简单的验证码识别
https://blog.csdn.net/qq_35923581/article/details/79487579
这是我尝试写的第一篇技术博客,借鉴了很多博客和教程,写出了自己的代码,代码较为冗杂而且程序十分耗时。所以本文主要提供验证码识别的一个简单的思路,代码实现的部分还望各位大佬指点。
看了好几篇验证码图片识别的博文,不难归纳出验证码识别的大概思路是收集训练集——>图像处理——>得到图片特征值——>训练——>识别,其中图像处理部分又包括了灰度化、二值化、去噪、分割等过程。本文将尽量有详有略地讲述整个过程,以及本菜鸡在开发过程中遇到的问题。
话不多说,现在开始。
一、训练集的收集
要收集足够多的验证码,只需要写一个简单的爬虫,去一些各大网站的登录系统爬取就好。本菜鸡爬的是自己学校教务系统的登录网站,所以不太方便附上代码。本菜鸡总共爬取了500张验证码作为训练集,以及200张验证码用于测试,并已将自己得到的验证码放到了github上,github地址在文末给出。
这一过程需要注意,必须要手动输入这些验证码的答案,并将这些答案保存下来。而且为了提高识别的正确率,需要检查自己输入的验证码内容是否有误
接下来我们就要对收集到的训练集进行处理。
二、图像处理
以下用到了Python3的PIL(Pillow)库:
1、干扰线的处理
让我们先来看看得到验证码图片:

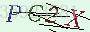
我们可以看到,每一张验证码图片上,都有很多的干扰线,虽然这些干扰线不会影响到我们自己识别验证码,但它们会极大地干扰到机器对验证码识别的正确率。本菜鸡曾经测试过,若不去掉这些干扰线,无论怎么优化算法,最终的识别正确率都在40%左右徘徊,所以这些干扰线是一定要尽量去消除的。当然,我们可以选择将图片灰度化、二值化后再去尝试去除干扰线,但本菜鸡试过很多次后,发现在原图片消除干扰线的效果是最好的。
那么问题来了,我们要怎么去掉这些干扰线呢?
其实大家可以通过目测发现:这些干扰线都是黑色的!
那我们是不是把图片上的所有黑色去掉就好了呢?其实也并不完全是如此。我们都知道,每一种颜色都有它的RGB值,本菜鸡在看了一遍收集到的验证码之后,就开始猜想:这些干扰线颜色的RGB值是不是都在一个范围内?
我们假定两种颜色的RGB的红黄蓝三个值相差均小于10,则认为这两种颜色是同一种颜色,例如,假定(0,0,0)和(10,10,10)是同一种颜色,基于这个假定,我们可以将一张验证码图片所有像素点的颜色分类,并存储不同种类颜色的相应点的坐标。例如:红色:(1,1),(1,2)……
1 from PIL import Image 2 from PIL import ImageDraw 3 import os 4 5 now_path = str(os.getcwd()).replace('\\','/') + "/" #得到当前目录 6 7 # 判断是否为同一种类的颜色 8 def isSameColor(a,b): 9 return abs(a[0]-b[0])<10 and abs(a[1]-b[1])<10 and abs(a[2]-b[2])<10 10 11 # 得到不同种类颜色的坐标 12 def divideColor(image): 13 color_map = {} 14 for i in range(image.size[0]): 15 for j in range(image.size[1]): 16 now_color = image.getpixel((i,j)) #得到该点的RGB值,注意参数是一个元组 17 flag = 1 18 for key in color_map: 19 if isSameColor(key,now_color): 20 flag = 0 21 color_map[key].append((i,j)) #若是相同种类的颜色,记录当前坐标 22 if flag: 23 color_map[now_color] = [(i,j)] #否则添加一种新的颜色 24 return color_map
得到了各种颜色对应的坐标,接下来我们可以用这些颜色和坐标在空白图上画点,找出干扰线所对应的颜色
1 # 在空白图上画点 2 def divideDraw(color_map): 3 save_path = now_path + "pixel/" # 新图的存储目录 4 for key in color_map: 5 now_image = Image.new('RGB',(90,32),(255,255,255)) # 新建一张图,它是RGB类型(第一个参数为类型)的、 6 # 尺寸为90*32(第二个参数为尺寸)、背景为白色(第三个参数为背景色) 7 drawer = ImageDraw.Draw(now_image)# 新建画笔 8 for x in color_map[key]: 9 drawer.point(x,key)# 描点画图 10 now_image.save(save_path + str(key) + ".png")# 将得到的图存起来 11 12 test_image = Image.open(now_path + "captcha/0001.png")# 打开一张验证码 13 divideDraw(divideColor(test_image))

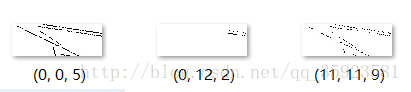
对第一张图处理后,我们得到了很多张图,根据截图里的三张图,我们可以知道干扰线的RGB的三个值在0~21之间。对多张图处理后,本菜鸡发现干扰线的RGB值大概在0~15之间,我们可以看看RGB值和颜色的对应表来证实我们的猜测 (注意,如果RGB范围设置的过大,会导致验证码也被清除)。 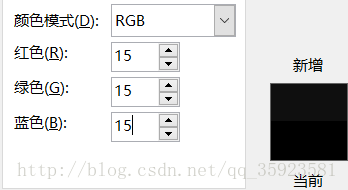
于是,我们可以根据得到的干扰线的RGB范围,来去除验证码中的干扰线。
# 清除所有黑色点,after_table_b是用于描点画图的
def clear_black(image, x, y, after_table_b):
now = image.getpixel((x,y))
if now[0]<=15 and now[1]<=15 and now[2]<=15:
after_table_b[y][x] = (255,255,255) #如果是该像素点是黑色的,则直接将它暴力设置为白色
else:
after_table_b[y][x] = now #否则就设置成它原来的颜色
前面三张验证码去除了干扰线后的效果如下: 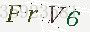

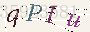
我们可以看到,虽然仍有很多黑点残留,但大部分的干扰线已经被去除掉,并且这些黑点我们在后续的图像处理中也能将它们消除掉,所以本菜鸡决定先不管它们,再将处理后的验证码进行下一步的处理。
2、灰度化和二值化
在本菜鸡看来,之所以要将图片灰度化和二值化,是为了简化后续的去噪工作,并让图片的特征值变得更简单。
这一部分我只简单介绍一下原理,并介绍一下怎么用Pillow库(可以认为Pillow是PIL库的Python 3版本)完成验证码的灰度化和二值化
什么叫灰度图?任何颜色都有红、绿、蓝三原色组成,假如原来某点的颜色为RGB(R,G,B),那么,我们可以通过下面几种方法,将其转换为灰度:
1.浮点算法:Gray=R*0.3+G*0.59+B*0.11
2.整数方法:Gray=(R*30+G*59+B*11)/100
3.移位方法:Gray =(R*76+G*151+B*28)>>8;
4.平均值法:Gray=(R+G+B)/3;
5.仅取绿色:Gray=G;
通过上述任一种方法求得Gray后,将原来的RGB(R,G,B)中的R,G,B统一用Gray替换,形成新的颜色RGB(Gray,Gray,Gray),用它替换原来的RGB(R,G,B)就是灰度图了。
(以上介绍来自百度百科)
虽然看起来非常复杂,但运用了强大的pillow库后,完成灰度化的操作只需要一条语句:
now_image = now_image.convert("L") # "L"表示灰度图
灰度化后的成果图: 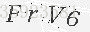
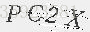
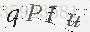
接下来我们进行二值化。
二值化的原理特别简单,就是把图片上所有像素点的灰度值,转化成0(0表示纯黑色)或255(表示纯白色),(注:二值图中每个像素点的值为0或1,即将一个像素点的灰度值设为255,等价于在二值图中将其像素值设为1) 这一步骤原本也可以由一条语句完成,如:
now_image = now_image.convert("1") # "1"表示二值图
但是,这样直接得到的二值图不一定满足我们的要求。本菜鸡尝试过,得到的验证码的线会比较细,不利于我们进一步的操作,所以我们要用一个稍微复杂一点的方法。
根据二值化的原理,我们很容易可以知道将图片二值化的一种简单方法,即设置一个阈值thresold,当某个像素点的灰度值小于它时,将这个像素点的像素值设为0;否则,将其像素值设为1,然后根据这个方法,重新描点画出二值图。
def get_bin_table(thresold = 170): table = [] for i in range(256): if i < thresold: table.append(0) else: table.append(1) return table # 得到的一个list,其0~thresold-1项为0,thresold~255项为1 table = get_bin_table() # thresold的值可以自行调节 bin_image = now_image.point(table, '1') # 用重新描点画图的方式得到二值图
二值化的成果图: 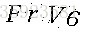
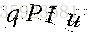
3、去噪
我们可以看到,得到的二值图中仍有一些黑点残留,这些黑点会影响到我们的识别,那么,我们该如何去除掉这些黑点呢?
最简单的方法,即是我们可以在去除干扰线的步骤,调节要去除的像素点的RGB值的范围,这样能减少黑点数量,但也很容易导致验证码的部分被去除。
那对于已经二值化的图片,要如何去除这些干扰点呢?这里我们需要进行一个图像去噪的步骤,来将这些噪点去除。
常见的图像去噪方法有中值滤波、均值滤波等,但本菜鸡看了很多博客之后,决定用一种比较简单粗暴的方法。
通过观察得到的二值图,我们可以发现,图中的噪点,主要是一些孤立的“黑点”。即在某一个黑点形成的九宫格中,黑色像素点的数量较少,或者说只有它自身一个黑点,我们可以直接将满足这个特点的黑点给去除掉(像素值设为1)即可。
1 # 判断某个点是否超出了图的边界 2 def isvalid(image, x, y): 3 if x<0 or x>=image.size[0] or y<0 or y>=image.size[1]: 4 return False 5 return True 6 7 # 判断某个点是否为噪点,after_table_b用于描点画图,可以改变level以调节去噪深度 8 def clear_noise_pixel_binary(image, x, y, after_table_b, level): 9 now = image.getpixel((x,y)) 10 flag = 0 11 for i in range(-1,2): 12 for j in range(-1,2): 13 if i==0 and j==0: 14 continue 15 if isvalid(image, x+i, y+j): 16 if image.getpixel((x+i,y+j))==0: 17 flag+=1 # 计算该点周围黑色点的数量 18 if now==0 and flag<level: 19 after_table_b[y][x] = 1 # 去除操作,若该点为黑点,且周围黑点的数量小于level,则将该点变为白点 20 elif now==1 and flag>=4: 21 after_table_b[y][x] = 0 # 补充操作,若该点为白点,且周围黑点的数量大于等于4,则将该点变为黑点 22 else: 23 after_table_b[y][x] = now
我们可再设一个clear_noise()函数对一整张图片进行去噪,至此,图片预处理的部分就结束了。以下是整个预处理的步骤代码(代码中出现的xxpath和xxroad是储存路径的变量):
1 now_image = Image.open(read_path + now_road) # 打开一张图片 2 clear_noise(now_image,2) # 第一步,去除干扰线 3 now_image.save(first_path + now_road) # 可省略,存储清除了干扰线的图片 4 now_image = now_image.convert("L") # "L"表示灰度图 5 now_image.save(gray_path + now_road) # 可省略,存储灰度图 6 bin_image = now_image.point(table, '1') # 用重新描点画图的方式得到二值图 7 bin_image.save(binary_path + now_road) # 可省略,存储二值图 8 clear_noise(bin_image,1) # 最后一步,对二值图去噪 9 bin_image.resize((64, 24),Image.ANTIALIAS).save(need_path + now_road) # 改变图片的分辨率后,将最终的图片存储下来
最终得到的完成图如下: 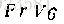
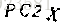
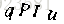
可以看到,经过去噪后的图片基本去除了干扰点,但也导致验证码的一些部分也被去除,但对验证码识别并无太大影响。我们可以通过改变一些参数的值(例如:识别为干扰线的RGB范围、二值化的阈值、去噪的深度,去噪的次数)来得到更理想的图。然而本菜鸡这样处理之后的500张验证码训练集,已经能够得到较好的识别效果了。
需要注意的是,最后改变图片分辨率的操作并不是必须的,改变图片分辨率会导致识别的精度有所下降。但是改变了分辨率之后,图片的分割和特征值的提取会更方便一点,所以本菜鸡还是将图片的分辨率改了。
还需要注意的是,灰度化、二值化、去噪等操作的顺序并不是固定的,如果能得到更好的效果,完全可以直接对RGB图和灰度图直接进行去噪。同时,不建议先改变分辨率再对图片进行处理,因为改变了分辨率后,每个点的像素值也会发生改变。
4、分割
我们可以看到,每一张验证码都有四个字符,通过观察收集的训练集,我们可以知道字符的类型(本菜鸡收集的验证码里面的字符都是字母或数字,而且支持将大写字母识别为小写字母)
根据字符的类型,我们先新建几个文件夹,用于存储分割后的验证码图片。
1 divide_path = now_path + "divide/" # 分割后的验证码路径 2 # 在路径下新建文件夹,名字为a-z,0-9,用于存储分割后的验证码 3 for i in range(26): 4 if not os.path.exists(divide_path + chr(i+97)): 5 os.mkdir(divide_path + chr(i+97)) 6 for j in range(10): 7 char_vectors[str(j)] = [] 8 if not os.path.exists(divide_path + str(j)): 9 os.mkdir(divide_path + str(j))
然后根据之前保存下来的验证码训练集的答案,对处理好的验证码图片进行分割并保存。
答案的存储方式如下(节选): 
对于复杂的验证码图片,它的字符可能有斜体,字符之间可能出现连笔,字符的位置和大小可能也不固定,这就加大了分割的难度。所以,要识别复杂的验证码图片,好的分割算法是至关重要的。但本菜鸡收集到的验证码都较为简明规范,所以对图片直接进行均分,代码如下:
1 fp = open(read_path + "/result.txt") # 验证码训练集的答案路径 2 divide_name = [] 3 for x in fp.readlines(): 4 divide_name.append(str(x).strip()) 5 fp.close() 6 for i in range(1,len(os.listdir(need_path))): 7 now_road = "/0" 8 if i<100: 9 now_road += "0" 10 if i<10: 11 now_road += "0" 12 read_road = now_road + str(i) + ".png" 13 now_image = Image.open(need_path + read_road) # 读取处理后的验证码 14 for j in range(4):# 每张验证码有四个字符 15 child_image = now_image.crop((j*16,0,(j+1)*16,24)) # 分割验证码图片(均分) 16 write_road = now_road + str(i) + "-" + str(j) + ".png" 17 child_image.save(divide_path + divide_name[i-1][j] + "/" + write_road) # 存储分割后的图片
下图是分割好的训练集(节选): 
(事实上做到这一步就已经可以用python的tesseract库直接对图片进行识别了,但本菜鸡用过之后发现效果并不是很好)
三、选取特征值
接下来提到的验证码图片都是已经预处理并分割完成的。
首先我们要明白,并不能直接将图像与其对应的字符相匹配,而是将图像与图像的特征值相匹配,再将图像的特征值与相应的字符相匹配。所以要对图像里的文字进行识别,首先要提取出该图像中的特征值。每个图像可以有多个特征值,我们将图像的所有特征值组成一条向量,将图像与它的特征向量相匹配。
但是,根据选取规则的不同,一个图像可以有不同的特征向量。例如:选取图像不同颜色点的个数组成特征向量、选取图像不同颜色像素点占总像素点的比例组成特征向量等。因此,我们需要先确定一个特征向量的选取规则,之后可根据识别效果对选取规则进行修改
在确定了选取规则后,我们便可以提取每张验证码的特征向量了。在此之后,我们可以再做一步工作,即将训练集中每张验证码的特征向量按照其对应字符存储下来,例如:‘a’:(1,1,1),(2,2,2),(3,3,3),表明特征向量为(1,1,1)、(2,2,2)、(3,3,3)的图像识别为a。
在选取特征向量的问题上,本菜鸡一开始用了最粗暴的方法,即将每张图片的所有点的像素值组成该图的特征向量。
1 # 得到图像中所有点的像素 2 def get_pixel(image): 3 fp = open("test.txt","w") 4 for i in range(0,image.size[0]): 5 for j in range(0,image.size[1]): 6 fp.write(str(image.getpixel((i,j)))+" ") 7 fp.write("\n") 8 fp.close()
这样子得到的特征向量虽然能更准确地匹配一张图,但是会导致后面的识别步骤效率较低,于是后面尝试另一种选取方式:将每张验证码再分割成4*4的小图,将这些小图中黑色像素点所占比例和整张图中黑色像素点所占比例共十七个特征值组成一个特征向量
1 # 根据选取规则得到图像特征值 2 def get_all_eigen_b(image): 3 res = [0 for i in range(17)] 4 sum_pixel = 0 5 for i in range(4): 6 for j in range(4): 7 now_image = image.crop((j*4,i*6,(j+1)*4,(i+1)*6)) # 分割图像 8 now_pixel = 0 9 for x in range(now_image.size[0]): 10 for y in range(now_image.size[1]): 11 if now_image.getpixel((x,y))==0: 12 now_pixel += 1 # 计算黑色点数量 13 res[i*4+j] = now_pixel/24 # 计算黑色点比例 14 sum_pixel += now_pixel 15 res[16] = sum_pixel/384 16 return res
然后我们将特征值保存下来,以便之后的识别。
1 def save_vectors(select): 2 for i in range(26): 3 char_vectors[chr(i+97)] = [] 4 for j in range(10): 5 char_vectors[str(j)] = [] # 存放不同字符及其对应的特征向量 6 for key in char_vectors: 7 for x in os.listdir(divide_path + key): 8 now_png = str(x) 9 if now_png[-4:]==".png": 10 image = Image.open(divide_path + key + "/" + now_png, "r") # 打开一张图片 11 if select=="2": 12 char_vectors[key].append(get_all_pixel(image)) # 像素值作为特征值 13 else: 14 char_vectors[key].append(get_all_eigen_b(image)) # 黑点比例作为特征值 15 fp = open(divide_path + key + "/vectors.txt", "w") # 保存 16 for i in range(len(char_vectors[key])): 17 for j in range(len(char_vectors[key][i])): 18 fp.write(str(char_vectors[key][i][j])) 19 fp.write(" ") 20 fp.write("\n") 21 fp.close()
像素值作为特征值(节选): 
黑点比例作为特征值(节选):

四、简单的识别
按常规而言,完成特征向量的提取,我们应该要用这些特征向量,训练出一个模型。但事实上,得到了这些特征向量之后,我们就已经能够对验证码进行简单的识别了。
对于一张新获得的验证码,我们需要对它进行与处理训练集相同的处理操作(灰度化、二值化、去噪、分割等),并用相同的规则得到它的特征向量(记为V)。之后我们只需要遍历训练集,找到与V最“接近”的向量,并得到该向量所对应的字符。
那么,如何定义这个“接近”呢?我们认为两个向量接近,便是认为它们的夹角较小(小于90°),即它们夹角的余弦值较大。所以,我们只需要找出训练集特征向量中与V的夹角余弦值最大的向量。(本菜鸡是通过看一篇博客得到的启发,在此鸣谢:http://www.cnblogs.com/TTyb/p/6144740.html)
求两个向量夹角余弦值的公式如下(图片来自百度百科): 
代码如下(我这里没有用numpy库,用numpy库应该能大大减少代码量):
# 求向量点积 def add_vectors(a,b): res = 0 for i in range(len(a)): res += float(a[i])*float(b[i]) return res # 求向量的模 def module_vectors(a): return math.sqrt(sum([float(x)**2 for x in a])) # 求向量夹角余弦值 def get_cos(a,b): add_a, add_b = module_vectors(a),module_vectors(b) if add_a!=0 and add_b!=0: return add_vectors(a,b)/(add_a*add_b) return 0
之后便可以对验证码进行简单的识别了(核心部分代码如下)
1 # all_vectors是前文所述的向量V,learn_vectors是训练集的特征向量 2 for k in range(len(all_vectors)): 3 res = 0 4 res_key = "Null" 5 for key in learn_vectors: 6 for i in range(len(learn_vectors[key])): 7 now = get_cos(all_vectors[k],learn_vectors[key][i]) # 计算cos值 8 if now>res: 9 res = now # 找到最大值 10 res_key = str(key) 11 print(res_key + ": " + str(res)) 12 res_str += str(res_key) # res_str为识别结果
我们可以用收集到的200张测试验证码,用两种不同的特征值选取方式,进行测试,测试的结果如下:
用黑色点比例作为特征值: 用像素值作为特征值: 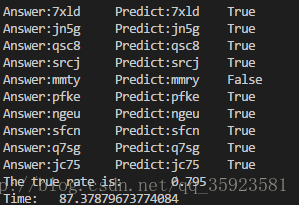
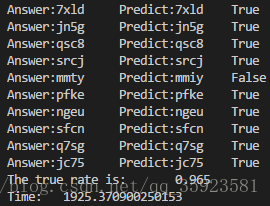
可以看到,这种粗暴的方法虽然也能够得到较为准确的结果,但效率十分低下。如果改变了特征值的选取规则,虽然提高了效率,却降低了准确率(因为每一次识别都要遍历500张验证码训练集和2000组特征向量训练集,所以效率自然不高)。这种方法对训练集较少、每一组特征向量的特征值数量较少的情况能有较高的效率,但减少训练集数量和减少特征值数量又不可避免地会降低正确率,所以这种方法虽然简单粗暴,但并不可取。
五、模型训练
得知暴力并不能得到理想的结果后,本菜鸡还是老老实实地决定用工具训练模型。
接下来的部分涉及到SVM算法,由于它的原理较为复杂,本菜鸡并不能很好地掌握并解释清楚,这里只大概介绍一下怎么使用一个强大的工具——libsvm(这是一个强大的SVM模式识别与回归的软件包,安装过程详见https://baijiahao.baidu.com/s?id=1580049402237436090&wfr=spider&for=pc)。
首先,libsvm用到的训练数据格式必须是这样的:
y1 1:x11 2:x12 3:x13 4:x14 …… n:x1n y2 1:x21 2:x22 3:x23 4:x24 …… n:x2n …… ym 1:xm1 2:xm2 3:xm3 4:xm4 …… n:xmn (其中y1~ym需为int或double)(y表示结果,x表示特征值)
我们将字符a-z转换成数值10-35,根据之前的训练集特征向量(先选用像素值作为特征值),得到了下面的训练数据(节选): 
接下来,我们需要对训练数据进行交叉检验,以确定模型的最佳参数。libsvm中有自带的用于交叉检验的工具,我们只需要将训练数据放到libsvm根目录下的tools文件夹里(result.txt即为训练数据文件)。 
再进入这个tools文件夹,运行grid.py,输入:
cd E:\Libsvm\libsvm-3.22\tools
python grid.py result.txt
经过一段时间后,能得到模型的最佳参数(c和g):
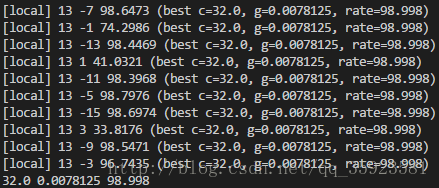
根据得到的最佳参数,我们便可以开始训练模型了:
1 # 模型的训练函数 2 def train_model(choose): 3 y,x = svm_read_problem(svm_road + "result.txt") # 读取训练数据 4 if choose=="2": 5 model = svm_train(y,x,'-c 32 -g 0.0078125 -b 1') # -c和-g是与核函数相关的参数,-b 1表示预测结果带概率 6 svm_save_model(svm_road + "svm_model.model", model) # 保存模型(特征值为像素值) 7 else: 8 model = svm_train(y,x,'-c 8.0 -g 8.0 -b 1') 9 svm_save_model(svm_road + "svm_model_b.model", model) # 保存模型(特征值为黑点比例) 10 return model
接下来,我们就可以用训练好的模型,去识别验证码了(代码节选如下)
1 res_str = "" # res_str存放预测的答案 2 y_label = [] # 验证码识别的正确答案(若是用于测试,需要读取并转化手动输入的答案,若仅是用于预测,则可初始化为[0,0,0,0]) 3 for vector in all_vectors: 4 now_x = {} 5 for i in range(1,len(vector)+1): 6 now_x[i] = float(vector[i-1]) 7 x_value.append(now_x) # 得到特征向量,格式为1:x1,2:x2…… 8 if choose=="2": 9 model = svm_load_model(model_road) # 读取模型 10 else: 11 model = svm_load_model(model_road_b) 12 p_label, p_acc, p_val = svm_predict(y_label,x_value,model,'-b 1') # p_label是预测值,p_acc是预测值与正确答案的比较,p_val是概率 13 for x in p_label: 14 if int(x)<10: 15 res_str += str(int(x)) 16 else: 17 res_str += chr(int(x)+87) # 将预测值转化为答案
(关于libsvm的使用以及其函数中各个参数的含义,可以去看看https://www.jianshu.com/p/e9cd040de6ce,或者阅读libsvm自带的README)
对得到的模型进行测试,结果如下:
用像素值作为特征值: 用黑色点比例作为特征值: 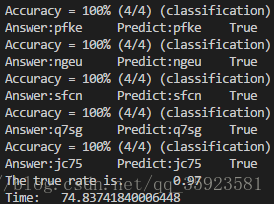
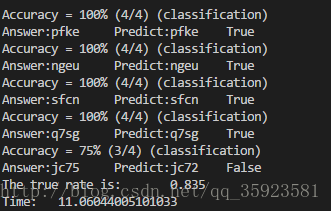
从测试效果来看,相比简单粗暴的方法,用模型不仅提高了准确率,还大大提高了效率。
最终的识别结果(对一张验证码进行识别)样例如图:

这是本菜鸡写的第一篇可以称作技术博客的东西,若是发现其中的代码有错误或者太冗杂,或是有表述上的错误,还请各位大佬多多指正。
同时,本菜鸡在此声明虽然验证码来自于本校教务系统登录网站,但只是因为那里的验证码比较好拿,本菜鸡并没有对本校教务系统做任何坏事。
本菜鸡的github地址是:https://github.com/Frostmoune/Captcha,里面有一些验证码的训练集和测试集,或许能对各位有所帮助。
知识无穷尽也。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号