数据库与ORM
一、数据库的配置
1 django默认支持sqlite,mysql, oracle,postgresql数据库。
<1> sqlite
django默认使用sqlite的数据库,默认自带sqlite的数据库驱动 。
引擎名称:django.db.backends.sqlite3
<2> mysql
引擎名称:django.db.backends.mysql
2 mysql驱动程序
- MySQLdb(mysql python)
- mysqlclient
- MySQL
- PyMySQL(纯python的mysql驱动程序)
3 在django的项目中会默认使用sqlite数据库,在settings里有如下设置:

如果我们想要更改数据库,需要修改如下:



DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'books', #你的数据库名称
'USER': 'root', #你的数据库用户名
'PASSWORD': '', #你的数据库密码
'HOST': '', #你的数据库主机,留空默认为localhost
'PORT': '3306', #你的数据库端口
}
}
注意:
NAME即数据库的名字,在mysql连接前该数据库必须已经创建,而上面的sqlite数据库下的db.sqlite3则是项目自动创建
USER和PASSWORD分别是数据库的用户名和密码。
设置完后,再启动我们的Django项目前,我们需要激活我们的mysql。
然后,启动项目,会报错:no module named MySQLdb
这是因为django默认你导入的驱动是MySQLdb,可是MySQLdb对于py3有很大问题,所以我们需要的驱动是PyMySQL
所以,我们只需要找到项目名文件下的__init__,在里面写入:
import pymysql
pymysql.install_as_MySQLdb()
问题解决!
二、ORM表模型
表(模型)的创建:
实例:我们来假定下面这些概念,字段和关系
作者模型:一个作者有姓名。
作者详细模型:把作者的详情放到详情表,包含性别,email地址和出生日期,作者详情模型和作者模型之间是一对一的关系(one-to-one)(类似于每个人和他的身份证之间的关系),在大多数情况下我们没有必要将他们拆分成两张表,这里只是引出一对一的概念。
出版商模型:出版商有名称,地址,所在城市,省,国家和网站。
书籍模型:书籍有书名和出版日期,一本书可能会有多个作者,一个作者也可以写多本书,所以作者和书籍的关系就是多对多的关联关系(many-to-many),一本书只应该由一个出版商出版,所以出版商和书籍是一对多关联关系(one-to-many),也被称作外键。
from django.db import models<br> class Publisher(models.Model): name = models.CharField(max_length=30, verbose_name="名称") address = models.CharField("地址", max_length=50) city = models.CharField('城市',max_length=60) state_province = models.CharField(max_length=30) country = models.CharField(max_length=50) website = models.URLField() class Meta: verbose_name = '出版商' verbose_name_plural = verbose_name def __str__(self): return self.name class Author(models.Model): name = models.CharField(max_length=30) def __str__(self): return self.name class AuthorDetail(models.Model): sex = models.BooleanField(max_length=1, choices=((0, '男'),(1, '女'),)) email = models.EmailField() address = models.CharField(max_length=50) birthday = models.DateField() author = models.OneToOneField(Author) class Book(models.Model): title = models.CharField(max_length=100) authors = models.ManyToManyField(Author) publisher = models.ForeignKey(Publisher) publication_date = models.DateField() price=models.DecimalField(max_digits=5,decimal_places=2,default=10) def __str__(self): return self.title
分析代码:
<1> 每个数据模型都是django.db.models.Model的子类,它的父类Model包含了所有必要的和数据库交互的方法。并提供了一个简介漂亮的定义数据库字段的语法。
<2> 每个模型相当于单个数据库表(多对多关系例外,会多生成一张关系表),每个属性也是这个表中的字段。属性名就是字段名,它的类型(例如CharField)相当于数据库的字段类型(例如varchar)。大家可以留意下其它的类型都和数据库里的什么字段对应。
<3> 模型之间的三种关系:一对一,一对多,多对多。
一对一:实质就是在主外键(author_id就是foreign key)的关系基础上,给外键加了一个UNIQUE=True的属性;
一对多:就是主外键关系;(foreign key)
多对多:(ManyToManyField) 自动创建第三张表(当然我们也可以自己创建第三张表:两个foreign key)
1、ORM之增(create,save)
from app01.models import * #create方式一: Author.objects.create(name='Alvin') #create方式二: Author.objects.create(**{"name":"alex"}) #save方式一: author=Author(name="alvin") author.save() #save方式二: author=Author() author.name="alvin" author.save()
重点来了------->那么如何创建存在一对多或多对多关系的一本书的信息呢?(如何处理外键关系的字段如一对多的publisher和多对多的authors)
#一对多(ForeignKey): #方式一: 由于绑定一对多的字段,比如publish,存到数据库中的字段名叫publish_id,所以我们可以直接给这个 # 字段设定对应值: Book.objects.create(title='php', publisher_id=2, #这里的2是指为该book对象绑定了Publisher表中id=2的行对象 publication_date='2017-7-7', price=99) #方式二: # <1> 先获取要绑定的Publisher对象: pub_obj=Publisher(name='河大出版社',address='保定',city='保定', state_province='河北',country='China',website='http://www.hbu.com') OR pub_obj=Publisher.objects.get(id=1) # <2>将 publisher_id=2 改为 publisher=pub_obj Book.objects.create(title='php', publisher=pub_obj, #添加的为出版社对象时不使用**_id了。 publication_date='2017-7-7', price=99)
#多对多(ManyToManyField()): #方式一: #取出要添加的作者对象列表,通过一本书籍的<ManyToManyDescriptor object> .add方法添加作者对象。 author1=Author.objects.get(id=1) author2=Author.objects.filter(name='alvin')[0] book=Book.objects.get(id=1) book.authors.add(author1,author2) #等同于: book.authors.add(*[author1,author2]) book.authors.remove(*[author1,author2]) #------------------- #方式二: #取出要添加的书籍对象列表,通过一个作者对象的.book_set.add(*book)添加书籍对象。 book=models.Book.objects.filter(id__gt=1) authors=models.Author.objects.filter(id=1)[0] authors.book_set.add(*book) authors.book_set.remove(*book) #------------------- #方式三:取出书籍或者作者对象,直接添加对应的id. book.authors.add(1) #book.authors.add(1,2) 可一次添加多个id,已存在的id不会重复添加 book.authors.remove(1) authors.book_set.add(1) authors.book_set.remove(1) #注意: 如果第三张表是通过models.ManyToManyField()自动创建的,那么绑定关系只有上面一种方式 # 如果第三张表是自己创建的: class Book2Author(models.Model): author=models.ForeignKey("Author") Book= models.ForeignKey("Book") # 那么就还有一种方式: author_obj=models.Author.objects.filter(id=2)[0] book_obj =models.Book.objects.filter(id=3)[0] s=models.Book2Author.objects.create(author_id=1,Book_id=2) s.save() s=models.Book2Author(author=author_obj,Book_id=1) s.save()
2、ORM之删(delete)
>>> Book.objects.filter(id=1).delete() (3, {'app01.Book_authors': 2, 'app01.Book': 1})
我们表面上删除了一条信息,实际却删除了三条,因为我们删除的这本书在Book_authors表中有两条相关信息,这种删除方式就是django默认的级联删除。
3、ROM之改(update和save)
实例:
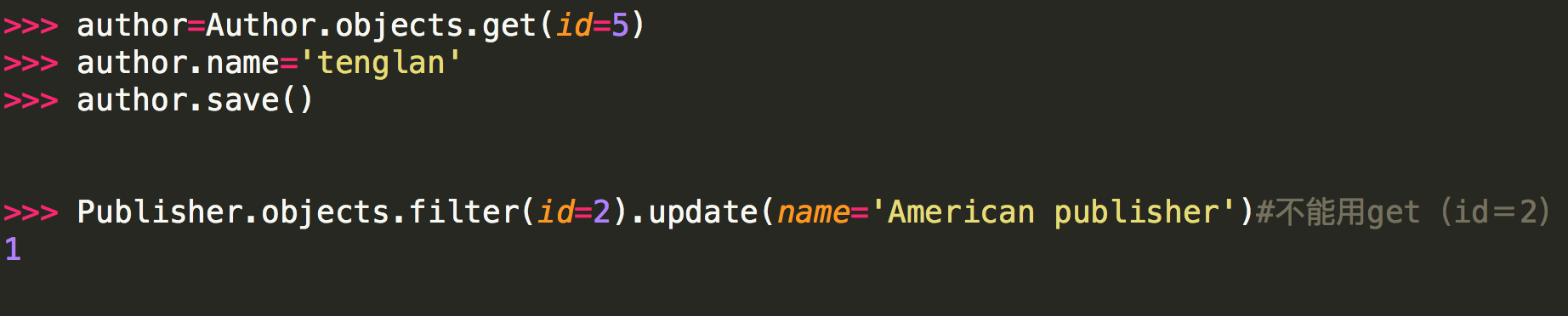
注意:
<1> 第二种方式修改不能用get的原因是:update是QuerySet对象的方法,get返回的是一个model对象,它没有update方法,而filter返回的是一个QuerySet对象(filter里面的条件可能有多个条件符合,比如name='alvin',可能有两个name='alvin'的行数据)。
<2>在“插入和更新数据”小节中,我们有提到模型的save()方法,这个方法会更新一行里的所有列。 而某些情况下,我们只需要更新行里的某几列。
#---------------- update方法直接设定对应属性---------------- models.Book.objects.filter(id=3).update(title="PHP") ##sql: ##UPDATE "app01_book" SET "title" = 'PHP' WHERE "app01_book"."id" = 3; args=('PHP', 3) #--------------- save方法会将所有属性重新设定一遍,效率低----------- obj=models.Book.objects.filter(id=3)[0] obj.title="Python" obj.save() # SELECT "app01_book"."id", "app01_book"."title", "app01_book"."price", # "app01_book"."color", "app01_book"."page_num", # "app01_book"."publisher_id" FROM "app01_book" WHERE "app01_book"."id" = 3 LIMIT 1; # # UPDATE "app01_book" SET "title" = 'Python', "price" = 3333, "color" = 'red', "page_num" = 556, # "publisher_id" = 1 WHERE "app01_book"."id" = 3;
此外,update()方法对于任何结果集(QuerySet)均有效,这意味着你可以同时更新多条记录update()方法会返回一个整型数值,表示受影响的记录条数。
注意,这里因为update返回的是一个整形,所以没法用query属性;对于每次创建一个对象,想显示对应的raw sql,需要在settings加上日志记录部分:
LOGGING = { 'version': 1, 'disable_existing_loggers': False, 'handlers': { 'console':{ 'level':'DEBUG', 'class':'logging.StreamHandler', }, }, 'loggers': { 'django.db.backends': { 'handlers': ['console'], 'propagate': True, 'level':'DEBUG', }, } }
4、ORM之查(filter和value)
4.1 查询API
# 查询相关API: # <1>filter(**kwargs): 它包含了与所给筛选条件相匹配的对象 # <2>all(): 查询所有结果 # <3>get(**kwargs): 返回与所给筛选条件相匹配的对象,返回结果有且只有一个,如果符合筛选条件的对象超过一个或者没有都会抛出错误。 #-----------下面的方法都是对查询的结果再进行处理:比如 objects.filter.values()-------- # <4>values(*field): 返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列 model的实例化对象,而是一个可迭代的字典序列 # <5>exclude(**kwargs): 它包含了与所给筛选条件不匹配的对象 # <6>order_by(*field): 对查询结果排序 # <7>reverse(): 对查询结果反向排序 # <8>distinct(): 从返回结果中剔除重复纪录 # <9>values_list(*field): 它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列 # <10>count(): 返回数据库中匹配查询(QuerySet)的对象数量。 # <11>first(): 返回第一条记录 # <12>last(): 返回最后一条记录 # <13>exists(): 如果QuerySet包含数据,就返回True,否则返回False
---------------了不起的双下划线(__)之单表条件查询---------------- # models.Tb1.objects.filter(id__lt=10, id__gt=1) # 获取id大于1 且 小于10的值 # # models.Tb1.objects.filter(id__in=[11, 22, 33]) # 获取id等于11、22、33的数据 # models.Tb1.objects.exclude(id__in=[11, 22, 33]) # not in # # models.Tb1.objects.filter(name__contains="ven") # models.Tb1.objects.filter(name__icontains="ven") # icontains大小写不敏感 # # models.Tb1.objects.filter(id__range=[1, 2]) # 范围bettwen and # # startswith,istartswith, endswith, iendswith,
4.2 QuerySet与惰性机制
所谓惰性机制:Publisher.objects.all()或者.filter()等都只是返回了一个QuerySet(查询结果集对象),它并不会马上执行sql,而是当调用QuerySet的时候才执行。
QuerySet特点:
<1> 可迭代的
<2> 可切片
#objs=models.Book.objects.all()#[obj1,obj2,ob3...] #QuerySet: 可迭代 # for obj in objs:#每一obj就是一个行对象 # print("obj:",obj) # QuerySet: 可切片 # print(objs[1]) # print(objs[1:4]) # print(objs[::-1])
QuerySet的高效使用:
<1>Django的queryset是惰性的 Django的queryset对应于数据库的若干记录(row),通过可选的查询来过滤。例如,下面的代码会得到数据库中名字为‘Dave’的所有的人:person_set = Person.objects.filter(first_name="Dave") 上面的代码并没有运行任何的数据库查询。你可以使用person_set,给它加上一些过滤条件,或者将它传给某个函数,这些操作都不会发送给数据库。这是对的,因为数据库查询是显著影响web应用性能的因素之一。 <2>要真正从数据库获得数据,你可以遍历queryset或者使用if queryset,总之你用到数据时就会执行sql.为了验证这些,需要在settings里加入 LOGGING(验证方式) obj=models.Book.objects.filter(id=3) # for i in obj: # print(i) # if obj: # print("ok") <3>queryset是具有cache的当你遍历queryset时,所有匹配的记录会从数据库获取,然后转换成Django的model。这被称为执行(evaluation).这些model会保存在queryset内置的cache中,这样如果你再次遍历这个queryset,你不需要重复运行通用的查询。 obj=models.Book.objects.filter(id=3) # for i in obj: # print(i) ## models.Book.objects.filter(id=3).update(title="GO") ## obj_new=models.Book.objects.filter(id=3) # for i in obj: # print(i) #LOGGING只会打印一次 <4>简单的使用if语句进行判断也会完全执行整个queryset并且把数据放入cache,虽然你并不需要这些数据!为了避免这个,可以用exists()方法来检查是否有数据: obj = Book.objects.filter(id=4) # exists()的检查可以避免数据放入queryset的cache。 if obj.exists(): print("hello world!") <5>当queryset非常巨大时,cache会成为问题处理成千上万的记录时,将它们一次装入内存是很浪费的。更糟糕的是,巨大的queryset可能会锁住系统进程,让你的程序濒临崩溃。要避免在遍历数据的同时产生queryset cache,可以使用iterator()方法来获取数据,处理完数据就将其丢弃。 objs = Book.objects.all().iterator() # iterator()可以一次只从数据库获取少量数据,这样可以节省内存 for obj in objs: print(obj.name) #BUT,再次遍历没有打印,因为迭代器已经在上一次遍历(next)到最后一次了,没得遍历了 for obj in objs: print(obj.name) #当然,使用iterator()方法来防止生成cache,意味着遍历同一个queryset时会重复执行查询。所以使用iterator()的时候要当心,确保你的代码在操作一个大的queryset时没有重复执行查询。 总结: queryset的cache是用于减少程序对数据库的查询,在通常的使用下会保证只有在需要的时候才会查询数据库。使用exists()和iterator()方法可以优化程序对内存的使用。不过,由于它们并不会生成queryset cache,可能会造成额外的数据库查询。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号