项目练习(一)APP热点标签分析
此项目侧重练习hive基本项目常识。
一、项目背景
项目背景:在移动APP满天飞的当下,如何做好APP的营销和推广至关重要,而该环节的关键在于能对APP做大众喜欢的关键字描述,从而提高APP的搜索命中率和下载率。
找到热度标签,蹭热度标签,往往可以提高相应APP的下载量和使用量。
二、需求分析
(1)爬取数据:6个字段,分别为(appId,app名称, 一级分类,二级分类,三级分类,Tags描述信息),但并不一定完全规整,视实际情况可能左对齐包括四个或五个或六个字段。
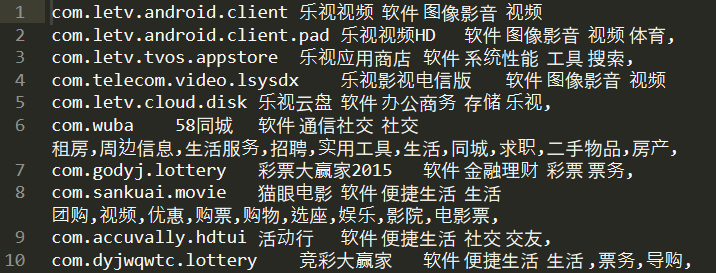
(2)保存到hive做进一步分析
通过大数据开发之hive数据仓库命令行形式,完成数据加载、udf/udaf/udtf函数、统计分析的任务,并演示项目效果即可。
三、主要思路
(1)创建对应的数据表1
(2)加载数据到表1
(3)创建一个表2保存标签和标签量
(4)对数据表1进行处理,“产生数据保存到表2”
四、开发过程
技术组成:hive sql+udf/udaf/udtf
开发规范:
4.0 prepare
(1)相关目录创建
config:存放相关配置变量
create:存放表结构数据
deal:具体的sql脚本
udf:udf/udaf/udtf相关的jar包
4.1 按步骤执行
(1) 输入、输出表设计到位。
(2) 将数据加载到输入表中。
(3) hivesql+udf/udaf/udtf实现热词统计与写入库表。
4.2 将所有流程串联到a_main.sh脚本中
待开发工作基本完成,需将项目的主体流程,
串联到a_main.sh当中,作为整个项目的主入口。
4.3详细讲解
(1)config:
vi set_env.sh
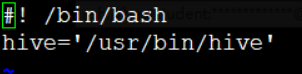
1、这条语句相当于定义hive变量
(2)create:
表1
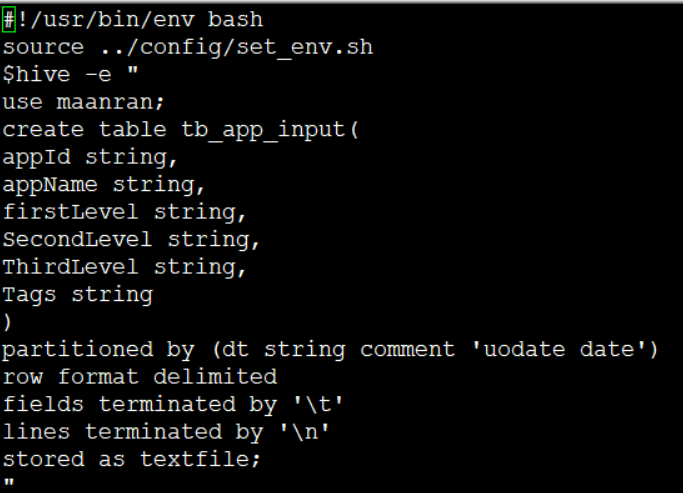
1、source语句相当于引入set_env.sh文件,即引入hive变量。
2、定义多个变量,方便后期修改方便。
3、hive -e 语句:保证可以在shell中执行HiveQL。
4、hive -e后可以跟""和'' ,但是''不会识别内容中的Hive变量,会认为是shell变量导致出错,所有建议使用""
5、如何决定创建外表/内表?
数据仓库可以分为三个模块(源数据、仓库、集市)
源数据:一般是load方式批量加载进来的数据,含有很多的脏数据,大多都是为外表,方便仓库多种使用
仓库:当建立好可靠的表结构时,将源数据的数据insert进来,可以建立内表。
表2
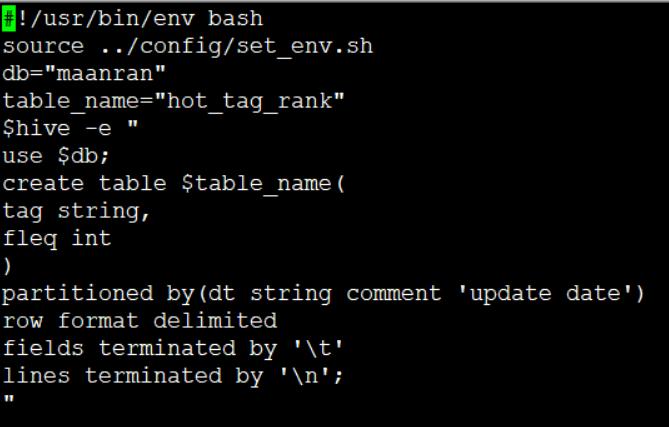
(3)deal:
加载数据到表1
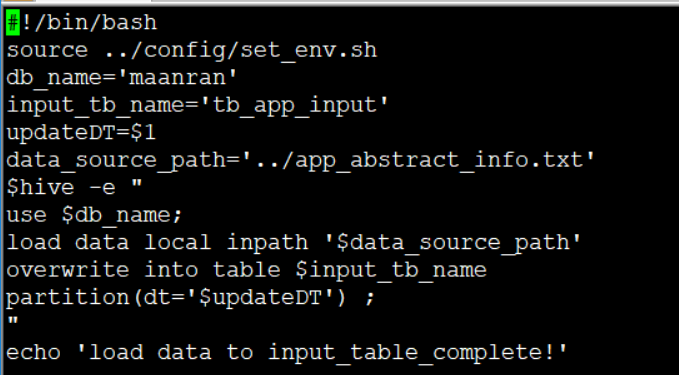
1、sh load_input.sh AAA BBB CCC
AAA代表传入的$1的参数 ,BBB代表传入的$2的参数,所有代表参数$0。
加载数据到表2
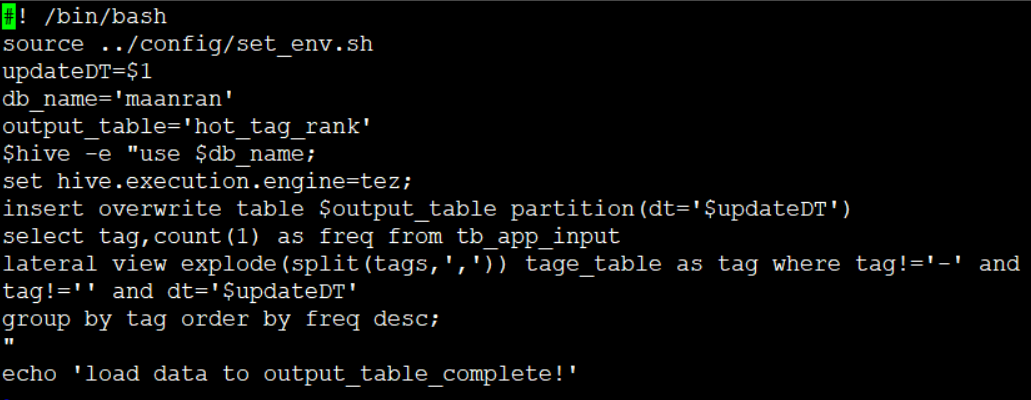
1、set hive.execution.engine=tez;设置执行引擎是tez,这个引擎比mr快一些
以上测试完成可以写main.sh来依次执行这些sh文件,创建表的文件可以不加在main.sh中,防止以后再使用时出现建表名冲突的问题。
总main
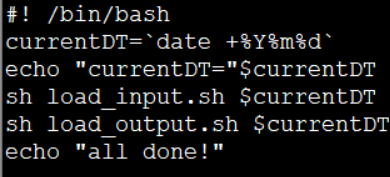
1、`反引号代表先执行``中的内容,在将返回值给currentDT
(4)udf:
本次项目暂时不涉及udf,但是作为开发规范还是要写好的!!
本人小白,在进阶中,如果有不对、不规范的地方,希望指正出来,感谢

 浙公网安备 33010602011771号
浙公网安备 33010602011771号