214748348 <= number <= 2147483647 # 这个是范围
# struct模块 import json,struct # 假设通过客户端上传1T:10737418000的文件a.txt 为避免黏包,必须自定制报头 header = {'file_size':1073741824000,'file_name':'/a/b/c/d/e/a.txt','md5':'8f6fbf8347faa4924a76856701edb0f3'} # 1T数据,文件路径和md5值. #为了该报头能传送,需要序列化并且转为bytes head_bytes = bytes(json.dumps(header),encoding='utf-8') # 序列化并转成bytes,用于传输 # 为了让客户端知道报头的长度,用struck将报头长度这个数字转成固定长度:4个字节 head_len_bytes = struct.pack('i',len(head_bytes)) # 这4个字节里只包含了一个数字,该数字是报头的长度 #客户端开始发送 conn.send(head_len_bytes) #先发报头的长度,4个bytes conn.send(head_bytes) # 先发报头的字节格式 conn.sendall(文件内容) # 然后发真实内容的字节格式 #服务端开始接收 head_len_bytes = s.recv(4) #先收报头4个bytes,得到报头长度的字节格式 x = struct.unpack('i',head_len_bytes)[0] #提取报头的长度 head_bytes = s.recv(x) #按照报头长度x,收取报头的bytes格式 header = json.loads(json.dumps(header)) #提取报头 #最后根据报头的内容提取真实的数据,比如: real_data_len = s.recv(header['file_size']) s.recv(real_data_len)
关于struct的详细用法
# 关于struct的详细用法 #http://www.cnblogs.com/coser/archive/2011/12/17/2291160.html __author__ = 'Linhaifeng' import struct import binascii import ctypes values1 = (1,'abc'.encode('utf-8',2.7)) values2 = ('defg'.encode('utf-8'),101) s1 = struct.Struct('I3sf') s2 = struct.Struct('4sI') print(s1.size,s2.size) prebuffer = ctypes.create_string_buffer(s1.size+s2.size) print('Before : ',binascii.hexlify(prebuffer)) # t = binascii.hexlify('asdfaf'.encode('utf-8')) # print(t) s1.pack_into(prebuffer,0,*values1) s2.pack_into(prebuffer,s1.size,*values2) print('After pack',binascii.hexlify(prebuffer)) print(s1.unpack_from(prebuffer,0)) print(s2.unpack_from(prebuffer,s1.size)) s3 = struct.Struct('ii') s3.pack_into(prebuffer,0,123,123) print('After pack',binascii.hexlify(prebuffer)) print(s3.unpack_from(prebuffer,0))
使用struct解决黏包
借助struct模块,我们知道长度数字可以被转换成一个标准大小的4字节数字,因此可以利用这个特点来预先发送数据长度.
| 发送时 | 接收时 |
| 先发送struct转换好的数据长度4字节 | 先接收4个字节使用struct转换成数字来获取要接收的数据长度 |
| 再发送数据 | 再按照长度接收数据 |
服务端(自定制报头)
import socket,struct,json import subprocess phone = socket.socket(socket.AF_INET,socket.SOCK_STREAM) phone.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1) #就是它,在bind前加. phone.bind(('127.0.0.1',8080)) phone.listen(5) while True: conn,addr = phone.accept() while True: cmd = conn,recv(1024) if not cmd:break print('cmd: %s ' % cmd) res = subprocess.Popen(cmd.decode('utf-8'), shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE) err = res.stderr.read() print(err) if err: back_msg = err else: back_msg = res.stdout.read() conn.send(struct.pack('i',len(back_msg))) # 先发back_msg的长度 conn.sendall(back_msg) # 在发真实的内容 conn.close()
客户端(自定制报头)
import socket,time,struct s = socket.socket(socket.AF_INET,socket.SOCK_STREAM) res = s.connect_ex(('127.0.0.1',8080)) while True: msg = input('>>:').strip() if len(msg) == 0:continue if msg == 'quit':break s.send(msg.encode('utf-8')) l = s.recv(4) x = struct.unpack('i',1)[0] print(type(x),x) # print(struct.unpack('I',1)) r_s = 0 data = b'' while r_s < x: r_d = s.recv(1024) data += r_d r_s += len(r_d) #print(data.decode('utf-8')) print(data.decode('gbk')) #windows默认gbk编码
我们还可以把报头做成字典,字典里包含将要发送的真实数据的详细信息,然后json序列化,然后用struck将序列化后的数据长度打包成4个字节.
| 发送时 | 接收时 |
| 先发报头长度 | 先收报头长度,用struct取出来 |
| 再编码报头内容然后发送 | 根据取出的长度收取报头内容,然后解码,反序列化 |
| 最后发真实内容 | 从反序列化的结果中取出待数据的详细信息,然后去取真实的数据内容 |
服务端: 定制稍微复杂一点的报头.
import socket,struct,json import subprocess phone = socket.socket(sock,AF_INET,socket.SOCK_STREAM) phone.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1) #就是它,在bind前加. phone.bind(('127.0.0.1',8080)) phone.listen(5) while True: conn,addr = phone.accept() while True: cmd = conn.recv(1024) if not cmd:break print('cmd: %s '% cmd) res = subprocess.Popen(cmd.decode('utf-8'), shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE) err = res.stderr.read() print(err) if err: back_msg = err else: back_msg = res.stdout.read() headers = {'data_size':len(back_msg)} head_json = json.dumps(headers) head_json_bytes = bytes(head_json,encoding='utf-8') conn.send(struct.pack('i',len(head_json_bytes))) # 先发报头的长度 conn.send(head_json_bytes) # 再发报头 conn.sendall(back_msg) # 再发真实的内容 conn.close()
客户端
from socket import * import struct,json ip_port = ('127.0.0.1',8080) client = socket(AF_INET,SOCK_STREAM) client.connect(ip_port) while True: cmd = input('>>:') if not cmd:continue client.send(bytes(cmd,encoding='utf-8')) head = client.recv(4) head_json_len = struct.unpack('i',head)[0] head_json = json.loads(client.recv(head_json_len).decode('utf-8')) data_len = head_json['data_size'] recv_size = 0 recv_data = b'' while recv_size < data_len: recv_data += client.recv(1024) recv_size += len(recv_data) print(recv_data.decode('utf-8')) #print(recv_data.decode('gbk')) # windows默认gbk编码

