零基础爬取堆糖网图片(二)---多线程版
零基础爬取堆糖网图片(二)---多线程版

全文介绍:
接着上篇文章,我们已经实现图片的下载,但是我们发现整个爬取过程中,因为使用了for循环嵌套,导致每次遍历,都会打开文件在关闭,打开文件在关闭(套娃)。所以需要注意for循环的使用,其次下载图片是整个程序中最耗时的,如果需要提升爬取速度,那么我们可以从这个方向入手,实现多线程爬取
涉及内容:
- 爬虫基本流程
- requests库基本使用
- urllib.parse模块
- threading模块
图例说明:
- 请求与响应
sequenceDiagram
浏览器->>服务器: 请求
服务器-->>浏览器: 响应
- 爬虫基本流程
graph TD
A[目标网站] -->|分析网站| B(url)
B --> C[模拟浏览器请求资源]
C -->D[解析网页]
D-->E[保存数据]
正文:
1.导入
import urllib.parse
import threading
import requests
2.发送请求,获取响应
def get_page(url):
page = requests.get(url)
page = page.content
# 将 bytes 转化为 字符串
page = page.decode('utf-8')
return page
3.关键字以及翻页
def pages_from_duitang(label):
url = 'https://www.duitang.com/napi/blog/list/by_search/?kw={}&start={}'
pages = []
# 将中文转化成url编码
label = urllib.parse.quote(label)
# 0-3600 步长100
for index in range(0, 3600, 100):
# 将这两个变量替换占位符{}
u = url.format(label, index)
print(u)
page = get_page(u)
pages.append(page)
return pages
4.获取一个页面上的所有图片子链接
def findall_pages(page, startpart, endpart):
all_string = []
end = 0
# -1代表找不到 意思就是匹配到就执行循环
while page.find(startpart, end) != -1:
# 匹配第一个字符,从下标0开始匹配到的位置下标,并将字符长短传给start变量
start = page.find(startpart, end) + len(startpart)
# 将从第一个需要匹配的字符串后面的字符开始,匹配第二个需要匹配的字符出现的位置,并将这个下标值赋给end变量
end = page.find(endpart, start)
# 切片 取两个所要匹配字符 之间的部分也就是图片url
string = page[start:end]
# 存入列表
all_string.append(string)
return all_string
5.爬取全部页面
def pic_url_from_pages(pages):
pic_url = []
for page in pages:
url = findall_pages(page, 'path":"', '"')
pic_url.extend(url) # 合并列表
return pic_url
6.下载图片
def pic_download(url, n):
r = requests.get(url)
path = r"C:\Users\Mark\Desktop\新建文件夹 (2)\%s.jpg" %n
with open(path, 'wb')as d:
d.write(r.content)
7.调用函数
之前的函数就像是一个一个的零件,现在我们要拼装这些零件,这个车才开的起来!😏
def main(label):
pages = pages_from_duitang(label)
pic_url = pic_url_from_pages(pages)
n = 0
for url in pic_url:
n += 1
print('正在下载第 {} 张图片'.format(n))
pic_download(url,n)
main('校花')
已完成
8.多线程的实现
栗子来了
排队上厕所:商城经常会有人排队上厕所,而一个厕所(进程)是可以有多个坑位(线程),每当有位置空着时就会有下一个人进来,进来后为了让别人知道这个位置有人了(避免争夺),避免尴尬,需要上锁,完事儿,出来时解锁就行,然后再有一个人进来......
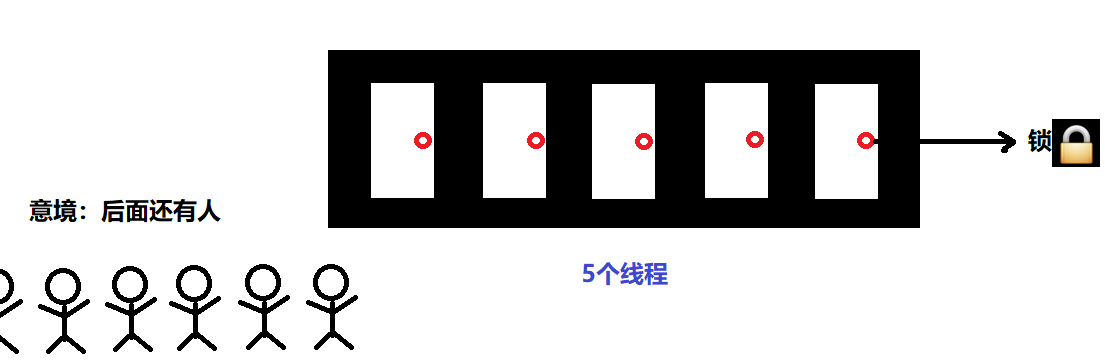
- 首先设置信号量
thread_lock = threading.BoundedSemaphore(value=5) # value 可以改,但不可过大
- 然后就是主函数中对于下载图片这个函数使用多线程
def main(label):
pages = pages_from_duitang(label)
pic_url = pic_url_from_pages(pages)
n = 0
for url in pic_url:
n += 1
print('正在下载第 {} 张图片'.format(n))
# 上锁
thread_lock.acquire()
## 下载 这个方法丢进线程池
t = threading.Thread(target=pic_download, args=(url, n))
t.start()
pic_download(url,n)
main('英雄联盟')
- 图片下载完毕,需要解锁
thread_lock.release()
效果:
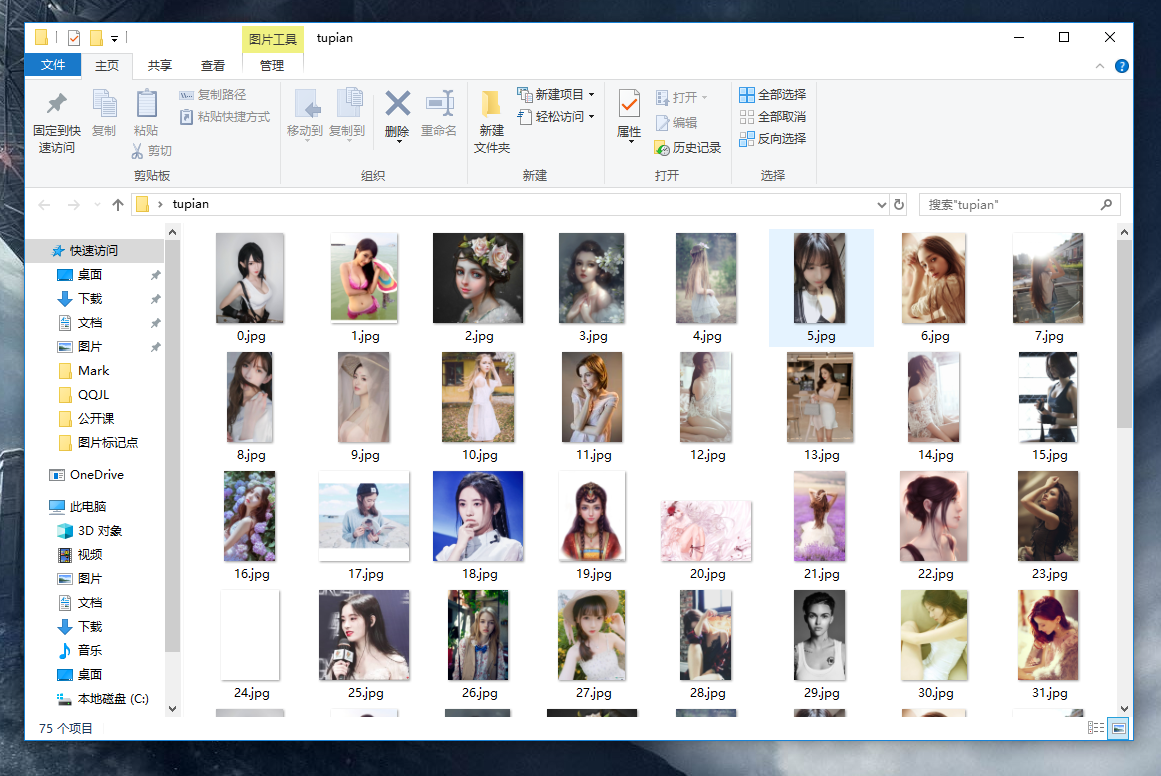
注意身体,就不放过多的正能量图片了


 浙公网安备 33010602011771号
浙公网安备 33010602011771号