TensorFlow Object Detection API(Windows下训练)
本文为作者原创,转载请注明出处(http://www.cnblogs.com/mar-q/)by 负赑屃
最近事情比较多,前面坑挖的有点久,今天终于有时间总结一下,顺便把Windows下训练跑通。Linux训练建议仔细阅读https://zhuanlan.zhihu.com/p/27469690,我借鉴颇多,此外还可以参考GitHub上的官方文档https://github.com/tensorflow/models/tree/master/research/object_detection。
总体而言Windows下训练还是比较坑的,centos服务器上自己的模型已经训练完了,我也是为了测试而尝试。。。基本把坑趟了一遍。我是在办公电脑上测试的,没有GPU,还好内存是32G,训练期间CPU使用率基本保持在99%。
第一部分 PASCAL VOC数据集的介绍
person
bird, cat, cow, dog, horse, sheep
aeroplane, bicycle, boat, bus, car, motorbike, train
bottle, chair, dining table, potted plant, sofa, tv/monitor
二、2012年的挑战赛一共有5 个main tasks 和 2个 ``taster'' tasks:
1. Classification: 对每个类判断测试图片中是否存在该类的至少1个对象.
2. Detection: 对每个类判断测试图片中属于该类对象的外包边框.
3. Segmentation: 对测试图中的每个像素,判断该像素属于20个类对象还是属于背景,即图像的语义分割.
4. Action Classification: 对每个动作类别,判断测试图片中是否有人(已通过外包边框标明)正在做出相应的动作,动作共有10个分类:jumping; phoning; playing a musical instrument; reading; riding a bicycle or motorcycle; riding a horse; running; taking a photograph; using a computer; walking。此外,数据集中有一些人在做其他动作(不在10个分类中),作为干扰测试.
5. Large Scale Recognition: 这个比赛项目由ImageNet组织,他们的网站: http://www.image-net.org/challenges/LSVRC/2012/index
6. 2``taster'' tasks:Boxless Action Classification: 判断测试图中人是否在做相应动作,这些人仅通过身体某处的单个点标明,没有外包边框.Person Layout: 对测试图中的每个人(已通过外包边框标明),判断这些人的头、手、脚部位,并通过外包框标明。
三、目录结构:如图所示:


1.JPEGImages存放图片;
2. Annotation存放对图片的标注信息(XML文件),即外包边框bounding box的位置信息;
3. SegmentationClass和SegmentationObject存放了图片的分割前景。
4. ImageSets是对图片集合的描述,分别对应了不同的竞赛任务,例如Layout表示图片中人体部位的数据,Main表示每个图片包含的分类信息(20个类别),Segmentation表示用于分割的数据,2007没有action,2012有了action数据,表示图片中人的动作。
红框中的4个压缩包分别是2012和2007的test、trainval文件,把2007的test和trainval解压缩,2007的test和train目录结构是一致的,只是图片和标注内容互补。2012也是如此,在ImageSets的main中通过txt把数据集划分成train、train_test、train_val等几个部分。
以上文件下载并解压缩到D:\dataset\VOCdevkit目录下。
第二部分TensorFlowObjectDetectionAPI的训练详细步骤
这个API的主要任务是进行ObjectDetection,所以只会用到数据集中的前三个目录,这里使用VOC2012进行训练。
一、数据格式转换
在第一部分介绍中,我已经把PascalVOC数据集下载到D:\dataset\VOCdevkit目录下,如果要制造自己的数据集,可以仿照VOC的目录结构,通过lableImg工具进行标注,具体就不演示了,可以参考的博客很多。
data_dir, year, 'ImageSets', 'Main',FLAGS.set + '.txt'
VOC数据集和转换后tfrecord数据集都存放在D:\dataset目录下,这里需要为tfrecord新建一个文件夹D:\dataset\TFrecord,并在TFrecord下新建文件夹data。完成后可以运行命令:
python create_pascal_tf_record.py --data_dir=D:\dataset\VOCdevkit --year=VOC2012 --set=train --output_path=D:\dataset\TFrecord\data\pascal_train.record
上面的命令中,data_dir为存放的VOC数据集目录,year参数只接受VOC2012和VOC2007两个数据集,这里选用了VOC2012,如果自己标注了数据,请按照VOC目录结构存放,set表示使用VOC2012的train部分进行训练,大概5700多张图片,output_path为record数据集的输出目录,就是刚才新建的data文件夹。
二、下载预训练模型
通常模型的训练都不是从0开始的,利用fine-tuning的思想在已有模型基础上训练可以有一个好的performance,https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/detection_model_zoo.md官网上提供了5个模型,大家可以自行下载,这里我下载了mAP比较高的faster_rcnn_inception_resnet_v2_atrous_coco,这是一个coco数据集训练的模型,解压缩后把其中的model.ckpt.*三个文件复制到D:\dataset\TFrecord\models下,没有models目录需要新建一个。
三、修改配置文件
刚才下载的数据集是faster_rcnn_inception_resnet_v2_atrous_coco,在object_detection\samples\configs目录下找到对应的.config文件,如果没有,可以到https://github.com/tensorflow/models/tree/master/research/object_detection/samples/configs复制对应的config文件, 把faster_rcnn_inception_resnet_v2_atrous_coco.config放到预训练模型目录下:D:\dataset\TFrecord\models
打开faster_rcnn_inception_resnet_v2_atrous_coco.config,修改num_classes为你自己的num_classes,这里VOC2012有20个分类,所以修改为20。然后修改其中5个路径:
112行 fine_tune_checkpoint: "D:\\dataset\\TFrecord\\models\\model.ckpt" 127行 input_path: "D:\\dataset\\TFrecord\\data\\pascal_train.record" 129行 label_map_path: "D:\\dataset\\TFrecord\\data\\pascal_label_map.pbtxt" 141行 input_path: "D:\\dataset\\TFrecord\\models\\pascal_val.record" 143行 label_map_path: "D:\\dataset\\TFrecord\\models\\pascal_label_map.pbtxt"
其他训练的配置信息可以自己研究一下,可以针对自己的数据集进行调整。
四、开始训练
因为python环境变量配置问题,这里Windows下和Linux也有不同,在object_detection中训练的文件为train.py,我们打开可以看到里面的model都是通过object_detection来加载的。

python train.py --train_dir=D:\dataset\TFrecord\train --pipeline_config_path=D:\dataset\TFrecord\models\faster_rcnn_inception_resnet_v2_atrous_coco.config
第三部分 可能产生的错误
一、执行python train.py报错:trainer.py“ModuleNotFoundError: No module named 'deployment'”,或者报错No module named 'nets'
- 错误原因,这两个model都是在TensorFlow/models/slim中,如果你阅读了我的上一篇文章http://www.cnblogs.com/mar-q/p/7459845.html,就可以知道,需要把models/slim加入到PYTHONPATH环境变量中。
二、运行训练后报错:“WARNING:root:Variable ……not available in checkpoint”
- 错误路径train.py->trainer.py->train()->init_saver = tf.train.Saver(available_var_map),产生原因,第2步和第3步中预训练模型和config文件没有对应起来,请在官网下载相匹配的预训练模型和config文件。
三、其他错误
- 如果还报一些ModuleNotFoundError错误建议把object_detection目录下的.pyc文件清空一下再执行train。
训练情况:
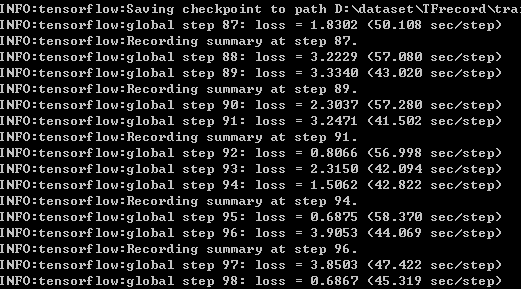

综上,如果有可能。。。Windows下的配置还是很糟心,奇葩问题比较多,建议还是在Linux下训练,明天周末,我先丢在机器上跑吧。。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号