
容器总结
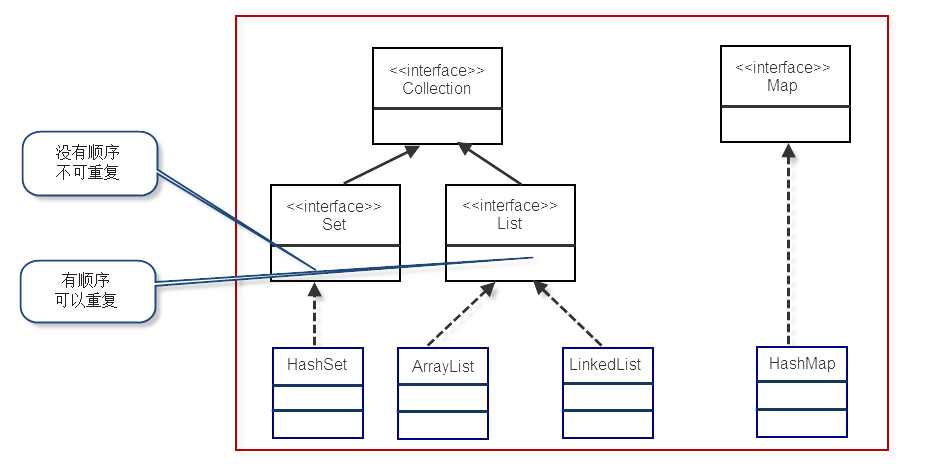
容器架构
数组就是一种容器,可以在其中放置对象或基本类型数据。
数组的优势:是一种简单的线性序列,可以快速地访问数组元素,效率高。如果从效率和类型检查的角度讲,数组是最好的。
数组的劣势:不灵活。容量需要事先定义好,不能随着需求的变化而扩容。
Collection
-
Collection表示一组对象,它是集中、收集的意思,就是把一些数据收集起来。 -
Collection接口的两个子接口:- List中的元素有顺序,可重复。常用的实现类有
ArrayList、LinkedList和 vector。
- List中的元素有顺序,可重复。常用的实现类有
Ø ArrayList特点:查询效率高,增删效率低,线程不安全。
Ø LinkedList特点:查询效率低,增删效率高,线程不安全。
Ø vector特点:线程安全,效率低,其它特征类似于ArrayList。
Set中的元素没有顺序,不可重复。常用的实现类有HashSet和TreeSet。
Ø HashSet特点:采用哈希算法实现,查询效率和增删效率都比较高。
Ø TreeSet特点:内部需要对存储的元素进行排序。因此,我们对应的类需要实现Comparable接口。这样,才能根据compareTo()方法比较对象之间的大小,才能进行内部排序。
泛型
本质是数据类型的参数化。可以把“泛型”理解为数据类型的一个占位符(形式参数),即告诉编译器,在调用泛型时必须传入实际类型。提高了代码可读性和安全性。<T,E,V>
Collection接口
Collection接口的两个子接口是List、Set接口。
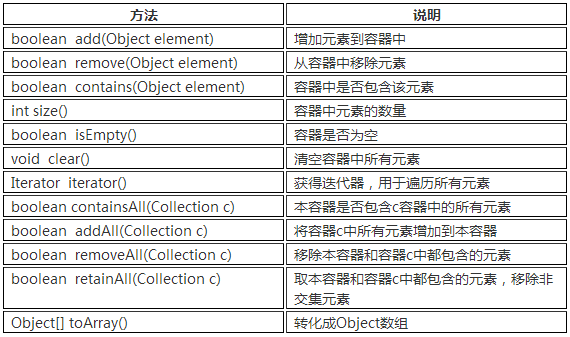
这里注意的是remove是移除元素,而不是删除元素,具体来说是删除了原来的引用,但是引用的对象还是存在。
前面的方法都是针对元素操作,后面的针对集合操作。
Collection<String> c = new ArrayList<>();
c.add("hello");
c.add("world");
Object[] obj = c.toArray();//返回的是Object
String[] str = c.toArray(new String[0]);//返回String
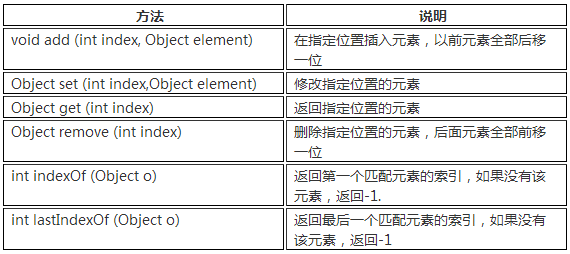
list
有序,可重复容器。
List接口常用的实现类有3个:ArrayList、LinkedList和Vector。
ArraryList
ArrayList底层是用数组实现的存储。 特点:查询效率高,增删效率低,线程不安全。我们一般使用它
增删效率低,本质是数组的复制。
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
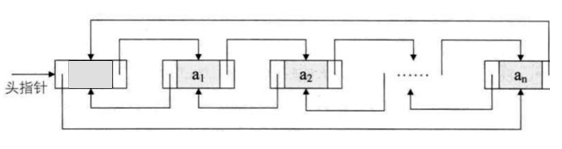
LinkedList
LinkedList底层用双向链表实现的存储。特点:查询效率低,增删效率高,线程不安全。
Vector向量
底层是用数组实现的List,相关的方法都加了同步检查,因此“线程安全,效率低”
Map
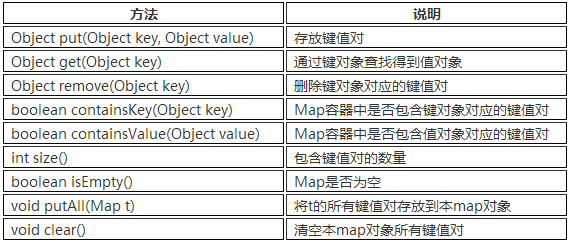
底层采用了哈希表存储数据,我们要求键不能重复,如果发生重复,新的键值对会替换旧的键值对。 HashMap在查找、删除、修改方面都有非常高的效率。
HashMap
HashMap底层实现采用了哈希表,这是一种非常重要的数据结构。对于我们以后理解很多技术都非常有帮助(比如:redis数据库的核心技术和HashMap一样),因此,非常有必要让大家理解。
数据结构中由数组和链表来实现对数据的存储,他们各有特点。
(1) 数组:占用空间连续。 寻址容易,查询速度快。但是,增加和删除效率非常低。
(2) 链表:占用空间不连续。 寻址困难,查询速度慢。但是,增加和删除效率非常高。
那么,我们能不能结合数组和链表的优点(即查询快,增删效率也高)呢? 答案就是“哈希表”。
哈希表的本质就是“数组+链表”。
TreeMap
TreeMap和HashMap实现了同样的接口Map,因此,用法对于调用者来说没有区别。HashMap效率高于TreeMap;在需要排序的Map时才选用TreeMap。
排序顺序需要实现Comparable接口。
HashTable
HashMap与HashTable的区别
-
HashMap: 线程不安全,效率高。允许key或value为null。
-
HashTable: 线程安全,效率低。不允许key或value为null。
Set
Set容器特点:无序、不可重复。
HashSet
HashSet是采用哈希算法实现,底层实际是用HashMap实现的(HashSet本质就是一个简化版的HashMap),因此,查询效率和增删效率都比较高。
TreeSet
TreeSet底层实际是用TreeMap实现的,内部维持了一个简化版的TreeMap,通过key来存储Set的元素。 TreeSet内部需要对存储的元素进行排序,因此,我们对应的类需要实现Comparable接口。这样,才能根据compareTo()方法比较对象之间的大小,才能进行内部排序。
Iterator
可边遍历边删除元素。
Collection工具类
类 java.util.Collections 提供了对Set、List、Map进行排序、填充、查找元素的辅助方法。
-
void sort(List)//对List容器内的元素排序,排序的规则是按照升序进行排序。 -
void shuffle(List)//对List容器内的元素进行随机排列。 -
void reverse(List)//对List容器内的元素进行逆续排列 。 -
void fill(List, Object)//用一个特定的对象重写整个List容器。 -
int binarySearch(List, Object)//对于顺序的List容器,采用折半查找的方法查找特定对象。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号