
HBase存储原理剖析笔记
慕课网《HBase 存储原理剖析》学习总结
说明:本文部分内容来自https://www.imooc.com/article/details/id/38969
学习视频:https://www.imooc.com/learn/996
视频案例演示源码:https://github.com/wind-free/springboot-HBaseDemo1.git
作者:喵手空空
链接:https://www.imooc.com/article/details/id/38969
来源:慕课网
作者:喵手空空
链接:https://www.imooc.com/article/details/id/38969
来源:慕课网
作者:喵手空空
链接:https://www.imooc.com/article/details/id/38969
来源:慕课网
作者:喵手空空
链接:https://www.imooc.com/article/details/id/38969
来源:慕课网
一、HBase的存储模式
1.行式存储与列式存储介绍
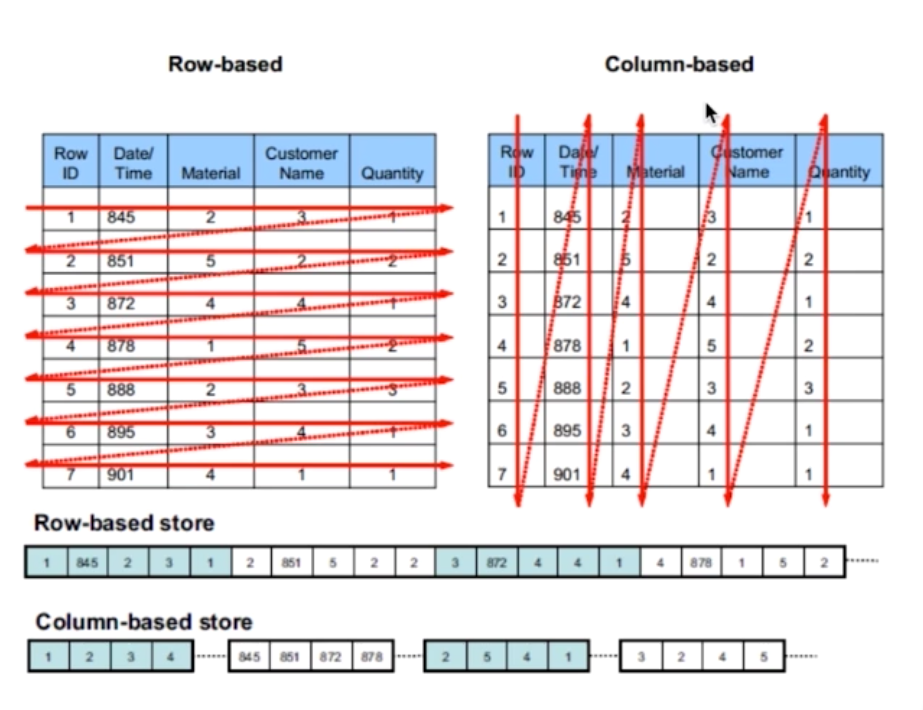
列簇式存储:概念
- 列簇(多个数据列的组合),HBase表中的每个列都归属于某个列簇
- 列簇是表的schame的一部分,但是列并不是
- 创建表时,需要给出列簇的名称,不需要给出列的名称
- 列名都是以列簇作为前缀
- 访问控制磁盘和内存的使用统计都是在列簇层面进行
- HBase准确的说是列簇数据库,而不是列数据库
- 列簇数据库将列组织为列簇,每列都必须是某个列簇的一部分
- 访问数据的单元也是列
作者:喵手空空
链接:https://www.imooc.com/article/details/id/38969
来源:慕课网
2.行式存储与列式存储各自的特点
(1)行式存储
维护大量的索引;
存储成本高
不能够做到线性扩展
随机读取效率非常高
对事务的支持非常好
(2)列式存储
根据同一列数据的相似性原理,利于对数据进行压缩
存储成本低
由于每列数据分开存储,可以并行查找多列的数据
3.行式存储与列式存储场景
(1)行式存储
表与表之间有关联关系,数据量不大(小于千万量级)
强事务关联的特性
(2)列式存储
对于单列或者相对比较少的列获取频率较高
针对多列查询,使用并行处理的查询
利于数据压缩和线性扩展的存储
事务使用率不高,读取的场景频率不高,同时数据量非常大
随机更新某一行的频率不高
4.HBase的列族式存储
(1)列族式存储概念
列簇(多个数据列的组合),HBase表中的每个列都归属于某个列簇
列簇是表的schame的一部分,但是列并不是
创建表时,需要给出列簇的名称,不需要给出列的名称
列名都是以列簇作为前缀
访问控制磁盘和内存的使用统计都是在列簇层面进行
HBase准确的说是列簇数据库,而不是列数据库
列簇数据库将列组织为列簇,每列都必须是某个列簇的一部分
访问数据的单元也是列
HBase表的组成

RowKey :HBase中用RowKey去标识唯一的一行数据,一行数据中包含多个列簇
Family:多个列簇。每一列簇包含多个列
Column:列标识符。每一列数据包含了版本和值
Timestamp:版本。可以理解为时间戳,也可以理解为一个数据的版本
Value:数据值。数据本身的值
数据存储模式

其实就是HBase表反过来看的样子
更抽象一点,其实HBase表数据就是Key-Value结构的
HBase表的组成
- Table = RowKey + Family + Column + Timestamp + Value
- RowKey :HBase中用RowKey去标识唯一的一行数据,一行数据中包含多个列簇
- Family:多个列簇。每一列簇包含多个列
- Column:列标识符。每一列数据包含了版本和值
- Timestamp:版本。可以理解为时间戳,也可以理解为一个数据的版本
- Value:数据值。数据本身的值
作者:喵手空空
链接:https://www.imooc.com/article/details/id/38969
来源:慕课网
图解
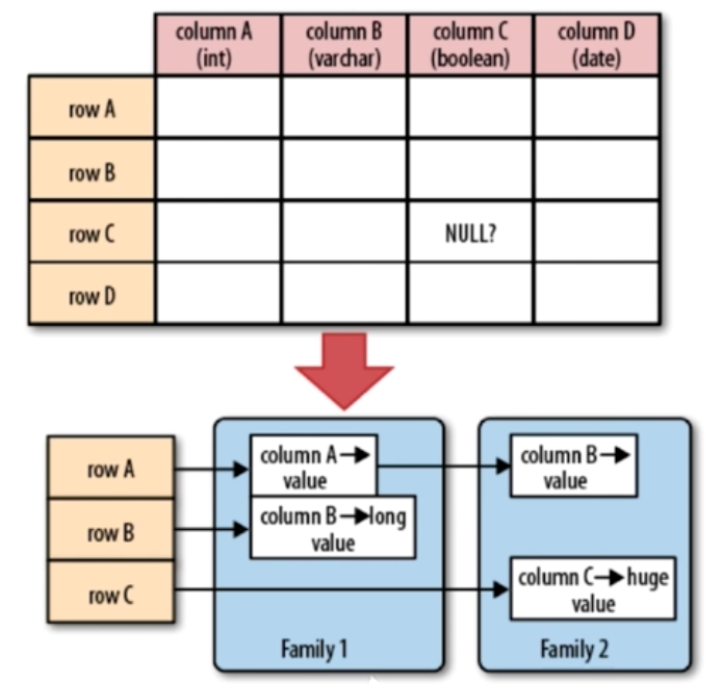
HBase表的组成
- Table = RowKey + Family + Column + Timestamp + Value
- RowKey :HBase中用RowKey去标识唯一的一行数据,一行数据中包含多个列簇
- Family:多个列簇。每一列簇包含多个列
- Column:列标识符。每一列数据包含了版本和值
- Timestamp:版本。可以理解为时间戳,也可以理解为一个数据的版本
- Value:数据值。数据本身的值
作者:喵手空空
链接:https://www.imooc.com/article/details/id/38969
来源:慕课网
(2)列数据属性
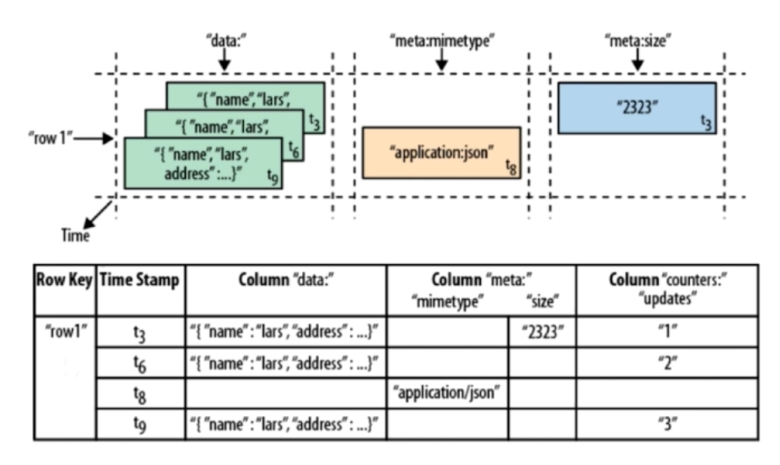
(3)数据存储原型
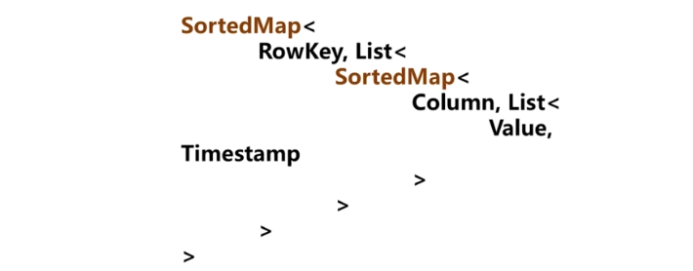
(4)存储示例

二、HBase数据表解析
1.HBase建表语句解析

关键字说明
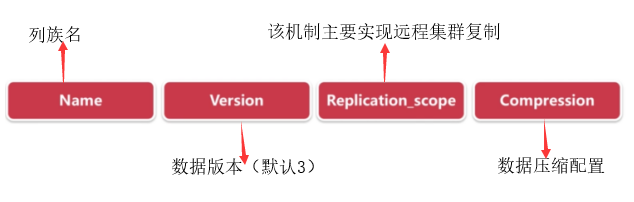
压缩算法
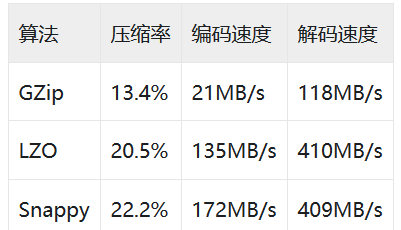
2.HBase数据存储目录解析
在hbase-site.xml文件中配置或查看存储目录的节点
<property>
<name>hbase.rootdir</name>
<value>/home/hbase_data</value>
</property>
进入到HBase系统目录
-
- temp
当对表做创建或删除操作时,将表移动到tmp目录下,然后再进行处理
临时交换的表,临时存储一些当前需要修改的数据结构
-
- WALs
预写日志,被HLog实例管理的WAL文件
可以理解为存储HBase的日志,HBase分布式数据库系统的操作日志
-
- archive
存储表的归档和快照
HBase在做分割或合并操作完成后,会将Hfile文件移动到该目录中,然后将之前的Hfile删除掉
是由Master上的定时任务定期去处理,这个目录的作用可以简单理解为去管理HBase的数据
-
- corrupt
用于存放损坏的日志文件,一般是空的
-
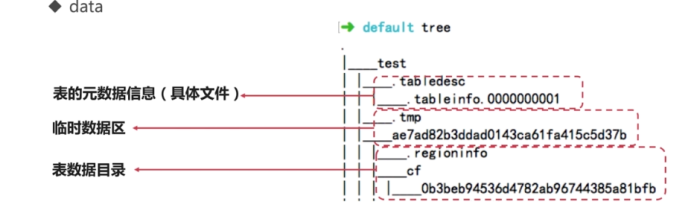
- data
HBase存储数据的核心目录
系统表和用户表数据都存储在这里
-
- hbase.id
HBase启动运行后,是集群中的唯一ID,用来标识HBase进程用的
-
- hbase.version
表明了集群的文件格式版本信息
其实就是表明了Hfile的版本信息
-
- oldWALs
备份WALs中的日志文件
data目录解析
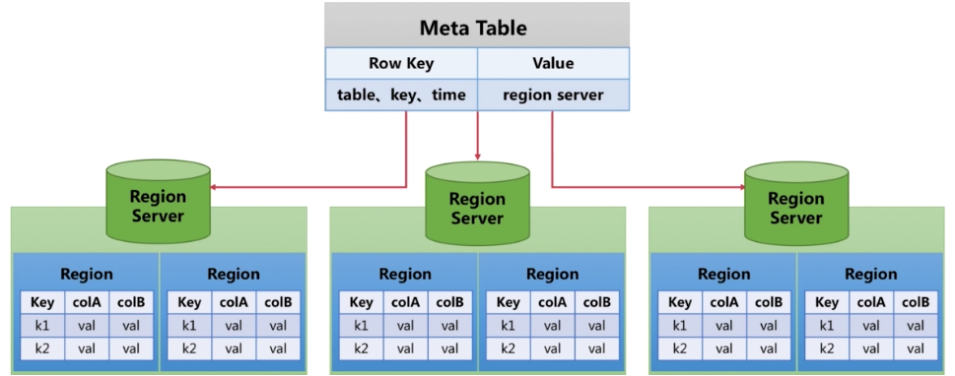
3.HBase元信息表
三、HBase存储设计
1.HBase中的LSM存储思想
(1)LSM树概念
LSM日志结构合并树,有两个或两个以上存储数据的结构组成的,每一个数据结构各自对应自己的存储介质
(2)LSM树的简易模型
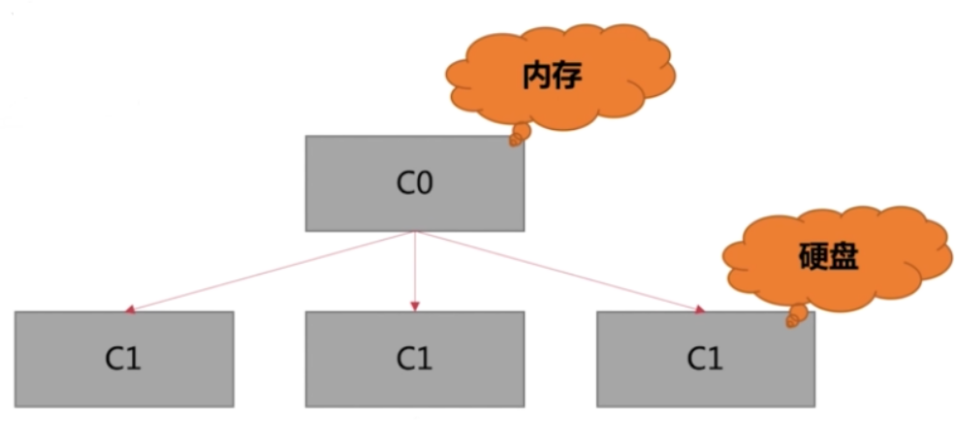
(3)LSM思想在HBase中的实现
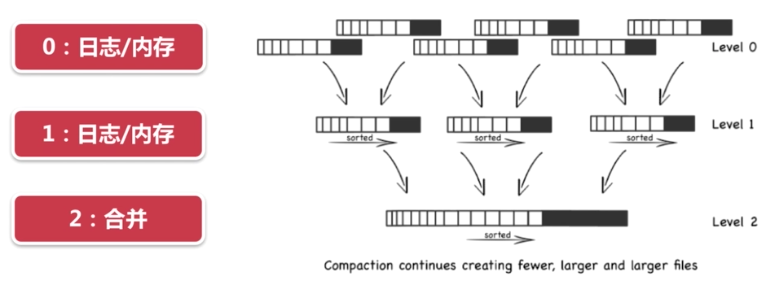
2.HBase数据存储模块简介
RegionServer = Region + Store + MemStore + StoreFile + HFile + HLog
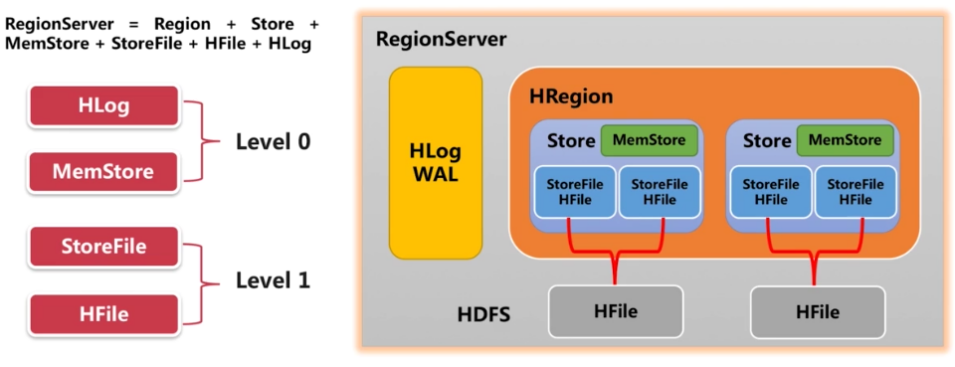
3.HBase Region解析
(1)什么是Region
每一个Region都会存储于确定的RegionServer上
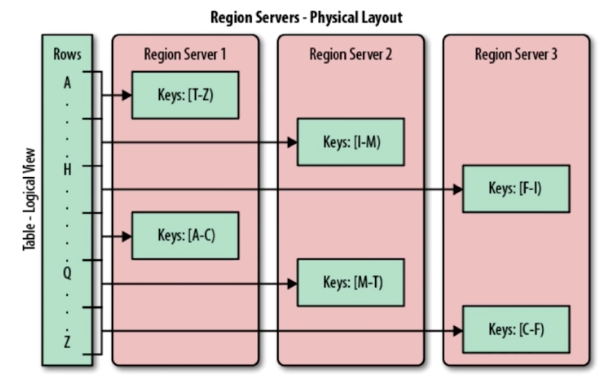
(2)Region特点
- 是HBase中分布式存储和负载均衡的最小单元
- Region的数据不能低于集群中节点的数量
- RegionServer对Region进行拆分
- 尽量让Row key分散到不同的Region
4.HBase HFile 解析
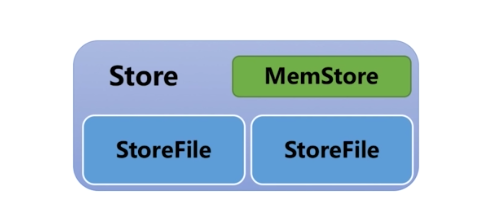
Store + MemStore + StoreFile
-
- Store与列簇是一对一的关系
- MemStore是一个内存数据结构,保存修改的数据
- StoreFile是由内存数据写入到文件后形成的
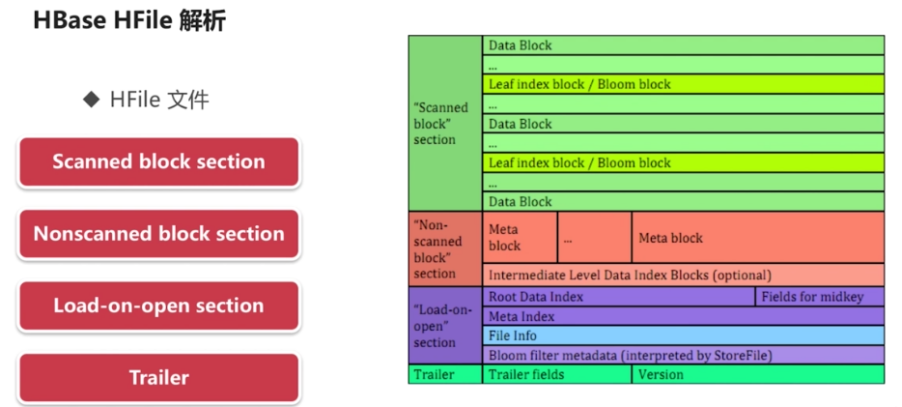
HFile 文件
-
- 是HBase存储数据文件的最基本的组织形式
- 底层是Hadoop的二进制格式文件
- 是用户数据的实际载体,存储Key-Value的数据
- Scanned block section:会被读取,主要是存储用户数据
- Nonscanned block section:不会被读取,主要包含元数据块
- Load-on-open section:RegionServer启动时加载,主要是HFile的元数据
- Trailer:HFile的基本信息,HFile元数据的一部分
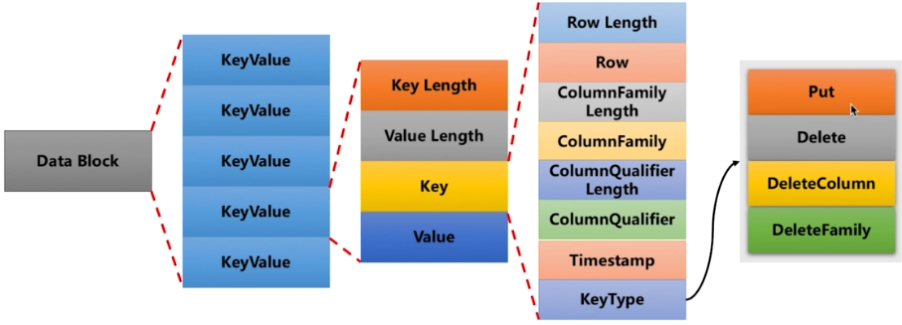
Data Block
-
- HBase中数据的最基本的存储单元
- 是实际存储用户数据的数据结构
- 包含很多Key-Value
5.HBase WAL解析
(1)WAL介绍(预写日志)
-
-
- WAL最重要的功能就是灾难恢复
- WAL解决了什么问题:HA(高可用)问题
- 解决:远程备份
-
(2)HLog
-
-
- WAL是通过HLog模块实现的
- HLog是什么:HLog是实现WAL的类,一个RegionServer对应一个HLog实例
-
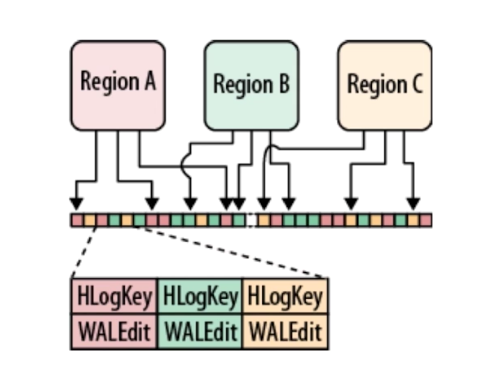
(3)HLogKey
WAL使用Hadoop的序列化文件将记录存储为Key-Value的数据集,Key就是HLog的Key

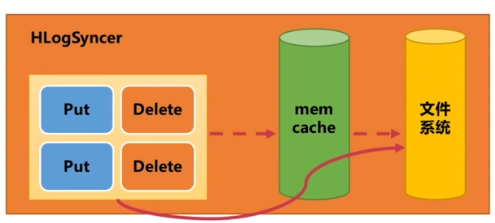
(4)HLogSyncer(日志同步刷写类)
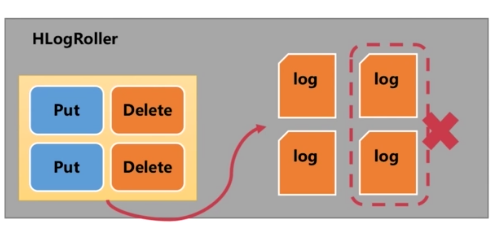
(5)HLogRoller
-
-
- 特点的时间去滚动日志,形成新的日志,避免单个日志文件过大
- 根据HLog的序列化的number对比已经持久化的HFile的序列号,删除旧的,不需要的日志
-
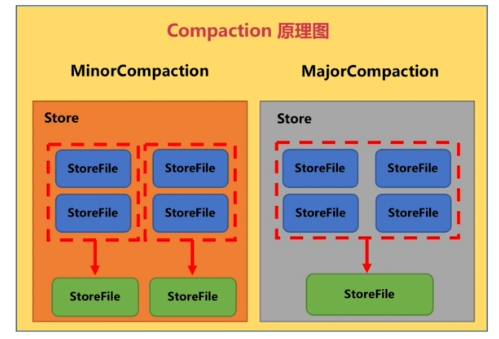
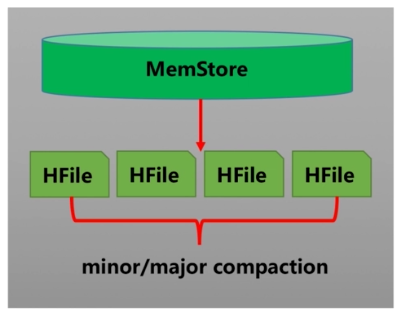
6.HBase Compaction解析
(1)Compaction介绍
Compaction会从一个Region的Store中选择一些HFile文件进行合并
(2)Compaction作业
随着系统不停的刷写,会导致存储目录中有过多的数据文件
(3)Compaction分类
-
-
- MinorCompaction:小合并
- MajorCompaction:大合并
-
(4)Compaction的触发时机
MemStore 内存数据写入到硬盘上
四、Hbase数据存取解析
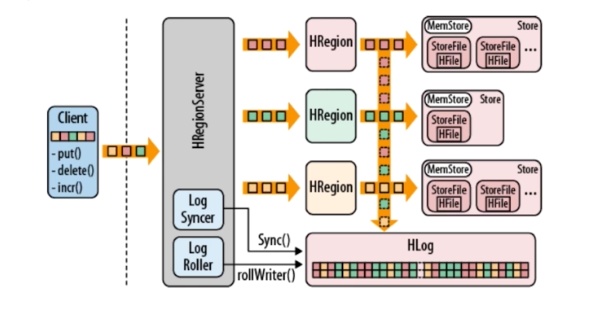
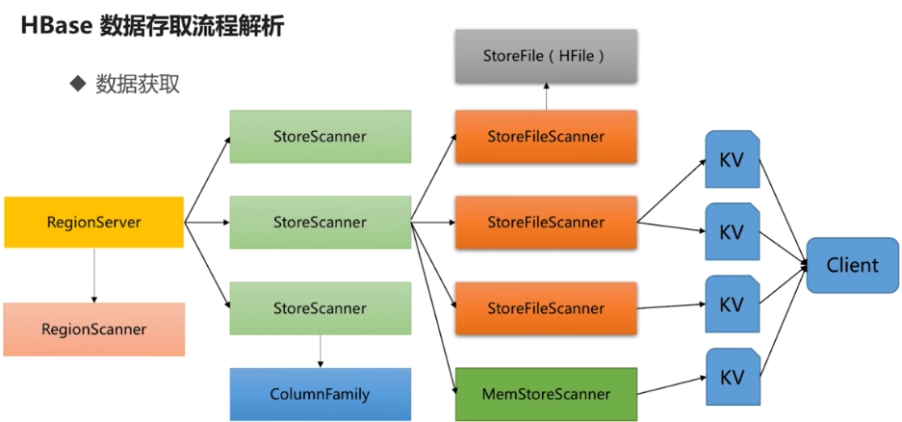
1.HBase数据存取流程解析
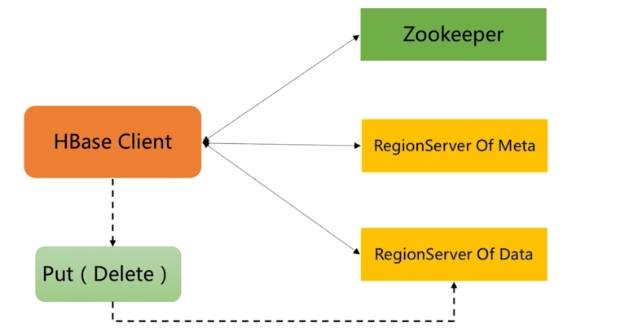
(1)数据存储
客户端:HBase Client
-
-
- 请求Zookeeper,确定 MetaTable所在RegionServer的地址
- 在根据RowKey找到归属的RegionServer
- HBase Client Put(Delete)数据,提交到RegionServer
-
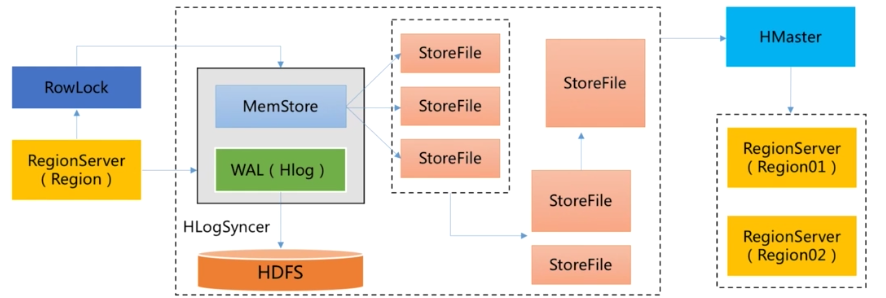
服务器:HBase Server
-
-
- Region Server 去获取行锁,Region更新共享锁
- 写HLog,WAL
- 写缓存,MemStore
- 将日志同步到HDFS
- 写满缓存后,启动异步线程将数据写入到硬盘上
- 可能触发Compaction或拆分
-
(2)数据获取
客户端:HBase Client
-
-
- 请求Zookeeper,确定 MetaTable所在RegionServer的地址
- 去对应的RegionServer地址拿到对应数据
-
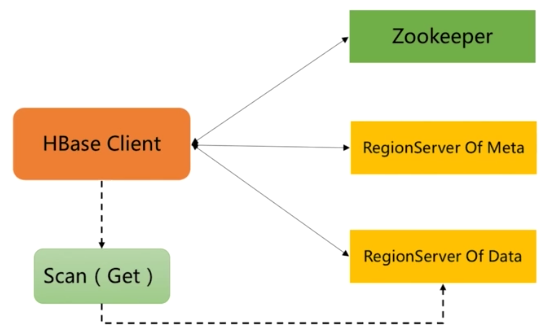
服务端:HBase Server
-
-
- Region Server 构建RegionScanner准备进行检索
- 有多少个列簇就构建多少个StoreScanner,用于对确定的列簇数据检索
-
2.HBase数据存取优化
(1)存储优化
(2)检索(获取)优化

3.HBase数据存取api介绍
(1)存储数据api介绍


 浙公网安备 33010602011771号
浙公网安备 33010602011771号