
「算法笔记」组合入门与应用
相关内容:组合入门题目选做(应用在这儿呢,可配合该文章阅读  )
)
一、基础内容
(这部分内容大家应该都会了,可以直接跳过)
1. 一些定义
加法原理:一般地,做一件事,完成它可以有 \(n\) 类方法,在第一类办法中有 \(m_1\) 种不同的方法,在第二类办法中有 \(m_2\) 种不同的方法,……,在第 \(n\) 类办法中有 \(m_n\) 种不同的方法, 那么完成这件事共有:\(N=m_1+m_2+...+m_n\) 种不同的方法。
比如在一个问题中,路径之间是平行的关系,你可以选择任意一条路径到达终点,这些路径就是满足加法原理的一个关系。
乘法原理:一般地,做一件事,完成它需要分成 \(n\) 个步骤,做完第一步有 \(m_1\) 种不同的方法,做完第二步有 \(m_2\) 种不同的方法,……,做完第 \(n\) 步有 \(m_n\) 种不同的方法。 那么,完成这件事共有:\(N=m_1\times m_2\times ...\times m_n\) 种不同的方法。
这个应该很好懂。注意区分“方法”与“步骤”。
排列:把 \(n\) 个不同元素重新排列,方案数为:\(n!\)
从 \(n\) 个不同元素中选出 \(m\) 个元素排成一列,产生的不同排列的数量为:
\(A_n^m=\frac{n!}{(n-m)!}=n\times (n-1)\times ...\times (n-m+1)\)(也可记作 \(P_n^m\))
组合:从 \(n\) 个不同元素中选出 \(m\) 个组成一个集合(不考虑顺序)的方案数。
\(C_n^m=\frac{n!}{m!(n-m)!}=\frac{n\times (n-1)\times ...\times (n-m+1)}{m\times (m-1)\times ...\times 2\times 1}\)
\(C_n^m\) 也记作 \(\binom{n}{m}\)。
2. 一些理解
怎么理解 \(C_n^m=\frac{n!}{m!(n-m)!}\) 呢?一个长度为 \(n\) 的排列,选取其中的 \(m\) 个元素。首先,我们已经知道,把 \(n\) 个不同元素重新排列,有 \(n!\) 种方案。那么,我们用总的方案数去掉重复的方案数就是答案。假设我们已经确定了一个选出的集合为 \(S\)(\(|S|=m\)),并且这个集合对应排列的前 \(m\) 个元素(顺序可以打乱)。对于序列的前 \(m\) 个位置(即集合 \(S\) 中的每个元素),有 \(m!\) 种排列方法。对于序列的后 \(n-m\) 个元素,有 \((n-m)!\) 种排列方法。两者满足乘法原理,则有 \(m!\cdot (n-m)!\) 种排列。所以如果确定了集合 \(S\),则对于这个集合 \(S\),有 \(m!\cdot (n-m)!\) 种方案。可以看成是,每 \(m!\cdot (n-m)!\) 种方案,才能确定一个集合 \(S\)。那么产生不同集合 \(S\) 的数量为 \(\frac{n!}{m!(n-m)!}\)。
既然知道了 \(C_n^m=\frac{n!}{m!(n-m)!}\),那么 \(A_n^m=\frac{n!}{(n-m)!}\) 也非常好理解了。对于 \(A_n^m\),从 \(n\) 个不同元素中选出的 \(m\) 个元素可以重新排列。选出的 \(m\) 个元素有 \(m!\) 种排列方法,那么 \(A_n^m=C_n^m\times m!=\frac{n!}{m!(n-m)!}\times m=\frac{n!}{(n-m)!}\)。
二、组合数的求法
1. 当数据范围小:利用 \(C_n^m=\frac{n!}{m!(n-m)!}\) 直接暴力计算。\(O(n)\) 的计算 \(n!\)。
2. \(n,m\leq 1000\)。用递推法(杨辉三角)。\(C_{i,j}=C_{i-1,j}+C_{i-1,j-1}\)。
c[0][0]=1; for(int i=1;i<=n;i++){ c[i][0]=1; for(int j=1;j<=i;j++) c[i][j]=(c[i-1][j]+c[i-1][j-1])%mod; }
3. \(n,m\leq 10^5,10^6\),求 \(C_n^m \bmod p\)。
分别计算分子与分母,然后相除。除以 \(m!(n-m)!\) 可以看成是乘以 \(m!(n-m)! \bmod p\) 的逆元。
预处理出 \(i!\) 和 \(\frac{1}{i!}\)(\(i! \bmod p\) 的逆元)。
预处理 \(i!\):用 \(fac_i\) 表示 \(i!\)。\(fac_0=1\),对于 \(\forall i\geq 0\),\(fac_i=fac_{i-1}\times i\)。
预处理 \(\frac{1}{i!}\):用 \(inv_i\) 表示 \(i! \pmod p\) 的逆元,则 \(inv_m=mul(fac_m,p-2,p)\)。先 \(O(log)\) 计算 \(inv_m\)。\(\frac{1}{i!}=\frac{1}{1\times 2\times ...\times i\times (i+1)}\times (i+1)=\frac{1}{(i+1)!}\times (i+1)\),那么 \(inv_i=inv_{i+1}\times (i+1)\)。
//快速幂: int mul(int x,int n,int mod){ int ans=mod!=1; for(x%=mod;n;n>>=1,x=x*x%mod) if(n&1) ans=ans*x%mod; return ans; } //对阶乘数及其逆元进行预处理: void init(){ f[0]=g[0]=1; for(int i=1;i<=n;i++) f[i]=f[i-1]*i%mod; //f(i) 表示 i! ,即 fac(i) g[n]=mul(f[n],mod-2,mod); //求逆元 for(int i=n-1;i;i--) g[i]=g[i+1]*(i+1)%mod; //g(i) 表示 1/(i!) ,即 inv(i) } //之后就可以调用: int solve(int n,int m){ return f[n]*g[m]%mod*g[n-m]%mod; }
4. 若题目中 \(n\) 非常大,甚至没法用数组存下,而 \(m\) 非常小,则可以直接计算。
\(C_n^m=\frac{n!}{m!(n-m)!}\) ,因为 \(m\) 非常小,所以 \(m!\) 可以很快被计算出来。
再考虑 \(\frac{n!}{(n-m)!}\)。\(\frac{n!}{(n-m)!}=\frac{n\times (n-1)\times ...\times (n-m+1)\times (n-m)\times (n-m-1)\times ...\times 2\times 1}{(n-m)\times (n-m-1)\times ...\times 2\times 1}=n\times (n-1)\times ...\times (n-m+1)\)。只有 \(m\) 项。也可以暴力计算。
三、Catalan 数
吹一波 Dls 写的,比这里写的不知道高到哪里去了。
1. 卡特兰数的定义
给定 \(n\) 个 \(0\) 和 \(n\) 个 \(1\),它们按照某种顺序排成长度为 \(2n\) 的序列,满足任意前缀中 \(0\) 的个数都不少于 \(1\) 的个数的序列的数量为:
\(Cat_n=\frac{1}{n+1} C_{2n}^n=\frac{(2n)!}{(n+1)!n!}\)。
2. 证明
为什么 \(Cat_n=\frac{1}{n+1} C_{2n}^n\) 呢?
考虑取补集。
首先,有 \(n\) 个 \(0\),\(n\) 个 \(1\) 的序列的数量为 \(C_{2n}^n\)(\(2n\) 个位置中取 \(n\) 个位置为 \(1\))。
令 \(n\) 个 \(0\),\(n\) 个 \(1\) 随意排成一个长度为 \(2n\) 的序列,若它不满足任意前缀中 \(0\) 的个数都不少于 \(1\) 的个数,找到它的第一个不合法的位置(不合法指前缀中 \(0\) 的个数小于了 \(1\) 的个数)。显然,第一个不合法位置上的数一定是 \(1\),并且在它的前面,\(0\) 的个数与 \(1\) 的个数相等。假设有 \(i\) 个。那么这个位置(即第一个不合法的位置)后面肯定有 \(n-i\) 个 \(0\),\(n-i-1\) 个 \(1\)。考虑把前 \(2\times i+1\) 位(即不合法位置以及它前面的数)翻转(\(0\) 变为 \(1\),\(1\) 变为 \(0\))。翻转后,第一个不合法位置上的数为 \(0\),它的前面依然是 \(i\) 个 \(0\),\(i\) 个 \(1\),它的后面还是 \(n-i\) 个 \(0\),\(n-i-1\) 个 \(1\)。则翻转后,序列共有 \(n+1\) 个 \(0\),\(n-1\) 个 \(1\)。对于一个不合法的序列,它总是能够翻转得到一个有 \(n+1\) 个 \(0\),\(n-1\) 个 \(1\) 的序列。那么我们接下来要证明的就是,对于所有这样的序列,总是能够找到一个不合法的序列与它对应。
类似地,在翻转后的序列中,找到第一个不满足前缀 \(1\) 的个数大于等于前缀 \(0\) 的个数的数的位置。很容易发现,在翻转后的序列中,总是能找到这样一个不合法的位置(因为有 \(n+1\) 个 \(0\),\(n-1\) 个 \(1\))。将这第一个不合法位置以及它前面的数翻转回去,可以得到一个有 \(n\) 个 \(0\),\(n\) 个 \(1\) 的序列,并且存在前缀 \(0\) 的个数大于前缀 \(1\) 的个数。
所以,不合法序列将不合法位置翻转,可以和一个 \(n-1\) 个 \(0\),\(n+1\) 个 \(1\) 的序列一一对应。那么,求不合法序列的数量就可以转化为求有 \(n+1\) 个 \(0\),\(n-1\) 个 \(1\) 的序列的数量。有 \(n+1\) 个 \(0\),\(n-1\) 个 \(1\) 的序列的数量显然为 \(C_{2n}^{n-1}\)(\(2n\) 个位置中取 \(n-1\) 个位置为 \(1\))。
所以合法序列的答案为:\(C_{2n}^n-C_{2n}^{n-1}=\frac{(2n)!}{n!n!}-\frac{(2n)!}{(n-1)!(n+1)!}=\frac{(2n)!(n+1)}{n!(n+1)!}-\frac{(2n)!n}{n!(n+1)!}=\frac{(2n)!}{n!n!(n+1)}=\frac{1}{n+1}\times \frac{(2n)!}{n!n!}=\frac{1}{n+1} C_{2n}^n\)
四、错排
考虑一个有 \(n\) 个元素的排列,若一个排列中所有的元素都不在自己原来的位置上,那么这样的排列就称为原排列的一个错排。
\(D_n\) 表示 \(n\) 个元素的错排方案数。
错排公式:\(D_n=(n-1)\times (D_{n-1}+D_{n-2})\)(\(n\geq 2\))
如何理解?考虑序列中 \(1\) 元素的位置。\(1\) 元素能放的位置为 \(2,3,...,n\),有 \(n-1\) 种放的位置。
假设 \(1\) 放在了 \(k\) 这个位置。接下来我们要关心的是 \(k\) 要放在什么位置。有两种情况。
-
\(k\) 放在 \(1\) 的位置。相当于 \(1\) 与 \(k\) 交换了位置,对剩下的数不会产生影响(剩下的 \(n-2\) 个数依然保持一一对应关系),则剩下的 \(n-2\) 个数可以继续进行错排。所以这种情况的方案数为 \((n-1)\times D_{n-2}\)。
-
\(k\) 不放在 \(1\) 的位置。\(1\) 的位置确定了,剩下的数(除了 \(k\))依然有自己的对应关系。新增一个对应关系 \((1,k)\) 表示 \(k\) 不能放在 \(1\) 的位置。问题就转化为了求 \(n-1\) 个数的错排方案(想一想错排的定义,\(k\) 与剩下的数每个数都不能在特定的位置上,其实就是错排)。所以这种情况的错排方案数为 \((n-1)\times D_{n-1}\)。
于是可以得到 \(D_n=(n-1)\times (D_{n-1}+D_{n-2})\)(\(n\geq 2\))。
d[0]=1,d[1]=0,d[2]=1; for(int i=3;i<=1e6;i++) d[i]=(i-1)*(d[i-1]+d[i-2])%mod; //错排
五、Lucas 定理
若 \(p\) 是质数,则对于任意整数 \(1\leq m\leq n\),有:
\(C_n^m\equiv C_{n \bmod p}^{m \bmod p}\times C_{n/p}^{m/p} \pmod p\)
也就是把 \(n\) 和 \(m\) 表示成 \(p\) 进制数,对 \(p\) 进制下的每一位分别计算组合数,最后再乘起来。
#include<bits/stdc++.h> #define int long long const int N=1e5+5; int t,n,m,p; int mul(int x,int n,int mod){ int ans=mod!=1; for(x%=mod;n;n>>=1,x=x*x%mod) if(n&1) ans=ans*x%mod; return ans; } int C(int n,int m){ if(m>n) return 0; int x=1,y=1; for(int i=n-m+1;i<=n;i++) x=x*i%p; for(int i=2;i<=m;i++) y=y*i%p; return x*mul(y,p-2,p)%p; } int lucas(int n,int m){ if(!m) return 1; return C(n%p,m%p)*lucas(n/p,m/p)%p; } signed main(){ scanf("%lld",&t); while(t--){ scanf("%lld%lld%lld",&n,&m,&p); printf("%lld\n",lucas(n,m)); } return 0; }
若 \(p\) 不是质数,可以用扩展 Lucas 定理。在这里就不讲了,可以看:扩展卢卡斯详解。
#include<bits/stdc++.h> #define int long long using namespace std; const int N=1e6+5; int n,m,p,cnt,a[N],b[N]; int mul(int x,int n,int mod){ int ans=mod!=1; for(x%=mod;n;n>>=1,x=x*x%mod) if(n&1) ans=ans*x%mod; return ans; } int exgcd(int a,int b,int &x,int &y){ if(!b) return x=1,y=0,a; int d=exgcd(b,a%b,x,y); int z=x; x=y,y=z-y*(a/b); return d; } int inv(int n,int mod){ int x,y; exgcd(n,mod,x,y); return (x%mod+mod)%mod; } int fac(int n,int p,int k){ //k=p^x if(!n) return 1; int ans=1; for(int i=2;i<=k;i++) if(i%p!=0) ans=ans*i%k; ans=mul(ans,n/k,k); for(int i=2;i<=n%k;i++) if(i%p!=0) ans=ans*i%k; return ans*fac(n/p,p,k)%k; } int C(int n,int m,int p,int k){ if(n<m) return 0; int a=fac(n,p,k),b=fac(m,p,k),c=fac(n-m,p,k),cnt=0; for(int i=p;i<=n;i*=p) cnt+=n/i; for(int i=p;i<=m;i*=p) cnt-=m/i; for(int i=p;i<=n-m;i*=p) cnt-=(n-m)/i; return a*inv(b,k)%k*inv(c,k)%k*mul(p,cnt,k)%k; } int CRT(int m){ int ans=0; for(int i=1;i<=cnt;i++){ int M=m/b[i],t=inv(M,b[i]); ans=(ans+a[i]%m*M%m*t%m)%m; } return ans; } int exLucas(int n,int m,int p){ int t=p; for(int i=2;i*i<=p;i++){ int now=1; if(t%i==0){ b[++cnt]=i; while(t%i==0) t=t/i,now*=i; a[cnt]=C(n,m,i,now),b[cnt]=now; } } if(t!=1) b[++cnt]=t,a[cnt]=C(n,m,t,t); return CRT(p); } signed main(){ scanf("%lld%lld%lld",&n,&m,&p); printf("%lld\n",exLucas(n,m,p)); return 0; }
六、容斥原理
\(\left|\bigcup\limits_{i=1}^{n}A_i\right|=\sum\limits_{i=1}^n\left| A_i \right|-\sum\limits_{1\leq i\leq j\leq n}\left|A_i\cap A_j\right|+\sum\limits_{1\leq i\leq j\leq k\leq n}\left|A_i\cap A_j\cap A_k\right|-\cdots+(-1)^n\left| A_1\cap \cdots \cap A_n\right|\)
\(\left|\bigcup\limits_{i=1}^{n}A_i\right|=\sum\limits_{k=1}^n (-1)^{k+1}(\sum\limits_{1\leq i_1\leq \cdot\leq i_k\leq n}\left|A_{i_1}\cap\cdots\cap A_{i_k}\right|)\)
\(\left|\bigcup\limits_{i=1}^{n}A_i\right|=\sum\limits_{\emptyset\neq J\subseteq\{1,2,...,n\}} (-1)^{\left|J\right|-1}\left|\bigcap\limits_{j\in J}A_j\right|\)
常见应用:题中给出 \(n\) 个需要满足的条件。
使用容斥,枚举不被满足的条件集合 \(S\) 和对应的方案数,其系数为 \((-1)^{集合大小}\)。
具体地,设 \(A\) 为条件集合。式子:
\(\sum\limits_{S\in A}(-1)^{\left| S\right|}\cdot f(S中的条件不被满足)\)
七、第二类斯特林数
把 \(n\) 个不同的球放到 \(r\) 个相同的盒子里,假设没有空盒,则放球方案数记做 \(S(n,r)\) 或 \(\begin{Bmatrix}n\\r\end{Bmatrix}\),称为第二类 \(\text{Stirling}\) 数。
1. 求法
有一个显然的递推式:
\(S(n,r)=rS(n-1,r)+S(n-1,r-1),n\geq r\geq 1\)
即讨论当前的球是放入以前的盒子还是放入一个新盒子里。如果要放入以前的盒子,那么把这个球放入任意一个盒子,这个盒子就相当于与其他的盒子不同,所以还要乘以 \(r\)。
同样有通项:
\(\begin{Bmatrix}n\\k\end{Bmatrix}=\dfrac{1}{k!}\displaystyle\sum\limits_{i=0}^k (-1)^i \dbinom{k}{i} (k-i)^n\)
注意到“盒子非空”可以作为容斥的一个条件,\(k\) 个盒子就对应 \(k\) 个条件。枚举空盒的个数 \(i\),\(k\) 个盒子选 \(i\) 个盒子是空盒的方案数为 \(C_k^i\)。确定了有 \(i\) 盒子是空盒,那么剩下 \(k-i\) 个盒子是可以放球的,则每个球都有 \(k-i\) 个选择方式(可以放到 \(k-i\) 个盒子中的任意一个里),所以要乘上 \((k-i)^n\)。由于盒子是相同的最后要除以 \(k!\)。
2. 性质
第二类 \(\text{Stirling}\) 数的性质:
\(x^n=\displaystyle\sum\limits_{k=0}^n\begin{Bmatrix}n\\k\end{Bmatrix} x^{\underline k}\)
其中 \(x^{\underline k}\) 表示 \(x\) 的 \(k\) 次下降幂,\(x^{\underline k}=\frac{x!}{(x-k)!}\)。
怎么理解呢?\(x^n\) 即 \(n\) 个球放入 \(x\) 个不相同的盒子的方案数(所以也可以有空盒)。枚举非空盒子的个数 \(k\),\(x\) 个盒子中选 \(k\) 个盒子是非空的,方案数为 \(C_x^k\)。乘上 \(n\) 个不同的球放到 \(k\) 个相同的盒子里的方案数 \(S(n,k)\)。除此之外,因为盒子是区分的,所以还要乘以 \(k!\)。于是可以得到 \(x^n=\sum\limits_{k=0}^n S(n,k) \cdot C_x^k \cdot k!\)。
又因为 \(x^{\underline k}=\frac{x!}{(x-k)!}\),于是就可以得到上面那个式子。
其实这个是可以 推出来 的。
补充:有三种说法, \(k\) 的上界分别是 \(n,x,\min(n,x)\)。因为 \(k\geq x\) 或 \(k\geq n\) 的时候对答案的贡献为 \(0\),所以三种都行。
关于下降幂的一个性质:
\(\displaystyle\binom{n}{i} i^{\underline j}=\binom{n-j}{i-j} n^{\underline j}\)
直接展开就行了。
八、图的计数
以下 \(n\) 均表示节点个数。
01 带编号无向图
求:带编号无向图的个数。(带编号就是说,点与点之间是区分的)
图与图之间不同,当且仅当它们之间有边不同。
考虑每一条边是否选。
因为有 \(n\) 个节点,所以无向边的数量为 \(\tbinom{n}{2}\)。每条边可以选或不选,那么就有 \(2^{\tbinom{n}{2}}\) 种方案。
则 \(n\) 个节点的带编号无向图的数量为 \(2^{\tbinom{n}{2}}\)。
02 带编号无向连通图
令 \(g(n)\) 表示 \(n\) 个点的无向图个数(由上可知 \(g(n)=2^{\tbinom n 2}\)),\(f(n)\) 表示 \(n\) 个点的无向连通图个数。
枚举普通无向图中 \(1\) 号点所在连通块的大小。尝试用 \(f\) 来表示 \(g\)。
具体来说,我们从 \(1\) 到 \(n\) 枚举 \(1\) 号点所在连通块的大小 \(i\)。目前只确定了这个连通块中有 \(1\) 号点, 那么剩下的 \(i-1\) 个点要从剩下的 \(n-1\) 个点中选(从剩下的 \(n-1\) 个点中选与 \(1\) 号点在同一个连通块的 \(i-1\) 个点),方案数为 \(\dbinom{n-1}{i-1}\)。点集已经确定,\(i\) 个点的连通块的构成方式有 \(f_i\) 种。除此之外,剩下的点没有任何限制,所以选择连通块以外的点的构成方式有 \(g(n-i)\) 种。则:
\(g(n)=\displaystyle\sum\limits_{i=1}^n \binom{n-1}{i-1} \cdot f(i) \cdot g(n-i)\)
于是我们可以根据这个式子算出 \(f(n)\),即:
\(f(n)=\displaystyle g(n)-\sum\limits_{i=1}^{n-1} \binom{n-1}{i-1} \cdot f(i) \cdot g(n-i)\)
03 带编号偶度点图
构造方法是,对于前 \(n-1\) 个点任意连边,第 \(n\) 个点向所有奇度点连边(可以证明奇度点一定有偶数个)。
所以答案为 \(2^{\tbinom{n-1}{2}}\)。
04 带编号偶度连通图
与带编号无向连通图的计算方法类似。
令 \(g(n)\) 表示 \(n\) 个点的偶度点图个数(由上可知 \(2^{\tbinom{n-1}{2}}\)),\(f(n)\) 表示 \(n\) 个点的偶度点连通图个数。
枚举偶度点图中 \(1\) 号点所在连通块的大小。
\(\displaystyle g(n)=\sum\limits_{i=1}^n \binom{n-1}{i-1} \cdot f(i) \cdot g(n-i)\)
\(\displaystyle f(n)=g(n)-\sum\limits_{i=1}^{n-1} \binom{n-1}{i-1} \cdot f(i) \cdot g(n-i)\)
九、无根树 / Prufer 序列
01 无根树转 Prufer 序列
每次选择一个编号最小的叶结点(度数为 \(1\))并删掉它,然后在序列中记录下它连接到的那个结点。重复 \(n-2\) 次后就只剩下两个结点,算法结束。
-
Prufer 序列的长度为 \(n-2\)
-
每个点在 Prufer 序列中出现的次数为其度数 \(-1\)
02 Prufer 序列转无根树
每次选择一个度数为 \(1\) 的最小的编号节点,与当前枚举到的 Prufer 序列的点之间连上一条边,然后同时将两个点的度数 \(-1\)。最后在剩下的两个度为 \(1\) 的点间连一条边。
注意到,点数为 \(n\) 的无根树与长度为 \(n-2\) 的 Prufer 序列一一对应。
03 完全图的生成树数量
注意到实际上要求的就是长度为 \(n-2\),值域为 \(1\sim n\) 的 Prufer 序列的数量,于是方案数即为 \(n^{n-2}\)。
04 给定 n 个节点的度数,求无根树的个数
已知每个节点的度数,也就是说每个元素在 Prufer 序列中出现的次数是确定的(即 \(i\) 在数列中恰好出现 \(d_i-1\) 次),于是问题转化成为求可重集的排列个数。答案即为:
\(\displaystyle\frac{(n-2)!}{\prod\limits_{i=1}^n (d_i-1)!}\)
05 计算完全二分图 K(n,m) 的生成树个数
注意到生成树的 Prufer 序列中一定有 \(n-1\) 个右侧的点,\(m-1\) 个左侧的点,于是答案即为 \(n^{m-1} \cdot m^{n-1}\)。


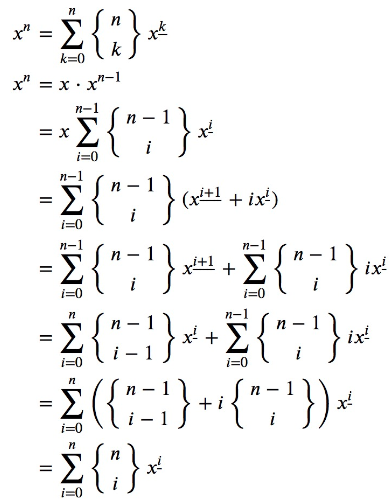{kind=link}