html 试题试卷(包含latex)下载成word - - java
html 试题试卷(包含latex)下载成word
主要目的:
- 分享将带latex的html格式的试题试卷以word的格式下载,并且加一些灵活的排版样式
- 接受群众的检阅,获得反馈
- 骗取打赏,或者github star
需求背景:
- html 混有latex公式的试题组成的试卷,下载成为word格式
- word试卷的排版,纸张大小,字体,密封线,标题,题型,誉分栏等
- html 呈现的样式和word呈现的样式一致(只能大体一致,有些样式还是没做到完全一致)
方案概要:
主要方案:提取HTML里的题文内容 >> 转换为word标签样式 >> (制造试卷模板)将转换成word样式的题文填充到模板中 >> 组建word(doc 或 docx)
- 制作freemark模板: 编辑好doc和docx的样板试卷,将其转化为xml格式,再转为ftl文件,并根据排版需求编写填充逻辑
- 编写调用freemark下载程序:根据传入条件选择doc或docx模板下载
- 解析html试题内容:用XPath分解试题内容,提取样式,将信息结构化
- 将结构化的试题内容翻译为word标签格式:将html样式翻译为对应的word里面的标签格式,让其可以填充到freemark模板中而不违背word标签的语法规范
- 综合以上步骤就可以将HTML格式的试卷下载为word格式的,文末会附源码
提前需要了解的知识:
- freemark相关语法知识
- XPath相关基础知识
- html标签样式相关知识
- word标签样式相关知识
详细实现步骤:
freemark模板制作:
1. 根据需求制作全样式的试卷样板(doc,docx 各一份)[例图:A3全样式模板]
说明:包含需求所有样式(字体,密封线,标题,题型,誉分栏等),后续在编写模板显示逻辑时可以灵活控制是否生效

2. 将doc,docx 格式的样板转换为xml
doc格式的将文件另存为 Word XML 文档(*.xml) 格式,用Notepad++等类似更具打开(NotePad++中安装XML Tools 插件,这个可以格式化xml文件,对后续的工作用处很大)[例图,折叠起来,大体结构如下]
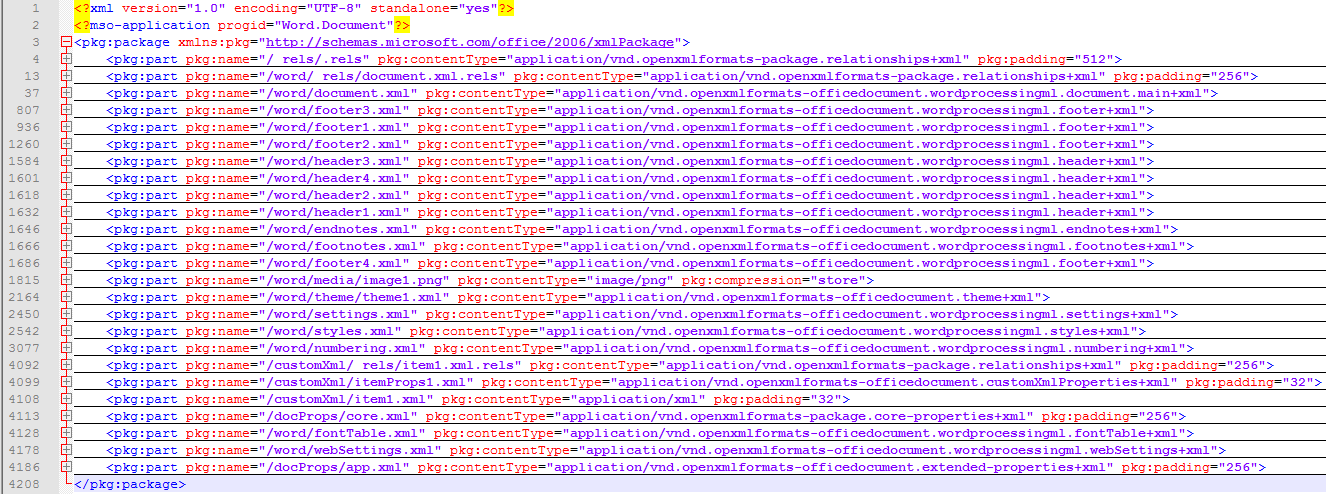
1).word xml 结构的简单介绍(纯属个人猜想,不是官方定义,如果想了解详细的结构找正规的介绍资料),下面只介绍我们用到的部分
· pkg:part:/word/_rels/document.xml.rels :用于定义header(页眉),footer(页脚),styles(样式),image(图片)等pkg:part的引用
说明:页眉,页脚可以定义多个,需要在word中展示的图片路径和引用在此定义
· pkg:part:/word/document.xml :正文部分,word中呈现的除页眉页脚以外的主要内容都在此部分(最重要的部分,后面介绍里面的格式)
· pkg:part:/word/footer.xml :页脚部分,设置试卷第几页,共几页
· pkg:part:/word/header.xml :页眉部分,设置试卷密封线
· pkg:part:/word/styles.xml :样式,设置默认字体等
· pkg:part:/word/media/image.png:图片内容(base64),docx中将图片放在/word/media文件夹下
docx 格式的样板,用解压工具解压开(不要惊讶,没写错就是解压开,docx 是一种压缩文件,它是将原本的doc的xml中的每个结构块拆开成独立文件压缩而成的)[例图:样例文件结构如下]

word文件夹下文件

docx的结构大致如将doc中每个pkg:part单独拆成文件,放在一定结构的文件夹下,最后压缩而成的,每块的功能和doc的相应pkg:part一样
docx有的[Content_Types].xml文件:定义图片类型,和其他pkg:part
正文部分:/word/document.xml 用到的标签简单介绍:
1>段落:<w:p> :段落;<w:pPr>:段落样式;<w:r>:内容部分;<w:rPr>:内容样式;<w:t>:文字内容
<w:p w:rsidR="004D42A0" w:rsidRDefault="005F1054"> <w:pPr> <w:jc w:val="center"/> <w:rPr> <w:rFonts w:eastAsia="黑体"/> <w:b/> <w:sz w:val="30"/> <w:szCs w:val="30"/> </w:rPr> </w:pPr> <w:r w:rsidRPr="00771D19"> <w:rPr> <w:rFonts w:eastAsia="黑体" w:hint="eastAsia"/> <w:b/> <w:sz w:val="30"/> <w:szCs w:val="30"/> </w:rPr> <w:t>学年</w:t> </w:r> </w:p>
2>图片:<w:pict>:图片标签;<v:shape>:图片样式;<v:imagedata>:引入图片(根据/word/_rels/document.xml.rels定义的图片id)
<w:r> <w:pict> <v:shape id="_x0000768de9d0ea6111e98c2a28843b052b2f" type="_x0000_t75" style="width:85pt;height:43pt"> <v:imagedata r:id="rId768de9d0ea6111e98c2a28843b052b2f" o:title="2"/> </v:shape> </w:pict> </w:r>
3>表格:
<w:tbl> <w:tblPr> <w:tblW w:w="0" w:type="auto"/> <w:tblLook w:val="04A0" w:firstRow="1" w:lastRow="0" w:firstColumn="1" w:lastColumn="0" w:noHBand="0" w:noVBand="1"/> </w:tblPr> <w:tblGrid> <w:gridCol w:w="222"/> <w:gridCol w:w="1376"/> </w:tblGrid> <w:tr w:rsidR="00A93926" w:rsidTr="00682485"> <w:tc> <w:tcPr> <w:tcW w:w="0" w:type="auto"/> </w:tcPr> <w:p w:rsidR="00A93926" w:rsidRDefault="00286E3F" w:rsidP="00A93926"/> </w:tc> <w:tc> <w:tcPr> <w:tcW w:w="0" w:type="auto"/> <w:vAlign w:val="center"/> </w:tcPr> <w:p w:rsidR="00A93926" w:rsidRPr="00A93926" w:rsidRDefault="00BF47F0" w:rsidP="00A93926"> <w:pPr> <w:rPr> <w:b/> </w:rPr> </w:pPr> <w:r> <w:rPr> <w:rFonts w:hint="eastAsia"/> <w:b/> </w:rPr> <w:t>一、</w:t> </w:r> <w:r> <w:rPr> <w:rFonts w:hint="eastAsia"/> <w:b/> </w:rPr> <w:t xml:space="preserve"> </w:t> </w:r> <w:r> <w:rPr> <w:rFonts w:hint="eastAsia"/> <w:b/> </w:rPr> <w:t>解答题</w:t> </w:r> </w:p> </w:tc> </w:tr> </w:tbl>
4>latex转换成的word公式:omml:
<m:oMath> <m:f> <m:fPr> <m:ctrlPr> <w:rPr> <w:sz w:val="30"/> </w:rPr> </m:ctrlPr> </m:fPr> <m:num> <m:r> <w:rPr> <w:sz w:val="30"/> </w:rPr> <m:t>a</m:t> </m:r> </m:num> <m:den> <m:r> <w:rPr> <w:sz w:val="30"/> </w:rPr> <m:t>sinA</m:t> </m:r> </m:den> </m:f> </m:oMath>
5> 纸张大小,单双栏,页眉,页脚显示设置:
<w:headerReference>: 页眉设置 w:type:可以设置单双页显示
<w:footerReference> : 页脚设置 w:type:可以设置单双页显示
<w:pgSz> : 纸张宽高设置,此处可以调整A3,A4,B4,B5等样式
<w:pgMar>: 页边距等设置
<w:cols>: 单双栏设置
<w:docGrid>: 分栏线设置
<w:p w:rsidR="005320E8" w:rsidRDefault="00286E3F" w:rsidP="00B33EF9"> <w:pPr> <w:sectPr w:rsidR="005320E8" w:rsidSect="007A55E5"> <w:headerReference w:type="even" r:id="rId9"/> <w:headerReference w:type="default" r:id="rId10"/> <w:footerReference w:type="even" r:id="rId11"/> <w:footerReference w:type="default" r:id="rId12"/> <w:pgSz w:w="23814" w:h="16840" w:orient="landscape" w:code="9"/> <w:pgMar w:top="1134" w:right="1000" w:bottom="1134" w:left="1000" w:header="851" w:footer="692" w:gutter="0"/> <w:cols w:num="2" w:sep="1" w:space="425"/> <w:docGrid w:type="lines" w:linePitch="312"/> </w:sectPr> </w:pPr> </w:p>
以上就是word试卷样板和word结构和标签的简单介绍,这写对于生成word很重要,涉及的内容也比较多,本人了解的也不多,是一个个试出来的,如有其它需求大家可以查文档或通过控制变量的方式,打开word编辑出自己想要的样式转成xml和原版xml对比找出不同的部分锁定样式设置的地方
2. 将xml样板转换为freemark的ftl模板
1).doc的xml文件直接将后缀改为.ftl,并将模板中的过多信息删除(每个后期填充的图片,段落样式保持一个),做到最精简的模板,放入项目中
2).docx的xml文件将 /word/document.xml 正文部分取出,如果页眉页脚样式也会有灵活变化也可以取出来做成模板,放入项目中

3).编写数据填充逻辑(得有一定基础的freemark语法基础)
doc模板的数据填充逻辑编写描述:
1>:图片引用编写:在/word/_rels/document.xml.rels 部分,动态引入图片链接,同时图片的base64也应该引到pkg:part 里
<pkg:part pkg:name="/word/_rels/document.xml.rels" pkg:contentType="application/vnd.openxmlformats-package.relationships+xml" pkg:padding="256"> <pkg:xmlData> <Relationships xmlns="http://schemas.openxmlformats.org/package/2006/relationships"> <Relationship Id="rId8" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/header" Target="header2.xml"/> .......... <#list relations.relationshipStr as rs> ${rs} </#list> </Relationships> </pkg:xmlData> </pkg:part>
2>:题文内容填充:在/word/document.xml部分
<w:p w:rsidR="00C93DDE" w:rsidRPr="00771D19" w:rsidRDefault="00BF47F0" w:rsidP="00C93DDE"> <w:pPr> <w:jc w:val="center"/> <w:rPr> <w:rFonts w:eastAsia="黑体"/> <w:b/> <w:sz w:val="30"/> <w:szCs w:val="30"/> </w:rPr> </w:pPr> <w:r w:rsidRPr="00771D19"> <w:rPr> <w:rFonts w:eastAsia="黑体" w:hint="eastAsia"/> <w:b/> <w:sz w:val="30"/> <w:szCs w:val="30"/> </w:rPr> <w:t>${(mainTitle.mainTitleName)!'XXXX学年度XX学校XX考试'}</w:t> </w:r> </w:p> <#list questionsList as qMap> <w:p w:rsidR="00A81065" w:rsidRDefault="00BF47F0" w:rsidP="00744A41"> <w:pPr> <w:pStyle w:val="a7"/> <w:ind w:firstLineChars="0"/> <w:textAlignment w:val="center"/> <w:spacing w:line="360" w:lineRule="auto"/> </w:pPr> ${(qMap.questionContent)!""} </w:p> </#list>
基本就是些if,else,循环list的操作就可以满足基本的需求,不再列举,只要找到正确样式和样式位置就可以完成
根据freemark模板下载word程序编写:
1. 引入freemarker jar包
<dependency> <groupId>org.freemarker</groupId> <artifactId>freemarker</artifactId> <version>2.3.26-incubating</version> </dependency>
2. 模板读取
public class PaperDownloadSeting { private static Configuration configuration = null; private static Map<String, Template> allTemplate = null; private static Logger logger= LoggerFactory.getLogger(PaperDownloadSeting.class.getName()); static{ configuration = new Configuration(Configuration.VERSION_2_3_0); configuration.setDefaultEncoding("UTF-8"); configuration.setClassForTemplateLoading(PaperDownloadSeting.class, "/freemarkmould/papermould/"); allTemplate = new HashMap<String,Template>(); try{ allTemplate.put("docmould", configuration.getTemplate("docmould.ftl")); allTemplate.put("docxDocumentMould", configuration.getTemplate("docxmould/document.ftl")); allTemplate.put("docxHeader1Mould", configuration.getTemplate("docxmould/header1.ftl")); allTemplate.put("docxHeader2Mould", configuration.getTemplate("docxmould/header2.ftl")); allTemplate.put("docxStylesMould", configuration.getTemplate("docxmould/styles.ftl")); }catch(IOException e){ e.printStackTrace(); throw new RuntimeException(e); } }
3. 数据填充,word流生成
/** *@Desc: 获取word文件流,paperMap:处理成word样式的试卷信息,out:word输出流 */ public static void getwordFileOutPutStream(Map<String, Object> paperMap,String docType, OutputStream out){ try{ Writer w = new OutputStreamWriter(out,"utf-8"); if(docType.equals("doc")) { Template t = allTemplate.get("docmould"); t.process(paperMap,w);//freemark向模板填充数据 w.close(); deleteTmpImages(paperMap.get("tempMediaPath").toString()); } if(docType.equals("docx")) { ZipOutputStream zipout = new ZipOutputStream(out); zipdocx(paperMap,zipout); } }catch(Exception e){ e.printStackTrace(); throw new RuntimeException(e); }finally { try { out.close(); deleteTmpImages(paperMap.get("tempMediaPath").toString()); } catch (Exception e2) { e2.printStackTrace(); } } } /** *@Desc: docx的试卷下载,解压静态样板,用已经填充的模板替换正文,页眉,页脚,样式等样板文件,在压缩 */ @SuppressWarnings("unchecked") public static void zipdocx(Map<String, Object> paperMap,ZipOutputStream zipout) throws IOException, TemplateException, URISyntaxException { Map<String, Object> relationsMap= JsonUtil.fromJson(JsonUtil.toJson(paperMap.get("relations")), Map.class); List<String> relationshipStr=JsonUtil.fromJson(JsonUtil.toJson(relationsMap.get("relationshipStr")), List.class); Template doct = allTemplate.get("docxDocumentMould");//正文模板 Template hea1t = allTemplate.get("docxHeader1Mould");//页眉样式 Template hea2t = allTemplate.get("docxHeader2Mould");//另一个页眉样式 Template stylt = allTemplate.get("docxStylesMould");//全局样式模板 Writer w = new OutputStreamWriter(zipout,"utf-8"); File file=makeDirs(); ZipFile zipFile = new ZipFile(file); Enumeration<? extends ZipEntry> zipEntrys = zipFile.entries(); int len = -1; byte[] buffer = new byte[1024]; while (zipEntrys.hasMoreElements()) { ZipEntry next = zipEntrys.nextElement(); zipout.putNextEntry(new ZipEntry(next.toString())); if ("word/document.xml".equals(next.toString())) { doct.process(paperMap,w);//向模板填充试卷正文内容 } else if ("word/header1.xml".equals(next.toString())) { hea1t.process(paperMap,w);//向模板填充页眉样式 } else if ("word/header2.xml".equals(next.toString())) { hea2t.process(paperMap,w);//向模板填充页眉样式 } else if ("word/styles.xml".equals(next.toString())) { stylt.process(paperMap,w);//向模板填充全局样式 } else { //其他文件复制进去 InputStream is = zipFile.getInputStream(next); while ((len = is.read(buffer)) != -1) { zipout.write(buffer, 0, len); } //向Relationships写入图片链接 if ("word/_rels/document.xml.rels".equals(next.toString())) { for(String str:relationshipStr) { zipout.write(str.getBytes()); } String endStr="</Relationships>"; zipout.write(endStr.getBytes()); } is.close(); } } //往word/media/下添加图片 String tempMediaPath=paperMap.get("tempMediaPath").toString(); File imagesFile=new File(tempMediaPath); if(tempMediaPath!=null&&tempMediaPath!=""&&imagesFile.exists()) { File[] imagesList = imagesFile.listFiles(); if(imagesList.length>0) { for(File tmpFile:imagesList) { if (tmpFile.isFile()) { zipout.putNextEntry(new ZipEntry("word/media/"+tmpFile.getName())); InputStream input=new FileInputStream(tmpFile); while ((len = input.read(buffer)) != -1) { zipout.write(buffer, 0, len); } input.close(); } tmpFile.delete(); } } } imagesFile.delete(); w.close(); zipout.close(); zipFile.close(); } /** *@Desc: 创建word图片临时文件夹,并且返回docx静态模板文件,将静态模板文件放在临时目录下(静态模板较大可以单独放在其他地方,本项目为了方便就放在resources下) */ public static File makeDirs() { String filePath=PaperDownloadSeting.class.getClassLoader().getResource("").getPath().replace("classes", "tempfile"); String fileName="docxmould.docx"; File file=new File(filePath, fileName); if(file.exists()) { if(file.length()>0) { return file; } file.delete(); } file.getParentFile().mkdirs(); try { file.createNewFile(); OutputStream out=new FileOutputStream(file); File modulFile = ResourceUtils.getFile("classpath:freemarkmould/staticmould/docxmould.docx"); InputStream in= new FileInputStream(modulFile); byte[] buffer = new byte[1024]; int bytesToRead = -1; while ((bytesToRead = in.read(buffer)) != -1) { out.write(buffer, 0, bytesToRead); } in.close(); out.flush(); out.close(); } catch (Exception e) { e.printStackTrace(); } return file; } /** *@Desc: 删除临时图片 */ public static void deleteTmpImages(String floderPath) { File imagesFloder=new File(floderPath); if(floderPath==null||floderPath.equals("")||!imagesFloder.exists()) {return;} File[] imagesList = imagesFloder.listFiles(); if(imagesList.length<1) {imagesFloder.delete();return;} for(File tmpFile:imagesList) { if (tmpFile.isFile()) {tmpFile.delete();} } imagesFloder.delete(); }
到此我们就可以将文本的简单数据填充到模板,并下载成word了,接下来我们要做的就是将html格式的试题转换为相应的word格式,填充到模板
解析html试题内容,将其结构化:
1. 引入XPath jar包
<dependency> <groupId>cn.wanghaomiao</groupId> <artifactId>JsoupXpath</artifactId> <version>2.2</version> </dependency>
2. 解析HTML试题内容
/** * @Desc: 标签节点 **/ public class Node { private String nodeName; private Integer nodeType;//1:标签节点;2:文本节点 private Map<String,String> attrMap; private String nodeText; private String nodeStr; private String childStr; private String nodeParent; private List<Node> childNodeList; public String getNodeName() { return nodeName; } public void setNodeName(String nodeName) { this.nodeName = nodeName; } public Integer getNodeType() { return nodeType; } public void setNodeType(Integer nodeType) { this.nodeType = nodeType; } public Map<String, String> getAttrMap() { return attrMap; } public void setAttrMap(Map<String, String> attrMap) { this.attrMap = attrMap; } public String getNodeText() { return nodeText; } public void setNodeText(String nodeText) { // nodeText=nodeText.replaceAll("[\n\r\t]",""); nodeText=nodeText.trim(); if(nodeText==null||nodeText.equals("")) {nodeText=null;} this.nodeText = nodeText; } public String getNodeStr() { return nodeStr; } public void setNodeStr(String nodeStr) { nodeStr=nodeStr.replaceAll("[\n\r\t]",""); this.nodeStr = nodeStr; } public String getChildStr() { return childStr; } public void setChildStr(String childStr) { this.childStr = childStr; } public String getNodeParent() { return nodeParent; } public void setNodeParent(String nodeParent) { this.nodeParent = nodeParent; } public List<Node> getChildNodeList() { return childNodeList; } public void setChildNodeList(List<Node> childNodeList) { this.childNodeList = childNodeList; } }
解析html
/** *@Author: maoyuwei *@Date: 2019/9/7 15:29 *@Desc: 提取一级标签节点 */ public static List<Node> htmlStrToNodes(String htmlStr){ htmlStr.replace("##","");//##为提取文本的分隔符,不能出现在题文中 JXDocument jxDocument=JXDocument.create(htmlStr); String bodyPath = "/body"; JXNode bodyNode=jxDocument.selNOne(bodyPath); Node node = new Node(); node.setNodeType(1); node.setNodeName(bodyNode.asElement().nodeName()); node.setChildStr(bodyNode.asElement().html()); List<Node> nodes=childStrToNodes(node,bodyNode); if(nodes==null||nodes.size()<1) { nodes=new ArrayList<Node>(); nodes.add(node); } return nodes; } /** *@Author: maoyuwei *@Date: 2019/9/7 15:29 *@Desc: 提取当前标签下的子标签节点 */ public static List<Node> childStrToNodes(Node node,JXNode jxNode){ String childPath = "/child::*"; List<JXNode> childJXNodeList=jxNode.sel(childPath); if(childJXNodeList==null||childJXNodeList.size()<1){ if(node.getChildStr()!=null||!node.getChildStr().equals("")){ node.setNodeText(node.getChildStr().replaceAll("[\n\r\t]","")); } return null; } List<Node> tempChildNodes=new ArrayList<Node>(); String currentHtmlStr=node.getChildStr(); int index=0; for(JXNode childJXNode:childJXNodeList) { String childNodeStr=childJXNode.toString(); //标记本级文本 int beginIndex=currentHtmlStr.indexOf(childNodeStr); if(beginIndex<0) {continue;} currentHtmlStr=currentHtmlStr.substring(0,beginIndex)+"##<"+index+">"+currentHtmlStr.substring(beginIndex+childNodeStr.length()); index++; Node childNode=new Node(); Element element=childJXNode.asElement(); childNode.setNodeName(element.nodeName()); childNode.setNodeStr(childJXNode.toString()); childNode.setNodeParent(node.getNodeName()); childNode.setChildStr(element.html()); childNode.setNodeType(1); //属性逐级下沉,每个子标签都带父级的属性 Map<String,String> attrMap= JsonUtil.fromJson(JsonUtil.toJson(node.getAttrMap()), Map.class); if (attrMap==null) {attrMap=new HashMap<String,String>();}
if (childNode.getNodeName()!=null&&childNode.getNodeName().equals("tr")) {attrMap=new HashMap<>();}//表格标签tr中不写入父级属性 if(element.attributes()!=null) { for(Attribute attribute: element.attributes().asList()) { if(attribute.getKey().equals("style")){ String style=attrMap.get(attribute.getKey())==null?"":attrMap.get(attribute.getKey()); attrMap.put(attribute.getKey(),style+" "+attribute.getValue()); }else { attrMap.put(attribute.getKey(),attribute.getValue()); } } } //标签所带属性写入 if(childNode.getNodeName()!=null&&"b i u B I U".contains(childNode.getNodeName())){ String style=attrMap.get("style")==null?"":attrMap.get("style"); attrMap.put("style",style+" _"+childNode.getNodeName().toLowerCase()); } childNode.setAttrMap(attrMap); childStrToNodes(childNode,childJXNode); tempChildNodes.add(childNode); } //提取取本级文本,和本级标签节点按顺序存储 String[] textList=currentHtmlStr.split("##"); List<Node> childNodes=new ArrayList<Node>(); for(int i=0;i<textList.length;i++){ String textStr=textList[i]; if(textStr==null||textStr.equals("")) {continue;} String regex="(?<=<)[0-9]+(?=>)"; Pattern pattern = Pattern.compile(regex); Matcher matcher = pattern.matcher(textStr); Integer position=null; if(matcher.find()) { String positionStr=matcher.group(); position=Integer.parseInt(positionStr.toString()); } if(position!=null&&position<tempChildNodes.size()){ childNodes.add(tempChildNodes.get(position)); } textStr=textStr.replaceAll("<[0-9]+>",""); textStr=textStr.replaceAll("[\n\r\t]",""); if(textStr==null||textStr.equals("")) {continue;} Node textNode=new Node(); textNode.setNodeType(2); textNode.setNodeText(textStr); Map<String,String> attrMap= JsonUtil.fromJson(JsonUtil.toJson(node.getAttrMap()), Map.class); textNode.setAttrMap(attrMap); textNode.setNodeParent(node.getNodeName()); childNodes.add(textNode); } node.setChildNodeList(childNodes); return childNodes; }
以上代码就可以将html的题文结构化,接下来我们将这个结构化的题文翻译成word格式
将结构化的题文翻译为word格式:
这块的代码比较多,写的也不好,就不粘了,大家可以看下我的源码看(看 com\pdl\paperdownload\wordpapermake\htmltowordhandle 下面的类就行),简单介绍一下这块的内容:
1. 将结构化的题文里的每个node 解析成word的格式,得自己总结HTML样式和word样式的对应关系
下面简单列举几个对应样式:
· 下面绿色部分为word段落样式设置位置;黄色部分为内容样式设置位置
<w:p w:rsidR="00A81065" w:rsidRDefault="00BF47F0"> <w:pPr> <w:ind w:leftChars="130" w:left="273"/> <w:textAlignment w:val="center"/> <w:spacing w:line="360" w:lineRule="auto"/> </w:pPr> <w:r w:rsidRPr="00043B54"> <w:t xml:space="preserve"> 【解析】</w:t> </w:r> <w:r> <w:rPr> <w:rFonts w:hint="eastAsia"/> <w:b/> </w:rPr> <w:t>试题分析</w:t> </w:r> </w:p>
· 居中:word段落样式
<w:jc w:val="center"/>
· 首行缩进:word段落样式
<w:ind w:firstLineChars="200" w:firstLine="480"/>
· 右对齐:word段落样式
<w:jc w:val="right"/>
· 加粗:内容样式
<w:b/>
· 斜体:内容样式
<w:i/>
· 下划线:内容样式
<w:u w:val="single"/>
· 允许内容中的空格显示设置(绿色部分为设置部分)
<w:r> <w:t xml:space="preserve"> hello pretty girl!</w:t> </w:r>
· 上下标 sub sup:内容样式
<w:vertAlign w:val="superscript"/> <w:vertAlign w:val="subscript"/>
其他格式:
· omml 公式放在<w:p>段落标签里面(关于latex转换为word公式omml的方法,可以看我的另一篇分享:https://www.cnblogs.com/maoyuwei/p/10874773.html)
· 图片部分放在<w:p>段落标签里面
textAlignment w:val="center" 为图片行内居中
style="width:85pt;height:43pt" 设置图片宽高
<v:imagedata r:id="rId768de9d0ea6111e98c2a28843b052b2f" 设置图片引用地址
注:doc的图片得将它的base64码,和引用定义填充到模板;docx的图片放到word\media文件夹下,并将引用定义填充到模板
<w:p w:rsidR="00A81065" w:rsidRDefault="00BF47F0" w:rsidP="00744A41"> <w:pPr> <w:textAlignment w:val="center"/> <w:rPr> <w:rFonts w:hint="eastAsia"/> </w:rPr> </w:pPr> <w:r> <w:pict> <v:shape id="_x0000768de9d0ea6111e98c2a28843b052b2f" type="_x0000_t75" style="width:85pt;height:43pt"> <v:imagedata r:id="rId768de9d0ea6111e98c2a28843b052b2f" o:title="2"/> </v:shape> </w:pict> </w:r> </w:p>
· 表格部分放在和<w:p>同级
w:gridCol w:w="222" 列宽设置
<w:tr> 相当于html table中的 <tr>
<w:tc> 相当于html table中的 <td>
注意:word合并单元格的方式和HTML不太一样,不好描述,多试试自己就能发现规律
<w:tbl> <w:tblPr> <w:tblW w:w="0" w:type="auto"/> <w:tblLook w:val="04A0" w:firstRow="1" w:lastRow="0" w:firstColumn="1" w:lastColumn="0" w:noHBand="0" w:noVBand="1"/> </w:tblPr> <w:tblGrid> <w:gridCol w:w="222"/> <w:gridCol w:w="1376"/> </w:tblGrid> <w:tr w:rsidR="00A93926" w:rsidTr="00682485"> <w:tc> <w:tcPr> <w:tcW w:w="0" w:type="auto"/> </w:tcPr> <w:p w:rsidR="00A93926" w:rsidRDefault="00286E3F" w:rsidP="00A93926"/> </w:tc> <w:tc> <w:tcPr> <w:tcW w:w="0" w:type="auto"/> <w:vAlign w:val="center"/> </w:tcPr> <w:p w:rsidR="00A93926" w:rsidRPr="00A93926" w:rsidRDefault="00BF47F0" w:rsidP="00A93926"> <w:pPr> <w:rPr> <w:b/> </w:rPr> </w:pPr> <w:r> <w:rPr> <w:rFonts w:hint="eastAsia"/> <w:b/> </w:rPr> <w:t>一、</w:t> </w:r> <w:r> <w:rPr> <w:rFonts w:hint="eastAsia"/> <w:b/> </w:rPr> <w:t xml:space="preserve"> </w:t> </w:r> <w:r> <w:rPr> <w:rFonts w:hint="eastAsia"/> <w:b/> </w:rPr> <w:t>解答题</w:t> </w:r> </w:p> </w:tc> </w:tr> </w:tbl>
另外要注意的html有一些特殊字符,得提前转义,不然会导致word打不开
=>   < => < > => > & => & " => " ' => ' ¢ => ¢ £ => £ ¥ => ¥ € => € § => § © => © ® => ® ™ => ™ × => × ÷ => ÷   =>     =>   Α => Α Γ => Γ Ε => Ε Η => Η Ι => Ι Λ => Λ Ν => Ν Ο => Ο Ρ => Ρ Τ => Τ Φ => Φ Ψ => Ψ α => α γ => γ ε => ε η => η ι => ι λ => λ ν => ν ο => ο ρ => ρ σ => σ υ => υ χ => χ ω => ω ϒ => ϒ • => • ′ => ′ ‾ => ‾ ℘ => ℘ ℜ => ℜ ℵ => ℵ ↑ => ↑ ↓ => ↓ ↵ => ↵ ⇑ => ⇑ ⇓ => ⇓ ∀ => ∀ ∃ => ∃ ∇ => ∇ ∉ => ∉ ∏ => ∏ − => − √ => √ ∞ => ∞ ∧ => ⊥ ∩ => ∩ ∫ => ∫ ∼ => ∼ ≈ => ≅ ≡ => ≡ ≥ => ≥ ⊃ => ⊃ ⊆ => ⊆ ⊕ => ⊕ ⊥ => ⊥ ⌈ => ⌈ ⌊ => ⌊ ◊ => ◊ ♣ => ♣ ♦ => ♦ ¡ => ¡ £ => £ ¥ => ¥ § => § © => © « => « ­ => ­ ¯ => ¯ ± => ± ³ => ³ µ => µ Β => Β Δ => Δ Ζ => Ζ Θ => Θ Κ => Κ Μ => Μ Ξ => Ξ Π => Π Σ => Σ Υ => Υ Χ => Χ Ω => Ω β => β δ => δ ζ => ζ θ => θ κ => κ μ => μ ξ => ξ π => π ς => ς τ => τ φ => φ ψ => ψ ϑ => ϑ ϖ => ϖ … => … ″ => ″ ⁄ => ⁄ ℑ => ℑ ™ => ™ ← => ← → => → ↔ => ↔ ⇐ => ⇐ ⇒ => ⇒ ⇔ => ⇔ ∂ => ∂ ∅ => ∅ ∈ => ∈ ∋ => ∋ ∑ => − ∗ => ∗ ∝ => ∝ ∠ => ∠ ∨ => ⊦ ∪ => ∪ ∴ => ∴ ≅ => ≅ ≠ => ≠ ≤ => ≤ ⊂ => ⊂ ⊄ => ⊄ ⊇ => ⊇ ⊗ => ⊗ ⋅ => ⋅ ⌉ => ⌉ ⌋ => ⌋ ♠ => ♠ ♥ => ♥ =>   ¢ => ¢ ¤ => ¤ ¦ => ¦ ¨ => ¨ ª => ª ¬ => ¬ ® => ® ° => ° ² => ² ´ => ´ · => · ø => ø á => á
根据以上规则,结合其他需要的规则,做html结构化题文的翻译,具体翻译代码太多不在这里展示
源码: https://github.com/mao-yuwei/paper_download
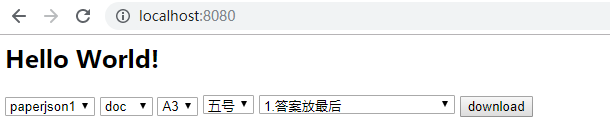
注意:spring boot 的项目,启动后访问 localhost:8080 到下载样例页:
可选择试卷,下载格式,纸张大小,字号,答案样式
试卷json数据放在:resources\paperdata
请求方法位置:com\pdl\paperdownload\main.java
总结:
整个过程就是一个 了解HTML结构,了解word结构,然后翻译,拼接出一个完整word的过程
遇到问题: 经常有格式错误或特殊字符导致word打不开的情况,这个是一大痛点,但经过不断优化这样的情况已越来越少了
会用到的latex转word公式omml的另一篇分享:https://www.cnblogs.com/maoyuwei/p/10874773.html
如果想让公式的呈现更完美可以将latex转换为mathType,可以看这篇:https://www.cnblogs.com/maoyuwei/p/15951599.html
感谢读者提供的官方资料,粘在这里:
- Office Open XML
- ECMA-376 | Office Open XML file formats
- ISO/IEC 29500-1:2016 | Office Open XML File Formats — Part 1: Fundamentals and Markup Language Reference
- ISO/IEC 29500-2:2021 | Office Open XML file formats — Part 2: Open packaging conventions
- ISO/IEC 29500-3:2015 | Office Open XML File Formats — Part 3: Markup Compatibility and Extensibility
- ISO/IEC 29500-4:2016 | Office Open XML File Formats — Part 4: Transitional Migration Features
- apache poi 库
- MathML | MDN 的 mathml 文档
有想法的,有问题的猿请走这里:mao_yuwei@163.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号