
hbase的数据模型和原理
1.hbase的数据模型介绍
1.1hbase的数据模型图
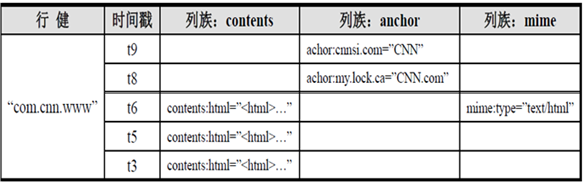
1.1.1行键row key
rowkey相当于数据库的主键,用来检索hbase中的行,Row key行键 (Row key)可以是任意字符串(最大长度 是 64KB,实际应用中长度一般为 10- 100bytes),在HBASE内部,row key保存为字节数组。存储时,数据按照Row key的字典序(byte order)排序存储。设计key时,要充分排序存储这个特性,将经 常一起读取的行存储放到一起。(位置相关性)
1.1.2列簇Columns Family
列簇 :HBASE表中的每个列,列是数据,不属于表结构。都归属于某个列族。列族是表的schema的一部 分(而列不是),必须在使用表之前定义。列名都以 列族作为前缀。例如 courses:history,courses:math都属于courses 这个列族。一个列族一个文件,相当于分表.
1.1.3cell
由{row key, columnFamily, version} 唯一确定的单元。cell中 的数据是没有类型的,全部是字节码形式存贮。
1.1.4Time Stamp
HBASE 中通过rowkey和columns确定的为一个存贮单元称为cell。每个 cell都保存 着同一份数据的多个版本。版本通过时间戳来索引。时间戳的类型是 64位 整型。时间戳可以由HBASE(在数据写入时自动 )赋值,此时时间戳是精确到毫秒 的当前系统时间。时间戳也可以由客户显式赋值。如果应用程序要避免数据版 本冲突,就必须自己生成具有唯一性的时间戳。每个 cell中,不同版本的数据按照时间倒序排序,即最新的数据排在最前面。为了避免数据存在过多版本造成的 管理 (包括存贮和索引)负担,HBASE提供 了两种数据版本回收方式。一是保存数据的最后n个版本,二是保存最近一段 时间内的版本(比如最近七天)。用户可 以针对每个列族进行设置。
2.hbase依赖zookeeper
保存Hmaster的地址和backup-master地址
hmaster:
A.管理HregionServer
B.做增删改查表的节点
C. 管理HregionServer中的表分配
1. 保存表-ROOT-的地址
hbase默认的根表,检索表。
2. HRegionServer列表
表的增删改查数据。
和hdfs交互,存取数据。
![]()
3.hbase原理
3.1 hbase体系图

3.2 写流程
1.client访问zk,根据root表获取meta表所在region的位置信息
2.client请求regionserver发出写请求,hregionserver先把操作日志写到hlog,为了数据的持久化和恢复。
3.hregionserver再将数据写到内存(memstore)
4. 当memstore的数据达到阈值(默认是64m),将数据刷到硬盘,并且删除内存和hlog对应的数据。同时将数据存储到hdfs。在hlog中做好标记点
5.当数据块到4块,hmaster将数据加载到本地,进行合并,合并后数据超过256m,会进行拆分,将拆分后的region分配给不同的regionserver
3.3 读流程
1.client访问zk,根据root表获取meta表所在region的位置信息
2.Client访问HRegion所在的HRegionServer,通过HRegionServer获取需要查找的数据;
3.Client到HRegion的中去查找数据,数据从内存和硬盘合并后返回给client
3.4 hmaster的职责
1、管理用户对Table表的增、删、改、查操作;
2、管理HRegion服务器的负载均衡,调整HRegion分布;
3、在HRegion分裂后,负责新HRegion的分配;
4、在HRegion服务器停机后,负责失效HRegion服务器上的HRegion迁移。
3.5 hregionserver的职责
1.HRegion Server主要负责响应用户I/O请求,向HDFS文件系统中读写数据,是HBASE中最核心的模块。
2.HRegion Server管理了很多table的分区,也就是region。
3.6 client职责
HBASE Client使用HBASE的RPC机制与HMaster和RegionServer进行通信
管理类操作:Client与HMaster进行RPC;
数据读写类操作:Client与HRegionServer进行RPC。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号