
Zookeeper简介及集群安装
1.Zookeeper概念简介:
Zookeeper是一个分布式协调服务;就是为用户的分布式应用程序提供协调服务,zookeeper是为别的分布式程序服务的。Zookeeper本身就是一个分布式程序(只要有半数以上节点存活,zk就能正常服务),Zookeeper所提供的服务涵盖:主从协调、服务器节点动态上下线、统一配置管理、分布式共享锁、统一名称服务,虽然说可以提供各种服务,但是zookeeper在底层其实只提供了两个功能:
管理(存储,读取)用户程序提交的数据; 并为用户程序提供数据节点监听服务;
2.zookeeper集群机制
半数机制:集群中半数以上机器存活,集群可用。
zookeeper适合装在奇数台机器上!!!
安装
机器部署
安装到3台虚拟机上
安装好JDK
上传
上传用工具。
解压
tar -zxvf zookeeper-3.4.5.tar.gz(解压)
重命名
mv zookeeper-3.4.5 zookeeper(重命名文件夹zookeeper-3.4.5为zookeeper)
修改环境变量
vi /etc/profile(修改文件)
看自己情况添加内容:
export ZOOKEEPER_HOME=/home/apps/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin
修改配置文件
cd zookeeper/conf
cp zoo_sample.cfg zoo.cfg
vi zoo.cfg
添加内容:
dataDir=/home/apps/zookeeper/data
dataLogDir=/home/apps/zookeeper/log
server.1=slave1:2888:3888 (主机名, 心跳端口、数据端口)
server.2=slave2:2888:3888
server.3=slave3:2888:3888
创建文件夹:
cd /home/apps/zookeeper/
mkdir -m 755 data
mkdir -m 755 log
在data文件夹下新建myid文件,myid的文件内容为:
cd data
vi myid
添加内容:
1
将集群下发到其他机器上
scp -r /home/apps/zookeeper hadoop@slave2:/home/apps/
scp -r /home/apps/zookeeper hadoop@slave3:/home/apps/
修改其他机器的配置文件
到slave2上:修改myid为:2
到slave3上:修改myid为:3
启动(每台机器)
zkServer.sh start
查看集群状态
jps(查看进程)
zkServer.sh status(查看集群状态,主从信息)
zookeeper结构和命令
zookeeper特性
1、Zookeeper:一个leader,多个follower组成的集群
2、全局数据一致:每个server保存一份相同的数据副本,client无论连接到哪个server,数据都是一致的
3、分布式读写,更新请求转发,由leader实施
4、更新请求顺序进行,来自同一个client的更新请求按其发送顺序依次执行
5、数据更新原子性,一次数据更新要么成功,要么失败
6、实时性,在一定时间范围内,client能读到最新数据
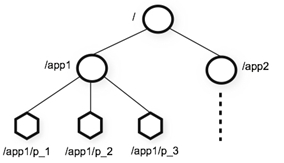
zookeeper数据结构
1、层次化的目录结构,命名符合常规文件系统规范(见下图)
2、每个节点在zookeeper中叫做znode,并且其有一个唯一的路径标识
3、节点Znode可以包含数据和子节点(但是EPHEMERAL类型的节点不能有子节点,下一页详细讲解)
4、客户端应用可以在节点上设置监视器(后续详细讲解)
数据结构的图
3.节点类型
1、Znode有两种类型:
短暂(ephemeral)(断开连接自己删除)
持久(persistent)(断开连接不删除)
2、Znode有四种形式的目录节点(默认是persistent )
PERSISTENT
PERSISTENT_SEQUENTIAL(持久序列/test0000000019 )
EPHEMERAL
EPHEMERAL_SEQUENTIAL
3、创建znode时设置顺序标识,znode名称后会附加一个值,顺序号是一个单调递增的计数器,由父节点维护
4、在分布式系统中,顺序号可以被用于为所有的事件进行全局排序,这样客户端可以通过顺序号推断事件的顺序
zookeeper命令行操作
运行 zkCli.sh –server <ip>进入命令行工具
help有命令操作指南

 浙公网安备 33010602011771号
浙公网安备 33010602011771号