ASCII码与Unicode码
一、ASCII码
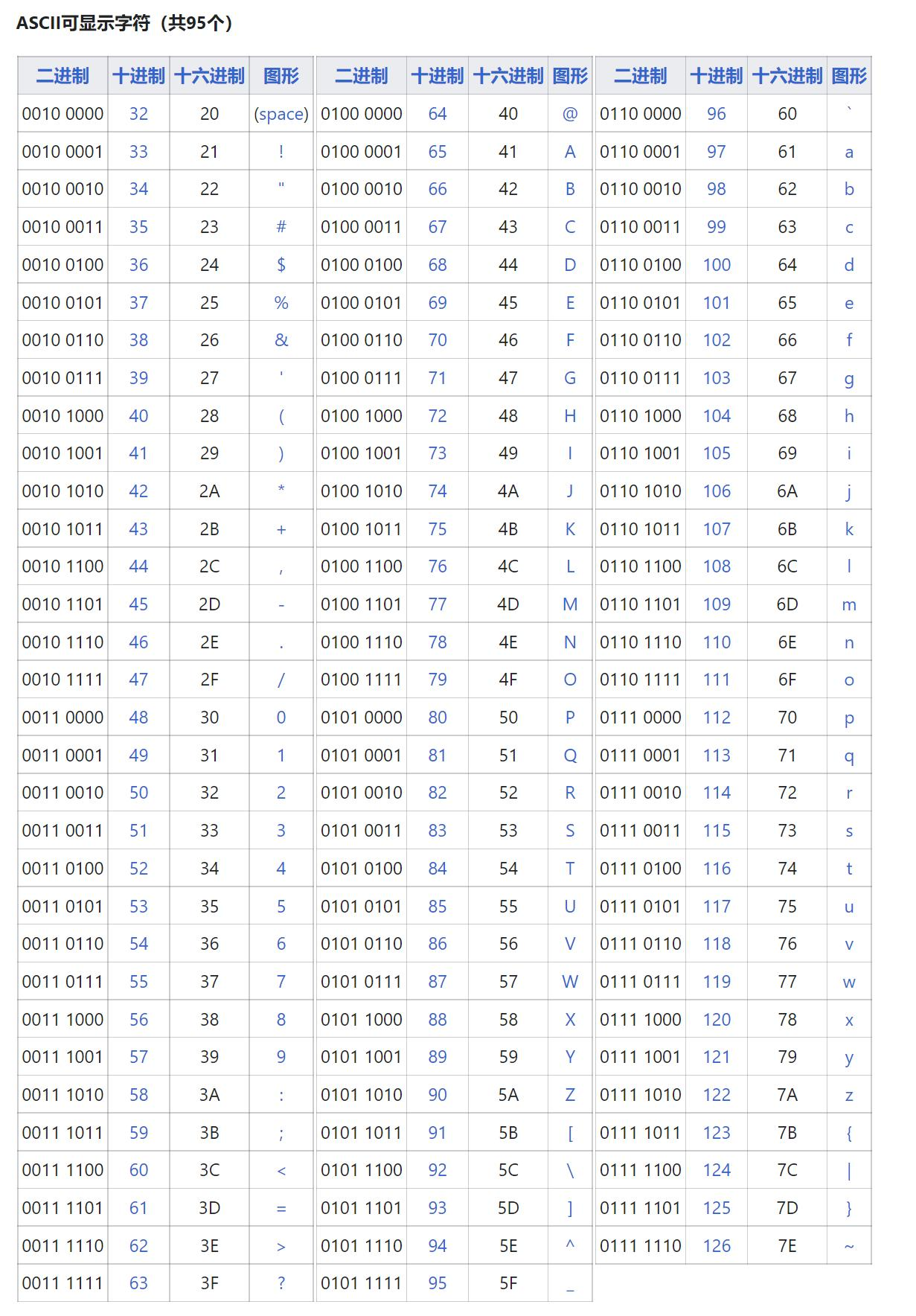
ASCII(American Standard Code for Information Interchange)美国信息交换标准代码,它是对字母、数字、符号进行二进制编码的标准。一个ASCII码长度是一个字节,也就是8个bit,最高位是0作为校验位,其余7位使用0和1进行组合(00000000~01111111(0X00~0X7F)),所以ASCII码共有128个。这128个字符包含33个控制字符和95个可显示字符。0-31以及127是控制字符,包含DEL删除,BS退格,CR回车等。32-126是可显示字符,其中32是回车,48-57是10个阿拉伯数字,65-90是26个大写的英文字母,97-122是26个小写的英文字母。
将这套字符集映射到0X00~0X7F二进制码的过程就称为基础ASCII编码,通过这个编码过程,计算机就将人类语言转化为自己的语言存储起来;反之,从磁盘读取二进制数并转化为字母数字等字符以供显示的过程就是解码了。
ASCII码表格
127个ASCII字符和数字是一一对应的关系,表格中展示的为十进制表示,在计算机传输和存储中,会把他们转换为二进制,比如数字0的十进制表示为48,转换为二进制就是00110000,在不同的设备中互相传输的就是这个二进制序列。
ASCII字符局限性
可以发现,ACSII字符最高位置0的情况下,最多表示128个字符,英文字符完全可以被编码,如果是其他语言,字符数量多于127个如何表示呢?一些国家对ASCII码做了扩展,让最高位也参与编码,这样ASCII码能表示的字符数量从128个上升到256个,这种编码ASCII也被成为扩展ASCII编码。这其中,最优秀的扩展方案是ISO 8859-1,通常称之为Latin-1。Latin-1利用128~255这128个二进制数,包括了足够的附加字符集来涵盖基本的西欧语言,同时在0~127的范围内兼容ASCII编码规则。
然而,扩展ASCII编码仍然有很大局限性,世界上有很多种语言文字,每种语言的字符数量不一,256个依然是不够用的。汉字的数量大约接近十万个,常用汉字大约六千个,如何实现汉字编码呢?此类情况,其他语言也是存在。每个国家都将自己的语言编码为某个标准,标准不统一,导致计算机设备在传输信息过程中出现乱码。Unicode编码的出现,Unicode字符集涵盖了世界上所有的文字和符号字符,Unicode编码方案为字符集中的每一个字符指定了统一且唯一的二进制编码,这就能彻底解决之前不同编码系统的冲突和乱码问题。这套编码方案简单来说是这样的:编码规范中含有17个组(称为平面),每一个组含有65536个码位(例如组0就是0X0000~0XFFFF),每一个码位就唯一对应一个字符,大部分的字符都位于字符集平面0的码位中,少量位于其他平面。
字符编码和字符代码的概念区分
既然提到了Unicode编码,那么常常与之相伴的UTF-8,UTF-16编码方案又是什么?其实到目前为止我们都一直混淆了两个概念,即字符代码和字符编码,字符代码是特定字符在某个字符集中的序号,而字符编码是在传输、存储过程当中用于表示字符的以字节为单位的二进制序列。ASCII编码系统中,字符代码和字符编码是一致的,比如字符A,在ASCII字符集中的序号,也就是所谓的字符代码是65,存储在磁盘中的二进制比特序列是01000001(0X41,十进制也是65),另外的,如在GB2312编码系统中字符代码和字符编码的值也是一致的,所以无形之中我们就忽略了二者的差异性。
而在Unicode标准中,我们目前使用的是UCS-4,即字符集中每一个字符的字符代码都是用4个字节来表示的,其中字符代码0~127兼容ASCII字符集,一般的通用汉字的字符代码也都集中在65535之前,使用大于65535的字符代码,即需要超过两个字节来表示的字符代码是比较少的。因此,如果仍然依旧采用字符代码和字符编码相一致的编码方式,那么英语字母、数字原本仅需一个字节编码,目前就需要4个字节进行编码,汉字原本仅需两个字节进行编码,目前也需要4个字节进行编码,这对于存储或传输资源而言是很不划算的。
因此就需要在字符代码和字符编码间进行再编码,这样就引出了UTF-8、UTF-16等编码方式。基于上述需求,UTF-8就是针对位于不同范围的字符代码转化成不同长度的字符编码,同时这种编码方式是以字节为单位,并且完全兼容ASCII编码,即0X00-0X7F的字符代码和字符编码完全一致,也是用一个字节来编码ASCII字符集,而常用汉字在Unicode中的字符代码是4E00-9FA5,在文末的对应关系中我们看到是用三个字节来进行汉字字符的编码。UTF-16同理,就是以16位二进制数为基本单位对Unicode字符集中的字符代码进行再编码,原理和UTF-8一致。
因此,我们可以看出,在目前全球互联的大背景下,Unicode字符集和编码方式解决了跨语言、跨平台的交流问题,同时UTF-8等编码方式又有效的节约了存储空间和传输带宽,因而受到了极大的推广应用。
讲清楚了字符编码的发展历史,容易让人明白为什么某一时刻就出现了某种编码方式,搞清楚了来龙去脉,对字符编码就好理解了。
在线ASCII编码转换
http://huashi123.cn/hanzidaquan/ascii.html
二、Unicode码
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。
Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。1990年开始研发,1994年正式公布。
它将世界上所有的文字用2个字节统一进行编码。Unicode用数字0-0x10FFFF来映射这些字符,最多可以容纳1114112个字符,或者说有1114112个码位。
python2.x默认的字符编码是ASCII,默认的文件遍码也是ASCII.
python 3.x默认的字符编码是unicode,默认的文件编码是utf-8。
所以,其实将字符串以Unicode码进行编码主要是针对python2.x。
python中的字符编码
讲清楚字符编码的基础概念后,我相信再来介绍python中的字符编码就会容易的多。
通过上一集我们知道,ASCII码(包括其最常见的超集Latin-1)依赖这样的一个假设,即每一个字符与一个字节相匹配,由于存在太多的字符,因此不可避免的会出现问题,Unicode字符集通过使用4个字节来表示1个字符,则解决了该问题。
首先来介绍一下Python中的两种字符串:
Python中有两种字符串:文本字符串和字节字符串。其中文本字符串类型被命名为str,内部采用Unicode字符集(兼容ASCII码),而字节字符串则直接用来表示原始的字节序列(用print函数来打印字节字符串时,若字节在ascii码范围内,则显示为ascii码对应的字符,其余的则直接显示为16进制数),该类型被命名为bytes。
看一个简单的例子:
1 s = 'apple' 2 b = b'apple' 3 print(b) 4 print(type(b)) 5 print(s) 6 print(type(s)) 7 8 b'apple' 9 <class 'bytes'> 10 apple 11 <class 'str'>
再近距离的看看bytes类型字节字符串,本质上它就是一串单字节16进制数
1 b = b'apple' 2 print(b[0]) 3 print(b[1:]) 4 print(list(b)) 5 6 97 7 b'pple' 8 [97, 112, 112, 108, 101]
那这和编码、解码有何关联呢?
从本质上来说,编码和解码就是str和bytes这两种字符串类型之间的互相转换。
str包含一个encode方法,使用特定编码将该字符串其转换为一个bytes,这称之为编码。bytes类包含了一个decode方法,也接受一个编码作为单个必要参数,并返回一个str,这称之为解码。这种转换操作是显式的操作,且必须根据数据被编码时采用的编码类型进行解码。
首先说说编码,即将unicode的str文本字符串转换为bytes的字节字符串,可以显式的传入指定编码(一般来说采用utf-8编码),或使用平台的默认编码。
1 s = 'π排球の' 2 b1 = s.encode('utf-8') 3 b2 = s.encode() 4 print(b1) 5 print(b2) 6 7 b'\xcf\x80\xe6\x8e\x92\xe7\x90\x83\xe3\x81\xae' 8 b'\xcf\x80\xe6\x8e\x92\xe7\x90\x83\xe3\x81\xae'
那么我们看看,在不写编码的时候,平台默认的编码方式到底是什么
1 import sys 2 print(sys.platform) 3 print(sys.getdefaultencoding()) 4 5 win32 6 utf-8
可以看出我这个平台默认选择的是utf-8编码方式。
接下来我们来比较一下unicode、latin-1、ASCII编码方式的兼容性问题:
首先,非ASCII字符无法使用ASCII编码转换成字节字符串
1 s = 'π排球の' 2 b = s.encode('ascii') 3 4 Traceback (most recent call last): 5 File "E:/12homework/12homework.py", line 2, in <module> 6 b = s.encode('ascii') 7 UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-3: 8 ordinal not in range(128)
其次,Latin-1和unicode编码方式不兼容。
例如,重音字符会在latin-1字符集和unicode字符集中同时存在,但是通过latin-1和unicode编码方式编出来的字节流是不一样的,注意,虽然unicode字符集是包含了latin-1字符集,但是不代表utf-8编码方式兼容latin-1编码方式。因为unicode字符集中除了ascii字符集外,都是采用多字节的编码方式,而latin-1一律采用单字节的方式
1 s = 'Äè' 2 print(s.encode('utf-8')) 3 print(s.encode('latin-1')) 4 5 b'\xc3\x84\xc3\xa8' 6 b'\xc4\xe8'
只有ascii字符集中的字符,三种编码方式得到的结果才完全一致。对unicode进行编码的时候,针对常规的7位ASCII文本,由于utf-8以及latin-1编码方式都是兼容ASCII的,所以结果都是一样的。
1 s = 'abc' 2 print(s.encode('utf-8')) 3 print(s.encode('latin-1')) 4 print(s.encode('ascii')) 5 6 b'abc' 7 b'abc' 8 b'abc'
那对应的,再来谈谈decode解码方法吧。
将bytes类型字符串转换成str类型的unicode文本字符串也是一样,要么指定编码参数,要么使用平台的默认参数。这个例子中,我们要操作的字节字符串b是通过utf-8编码方式对文本字符串'π排球の'编码而形成的。
1 b = b'\xe6\x8e\x92\xe7\x90\x83' 2 s1 = b.decode(encoding='utf-8') 3 s2 = b.decode() 4 s3 = b.decode(encoding='latin-1') 5 6 print(s1) 7 print(s2) 8 print(s3) 9 10 排球 11 排球 12 排çƒ
值得注意的是,最后一行代码想通过latin-1解码字节字符串,由于字节字符串是通过utf-8编码形成,因此这样解码形成得到的只能是乱码。
Utf-8编码是用两个字节来表示非ASCII的高128字符,而latin-1则是用一个字节来一一对应
计算机用二进制来存储信息,而却能在各种应用中显示我们需要的文字,这应该是字符编、解码的应用吧。
很对,下面我们来说说文本文件读取时的编、解码问题
当一个文件以文本模式打开的时候,被读取的二进制存储数据(也就是存储的字节字符串)会自动被解码(依据显式提供的编码名称或平台默认的编码名称),并且将其返回为一个str。写入文件时,会接受一个str,并且将其传输到文件之前自动编码成字节字符串以供磁盘存储。
当一个文件以二进制模式打开时,需要在open方法的模式字符串参数里添加一个b,此时读取的数据不会以任何方式解码,而是直接返回其原始内容,即一个bytes对象;写入文件时,接受一个bytes对象,并且将其传送到文件中且不进行修改。
在读取文本文件的时候,如果open函数没有声明他们如何编码,python3会因其所运行的系统而选取默认的编码方式,默认情况下,python3 期望文件使用 utf-8进行编码。但由于文件并不总是在同一个系统中被保存和打开,因此会带来乱码的风险,所以我们需要显式的指定编码。
补充的说明一下,可以很简单的进行一个分类:处理图像文件、设备数据流等,可以使用bytes和二进制模式文件处理;而如果要处理的内容实质是文本的内容,例如程序输出、HTML、国际化文本或CSV或XML文件,则可能要使用str和文本模式文件
例如,我们先把AÄBèC用UTF-8编码后存入utf-8data文件,再来读取他,具体看看这里是如何实现的。
1 s = 'AÄBèC' 2 3 with open('utf-8data','w',encoding='utf-8') as f: 4 f.write(s) 5 6 with open('utf-8data','r',encoding='utf-8') as f: 7 u_str = f.read() 8 print(u_str) 9 10 11 AÄBèC
这里用到的文件读写的方法后面的章节会详细介绍,现在知道他是什么就好了。
以二进制的形式读取文件。
还有一种我们之前介绍过的用法,文本字符串在存储到磁盘的时候会编码成字节字符,因此我们也可以先以字节字符串的形式从文件中将其读取,然后再进行解码。
这样做的原因有二,一种是所接收的可能是非文本数据,如一个图像文件;另一个潜在原因是无法确定所读取文本文件的编码,可能需要依据其他信息再确定:
1 with open('utf-8data', 'rb') as f: 2 byte_str = f.read() 3 4 print(byte_str) 5 print(byte_str.decode(encoding='utf-8')) 6 7 b'A\xc3\x84B\xc3\xa8C' 8 AÄBèC
字符串编、解码在python中很重要,特别是在网络爬虫等网络应用程序中,在后面的实际应用中会感受到他的作用会越来越明显。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号