


面试题
python 面试题
基础:
一、Http状态码中500、501、502、504有什么区别
-
500-Internal Server Error,服务器遇到了不可预料的错误,不能完成客户端的请求
-
501-Not Implemented,服务端不支持实现请求所需要的功能,页眉值指定了实现请求所需要的配置,例如:服务器发出了一个服务端不支持的put请求
-
502- Bad Gateway,服务器作为网关和代理时,为了完成客户端对下一个服务器的请求,但该服务器返回了非法的应答,亦可说web服务器作为网关和代理服务器时,收到了无效的响应。
-
504-Gate Timeout,由作为网关或代理服务器时使用,表示不能及时的从远程服务器及时获得应答
二、请简要描述什么是RESTful?
- RESTful,翻译成中文,资源状态转换,即把后端的数据/文件都看成资源,那么接口请求数据,本质上来说就是对资源的请求了,web项目中请求资源,无非就是增删改查,即在地址中写上要请求的资源是哪一个,然后加上http请求动词,来说明对资源进行的哪一种操作。
三、在一个CentOS 6的设备上,如何查看CPU、MEM、磁盘IO、网络流量、fd使用情况?
-
查看CPU使用情况的命令
$ vmstat 5 ---------每5秒刷新一次,最右侧有CPU的占用率的数据 $ top ---------top 然后按Shift+P,按照进程处理器占用率排序 -
查看内存(MEM)使用情况的命令
$ free ---------top 然后按Shift+M, 按照进程内存占用率排序 $ top
四、客户端请求API服务连接不上时,如何判断是网络问题,还是服务问题?
ping localhost可以判断本机有没有问题
ping 127.0.0.1可以判断本机网络
ping网关 可以判断网关通道
ping 8.8.8.8可以判断网络
ping 目标服务器 可以判断服务器网络
五、什么是跨域?如何设置允许跨域
-
跨域是指从一个域名的网页去请求另一个域名的资源,比如:从
www.baidu.com去访问www.taobao.com的资源。定义:当一个请求URL的协议、域名、端口的其中任何一项与当前页面的url不同时,则即为跨域。 -
为什么要限制跨域? 主要就是安全问题的考虑:如果一个网站可以随意的访问另一个网站的资源,那么可能在用户完全不知情的情况下出现安全问题,比如以下问题就可能出现安全问题:
- 用户访问
www.mybank.com,登陆并进行网银操作,这时cookie啥的都生成并存放在浏览器 - 用户突然想起件事,并迷迷糊糊地访问了一个邪恶的网站
www.xiee.com - 这时该网站就可以在它的页面中,拿到银行的cookie,比如用户名,登陆token等,然后发起对
www.mybank.com的操作。 - 如果这时浏览器不予限制,并且银行也没有做响应的安全处理的话,那么用户的信息有可能就这么泄露了。
- 用户访问
-
为什么要跨域?既然有安全问题,那为什么又要跨域呢? 有时公司内部有多个不同的子域,比如一个是
location.company.com,而应用是放在app.company.com, 这时想从app.company.com去访问location.company.com的资源就属于跨域。 -
怎么允许跨域?(1)CORES(跨域资源共享),定义了在访问跨域资源时,客户端与服务端该如何沟通,cores背后的基本思想就是通过自定义的HTTP的头部使服务器与客户端沟通,从而决定响应成功还是失败。服务端对cores的支持,主要是通过
Access-Control-Allow-Origin来进行的,如果浏览器检测到相应的设置,就会允许ajax访问。只需要在后台中加上响应头来允许域请求!在被请求的Response header中加入以下设置,就可以实现跨域访问了。//指定允许其他域名访问 'Access-Control-Allow-Origin:*'//或指定域 //响应类型 'Access-Control-Allow-Methods:GET,POST' //响应头设置 'Access-Control-Allow-Headers:x-requested-with,content-type'(2)JSONP是JSON with Padding(填充式json)的简写,是应用JSON的一种新方法,只不过是被包含在函数调用中的JSON,例如:
callback({"name","trigkit4"});JSONP由两部分组成:回调函数和数据。回调函数是当响应到来时应该在页面中调用的函数,而数据就是传入回调函数中的JSON数据。JSONP的原理:通过script标签引入一个js文件,这个js文件载入成功后会执行我们在url参数中指定的函数,并且会把我们需要的json数据作为参数传入。所以jsonp是需要服务器端的页面进行相应的配合的。(即用javascript动态加载一个script文件,同时定义一个callback函数给script执行而已。
在js中,我们直接用
XMLHttpRequest请求不同域上的数据时,是不可以的。但是,在页面上引入不同域上的js脚本文件却是可以的,jsonp正是利用这个特性来实现的。 例如:有个a.html页面,它里面的代码需要利用ajax获取一个不同域上的json数据,假设这个json数据地址是http://example.com/data.php,那么a.html中的代码就可以这样:
<script type="text/javascript"> function dosomething(jsondata){ //处理获得的json数据 } </script> <script src="http://example.com/data.php?callback=dosomething"></script>js文件载入成功后会执行我们在url参数中指定的函数,并且会把我们需要的json数据作为参数传入。所以jsonp是需要服务器端的页面进行相应的配合的。
<?php $callback = $_GET['callback'];//得到回调函数名 $data = array('a','b','c');//要返回的数据 echo $callback.'('.json_encode($data).')';//输出 ?>最终,输出结果为:
dosomething(['a','b','c']);如果你的页面使用jquery,那么通过它封装的方法就能很方便的来进行jsonp操作了。
<script type="text/javascript"> $.getJSON('http://example.com/data.php?callback=?,function(jsondata)'){ //处理获得的json数据 }); </script>jquery会自动生成一个全局函数来替换callback=?中的问号,之后获取到数据后又会自动销毁,实际上就是起一个临时代理函数的作用。$.getJSON方法会自动判断是否跨域,不跨域的话,就调用普通的ajax方法;跨域的话,则会以异步加载js文件的形式来调用jsonp的回调函数。JSONP的优缺点
JSONP的优点是:它不像
XMLHttpRequest对象实现的Ajax请求那样受到同源策略的限制;它的兼容性更好,在更加古老的浏览器中都可以运行,不需要XMLHttpRequest或ActiveX的支持;并且在请求完毕后可以通过调用callback的方式回传结果。JSONP的缺点则是:它只支持GET请求而不支持POST等其它类型的HTTP请求;它只支持跨域HTTP请求这种情况,不能解决不同域的两个页面之间如何进行
JavaScript调用的问题。CORS和JSONP对比
CORS与JSONP相比,无疑更为先进、方便和可靠。
1、 JSONP只能实现GET请求,而CORS支持所有类型的HTTP请求。 2、 使用CORS,开发者可以使用普通的XMLHttpRequest发起请求和获得数据,比起JSONP有更好的错误处理。 3、 JSONP主要被老的浏览器支持,它们往往不支持CORS,而绝大多数现代浏览器都已经支持了CORS)。
Python:
一、有一个Python列表 a=[1, 5, 3, 4, 2]
a) 取最后一个元素
a[-1]
b) 列表反转
a[0:0:-1]
c) 取出索引位置2,3的元素,和 索引2到最后一个元素
a[2:4]
a[2:]
二、列表sort方法和sorted的区别是什么?
-
sort()是列表类型的方法,只适用于列表;
-
sorted()是内置函数,支持各种容器类型。它们都可以排序,且用法类似,但sort()是在原地排序的,不会返回排序后的列表,而sorted()是返回新的排序列表
三、有一个列表数据,结构为 a=[{“id”:3 }, {“id”:5}, {“id”:1}],根据列表中每个元素中的id进行排序
l = sorted(a,key=lambda x:x['id'])
#其中sorted会接受一个可迭代对象,并会循环这个可迭代对象,将拿到的每一个值当做参数传给x,冒号后面的值就是返回值,即排序的依据
四、如有一个需求,需要爬取网页,并阐明多线程抓取程序是否比单线程性能有提升,并解释原因
- 多线程要比单线程性能高,原因是多线程是异步爬取的,单线程是串行的 ,效率上要慢很多
五、Python中的变量作用域(变量查找顺序)
全局命名空间:在我们写的py文件中,函数外面的变量;局部命名空间:函数内部声明的变量,函数执行时创建,;内置命名空间:python最开始的时候会创建自己的一个命名空间,
当以一个变量要被引用时:局部命名空间--全局命名空间--内置命名空间
六、python中如何动态获取和设置对象的属性
dir([obj])---调用这个方法会返回包含本对象的大多数的属性及方法列表(不包含一些特殊的属性),obj是默认的是本模块的对象
hasattr(obj,attr)--hasattr会判断传入的对象obj是否含有attr这个属性,返回值True/Flase
getattr(obj, attr)--调用这个方法将返回obj中名为attr值的属性的值,例如如果attr为’bar’,则返obj.bar。
setattr(obj, attr, val)--调用这个方法将给obj的名为attr的值的属性赋值为val。例如如果attr为’bar’,则相当于obj.bar = val。
七、Python里面如何拷贝一个对象?(赋值,浅拷贝,深拷贝的区别)
赋值:赋值没有创建新的空间,是多个变量指向同一个内存地址
浅拷贝:l2=l1[:]和l2=l1.copy(),只拷贝第一层元素,会创建一个新的容器,但是新的容器中元素和原容器中的元素指向同一个内存地址
深拷贝:不可变数据类型和原容器的元素指向同一个内存地址,可变数据类型会创建一个新的容器
八、如何用Python来进行查询和替换一个文本字符串?
a = [[1,2],3,4,'fdesz','sfe']
for i in range(len(a)):
if type(a[i]) == type('as'):
a[i]=0
print(a)
九、Python中如何实现一个单例模式
单例模式:一个类只能实例化一个对象,无论实例化多少次,始终只有一个对象,这个对象不是个性化的,主要是实例化对象之后用来去执行类中的方法
class A:
__instance = None
def __new__(cls, *args, **kwargs):
if cls.__instance is None:
obj = object.__new__(cls)
cls.__instance = obj
return cls.__instance
def func(self):
print(self.__instance)
a = A()
a.func() # <__main__.A object at 0x002F5F30>
b = A() # b还是a对象
print(b is a) # True
__new__和__init__的区别
__new__():构造方法,创造并返回一个新对象
__init__():主要是在实例化对象之时自动执行,在__new__之后执行
十、当读取滚动更新的日志文件,每次启动可以根据上次读取到的位置继续进行
十一、使用Python,统计一个文本文件中大写字母的数量
import re
with open('aa',mode='r',encoding='utf-8')as f:
a = f.read()
c =re.findall('[A-Z]',a)
print(len(c))
十二、Python是如何进行内存管理的
- python的存储问题
(1)由于python中万物皆对象,所以python的存储问题即是对象的存储问题,并且对于每个对象,python会分配一块内存去存储它
(2)对于整数和短小的字符等,python会执行缓存机制,即将这些对象进行缓存,不会为相同的对象分配多的内存空间
(3)容器对象,如列表,元祖,字典等,存储的其他对象,仅仅是对其他对象的引用,即地址,并不是对象本身
-
引用计数:
(1)一个对象会记录着引用自己的对象个数,每增加一个引用,个数加一,每减少一个引用,个数减一 (2)查看对象引用个数的方法:导入sys模块,使用模块中的getrefcount(对象)方法,由于这里也是一个引用,故输出的结果多一 (3)增加引用个数情况: 1.对象被创建p=Person(),+1; 2.对象被引用p1=p,+1; 3.对象被当做参数传入函数func(object),+2,原因是函数中有两个属性在引用该对象; 4.对象存储到容器对象中,+1; (4)减少引用个数的情况: 1.对象的别名被销毁 del p,-1; 2.对象的别名被赋予其他对象,—1; 3.对象离开自己的作用域,如getrefcount(对象)方法,每次用完后,其对对象的那个那个作用域就会消失,-1; 4.对象从容器中被删除,或者容器对象被销毁,-1; (5)引用计数法: import sys class Person(object): pass p = Person() p1=p print(sys.getrefcount(p)) #3 p2=p1 print(sys.getrefcount(p)) #4 p3=p2 print(sys.getrefcount(p)) #5 del p1 print(sys.getrefcount(p)) #4 #多一个引用,结果加1,销毁一个引用,结果减少1 (6)引用计数器机制:利用引用计数器方法,在检测到对象引用个数为0时,对普通的对象进行释放内存的机制 -
循环引用问题:
(1)循环引用即对象之间相互进行引用,出现循环引用后,利用上述的引用计数机制无法对循环引用中的对象进行空间释放,这就是循环引用问题 (2)循环引用形式; class Person(object): pass class Dog(object): pass p = Person() d = Dog() p.pet = d d.master = p 即对象p中的属性引用d,而对象d中属性同时来引用p,从而造成仅仅删除p和d对象,也无法释放其内存空间,因为他们依然在被引用。深入解释就 是,循环引用后,p和d被引用个数为2,删除p和d对象后,两者被引用个数变为1,并不是0,而python只有在检查到一个对象的被引用个数为0 时,才会自动释放其内存,所以这里无法释放p和d的内存空间 -
垃圾回收(底层层面--原理):
(1)垃圾回收的作用:从经过引用计数器机制后还没有被释放掉内存的对象中,找到循环引用对象,并释放掉其内存 (2)垃圾回收检测流程: 1.任何找到循环引用并释放内存: 1.收集所有容器对象(循环引用只针对于容器对象,其他对象不会产生循环引用),使用双向链表(可以看作一个集合)对这些对象进行引用; 2.针对每一个容器对象,使用变量gc_refs来记录当前对应的应用个数; 3.对于每个容器对象,找到其正在引用的其他容器对象,并将这个被引用的容器对象引用计数减去1; 4.经过步骤3后,检查所有容器对象的引用计数,若为0,则证明该容器对象是由于循环引用存活下来的,并对其进行销毁 2.如何提升查找循环引用过程的性能:由一可知,循环引用查找和销毁过程非常繁琐,要分别处理每一个容器对象,所以python考虑一种改善性能的做法,即分代回收。首先是一个假设--如果一个对象被检测了10次还没有被销毁,就减少对其的检测频率;基于这个假设,提出一套机制,即分代回收机制。
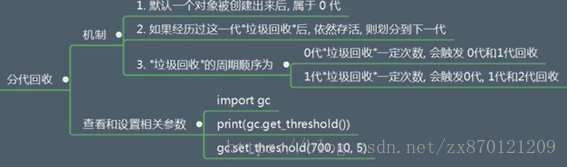
- 垃圾回收时机(应用层面--重点)
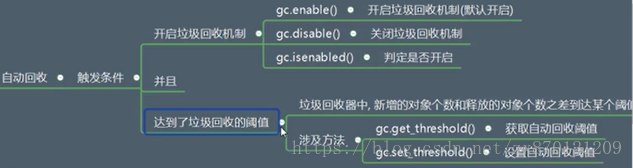
(1)自动回收:(见上图)
(2)手动回收:这里要使用gc模块中的collect()方法,使得执行这个方法时执行分代回收机制
import objgraph
import gc
import sys
class Person(object):
pass
class Dog(object):
pass
p = Person()
d = Dog()
p.pet = d
d.master = p
del p
del d
gc.collect()
print(objgraph.count("Person"))
print(objgraph.count("Dog"))
其中objgraph模块的count()方法是记录当前类产生的实例对象的个数
- 综上所述,python的内存管理机制就是引用计数器机制和垃圾回收机制的混合机制
十三、64匹马,8个赛道,找出跑得最快的4匹马,至少比赛几场?,请附解题过程
答案转载:https://blog.csdn.net/u013829973/article/details/80787928
十四、使用装饰器对如下函数,计算执行时间
def demo():
Import random, time
s = random.randint(1,10)
time.sleep(s)
print(“Hello World!”)
import random,time
def func(x): # x=demo
def inner(*args,**kwargs):
start_time = time.time()
ret = x() #真正的执行demo函数
total_time = time.time()-start_time
print('run_time',total_time)
return ret
return inner
@func #相当于 demo=func(demo)
def demo():
s = random.randint(1,10)
time.sleep(s)
print('hello world')
demo() #执行inner函数
打印结果:
hello world
run_time 7.00042200088501

