
不修改破坏查询字符串的自定义分页(简翻译)
原文地址:http://www.codeproject.com/KB/aspnet/Custom_Paging_AnyDatabase.aspx
源码下载:http://www.codeproject.com/KB/aspnet/Custom_Paging_AnyDatabase/Custom_Paging.zip
简介
自定义分页一直以来并不是什么新的想法。我看过许多程序是通过存储过程或者查询字符串进行自定义分页,当然这也是最好的方式,但是,如果你已经建好了一个项目,并且你也不想更改存储过程或查询字符串。另外如果你是使用SQL Server 2000,它不支持Row_Number()函数,这你就得花大心思在自定义分页上。
背景
实现这个解决方案的逻辑非常简单。一般我们都会用DataTable或者DataSet去绑定GridView或其他数据控件。用DataTable的问题就在于它会加载所有的记录,然后在GridView上绑定特定的页。也就是说,如果你有一百万条记录,它就会花X秒去加载那一百万条记录,然后绑定一个只需要显示十条记录的简单页面。如果我们只需DataTable加载那些我们需要显示的记录,那将减少加载的时间。简单来说,DataTable加载十条记录,从2000到2010或者从20000到20010。这种方式我们将会节省大量的时间。
为实现上述,我们需要以下的逻辑:
- 根据查询字符串执行DataReader。
- 循环DataReader到我们想要开始获取记录的位置。
- 获取需要的记录。
- 将数据转换到DataTable中。
- 结束循环。
- 返回DataTable
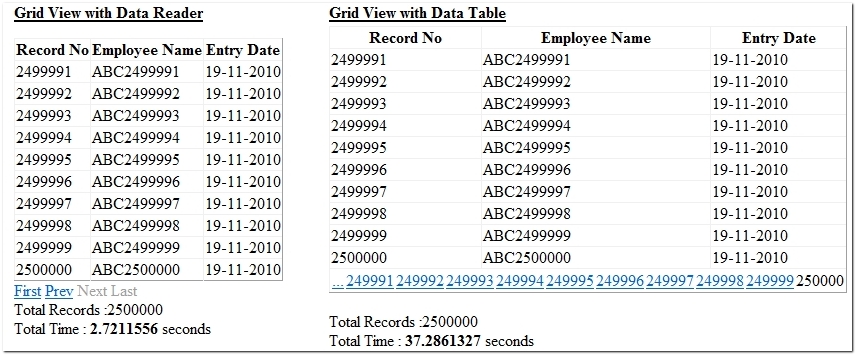
你也许会争执这和直接加载到DataTable没什么区别。但是这在我电脑(Dual Core 1.2 Ghz, 2 GB RAM) 上测试,获取250万条记录用了39秒,与此同时,DataReader使用了2.27秒。好了,我们赶快去看看代码是如何工作的。
代码使用
逻辑的核心是函数: "DataReaderToDataTable" 定义在Common.cs中,它需要参数:sQuery,iStart,iEnd.
- 这个函数执行查询字符串,返回包含了从StartRow到EndRow记录的DataTable。
- 它以DataReader执行sql查询字符串开始。
- 在没有数据处理时执行查询字符串会非常快。
- 接下来它将加载TableSchema作为schmetable(DataTable)的一行。
- 创建新的DataTable,使用循环加载schmetable每列适当的数据类型。
- 接下来循环到获取记录的起始位置,也就是iStart。
- 获取数据,直到到达iEnd,循环结束。
- 返回DataTable到调用函数。
internal static DataTable DataReaderToDataTable(string sQuery, int iStart, int iEnd)
{
DataTable schematable = null;
DataTable dt = null;
SqlCommand cmdsql;
SqlDataReader dr = null;
SqlConnection conn = null;
long icount = 0;
try
{
//Open the connection and execute the Data Reader
conn = new SqlConnection(ConnString);
conn.Open();
cmdsql = new SqlCommand(sQuery, conn);
dr = cmdsql.ExecuteReader(CommandBehavior.CloseConnection);
schematable = dr.GetSchemaTable();
dt = new DataTable();
//Get the Schema of Tables Columns and its types, and load the same into DataTable.
for (int i = 0; i <= schematable.Rows.Count - 1; i++)
{
DataRow dRow = schematable.Rows[i];
DataColumn column = new DataColumn();
column.DataType = System.Type.GetType(dRow["DataType"].ToString());
column.AllowDBNull = (dRow["AllowDBNull"].ToString() == "True" ? true : false);
column.ColumnName = dRow["ColumnName"].ToString();
column.Caption = dRow["ColumnName"].ToString();
dt.Columns.Add(column);
//More DataTable property can be added as required.
}
if (iStart == 0) iStart = 1;
if (iEnd == 0) iEnd = 1;
icount = 1;
//Loop the Reader which is executed till the Start and Variable,
//Fetch and add the rows one by one to Data Table Till the End Count is reached.
// Exit the loop and Return Datable.
while (dr.Read())
{
if (icount >= iStart && icount <= iEnd)
{
DataRow dRow = dt.NewRow();
for (int i = 0; i <= dr.FieldCount - 1; i++)
{
dRow[i] = dr.GetValue(i);
}
dt.Rows.Add(dRow);
}
else if (icount > iEnd)
{
break;
}
icount = icount + 1;
}
}
catch (SystemException ex)
{
throw ex;
}
finally
{
conn.Close();
conn.Dispose();
schematable.Dispose();
dr.Close();
dr.Dispose();
}
return dt;
}
单独使用这个函数足以作为自定义分页的备选方案。但是我在使用GridView时已经对它根深蒂固了。
欢迎提供任何改进这个代码的建议。
Have a happy coding.
第一次翻译,谢谢支持!
ps:针对部分网友的质疑,我自己也做了一次测试,测试结果跟原文作者的结果差不多,在记录不是很多的时候,差距确实不大,当记录加到25万条时,相差时间有3秒左右;当记录加到了250万条,相差时间居然有70多秒,比原文作者的差距还大,我电脑配置比较低(AMD Athlon 64X2 Dual Core Processor 4000+,1G内存)。由于实验数据库比较大,这里就不供下载,数据库名:Paging,表名:TmpData。下面提供产生实验数据的存储过程:
CREATE PROCEDURE [dbo].[CreateTmpData]
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Num INT;
SET @Num = 1;
WHILE(@Num < 2500001)
BEGIN
INSERT INTO TmpData(EmpName,[CurDate])
VALUES('TestName'+CONVERT(VARCHAR(30),@Num),GETDATE());
SET @Num = @Num + 1;
END
END
希望有兴趣的网友都可以自己测试一下,欢迎大家反馈测试结果。


