
流式计算的时间模型
link有三种时间模型:ProcessingTime,EventTime和IngestionTime。
关于时间模型看这张图: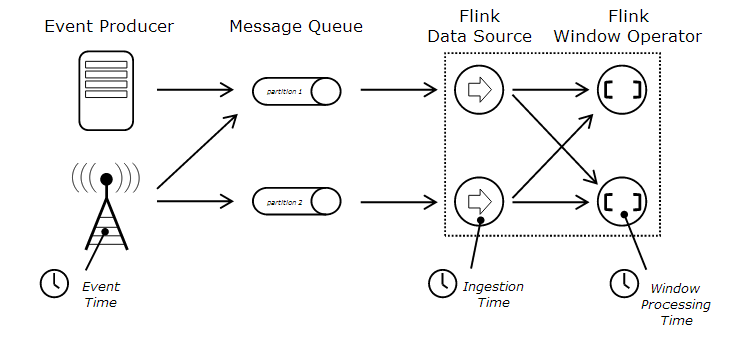
从这张图里可以很清楚的看到三种Time模型的区别。
- EventTime是数据被生产出来的时间,可以是比如传感器发出信号的时间等(此时数据还没有被传输给flink)。
- IngestionTime是数据进入flink的时间,也就是从Source进入flink流的时间(此时数据刚刚被传给flink)
- ProcessingTime是针对当前算子的系统时间,是指该数据已经进入某个operator时,operator所在系统的当前时间
例如,我在写这段话的时间是2018年5月13日03点47分,但是我引用的这张EventTime的图片,是2015年画出来的,那么这张图的EventTime是2015年,而ProcessingTime是现在。
Flink官网对于时间戳的解释非常详细:点我
Flink对于EventTime模型的实现,依赖的是一种叫做watermark的对象。watermark是携带有时间戳的一个对象,会按照程序的要求被插入到数据流中,用以标志某个事件在该时间发生了。
我再做一点简短的说明,还是以官网的图为例:
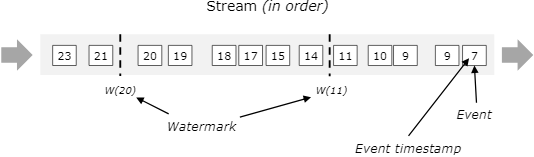
对于有序到来的数据,假设我们在timestamp为11的元素后加入一个watermark,时间记录为11,则下个元素收到该watermark时,认为所有早于11的元素均已到达。这是非常理想的情况。
而在现实生活中,经常会遇到乱序的数据。这时,我们虽然在timestamp为7的元素后就收到了11,但是我们一直等到了收到元素12之后,才插入了watermark为11的元素。与上面的图相比,如果我们仍然在11后就插入11的watermark,那么元素9就会被丢弃,造成数据丢失。而我们在12之后插入watermark11,就保证了9仍然会被下一个operator处理。当然,我们不可能无限制的永远等待迟到元素,所以要在哪个元素后插入11需要根据实际场景权衡。
对于来自多个数据源的watermark,可以看这张图: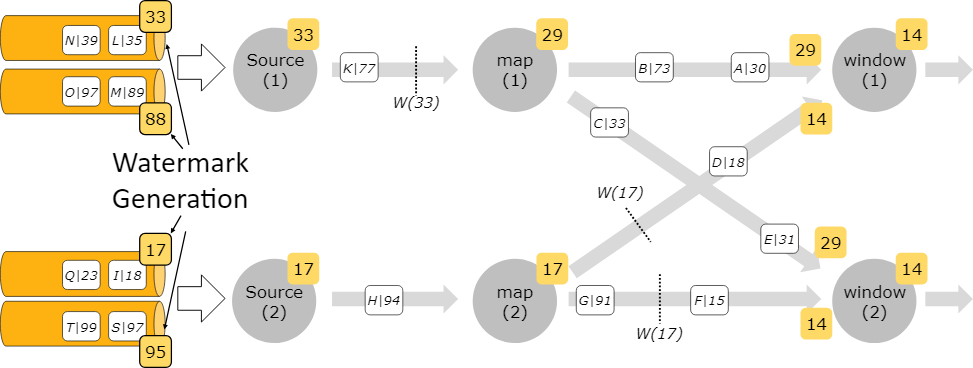
可以看到,当一个operator收到多个watermark时,它遵循最小原则(或者说最早),即算子的当前watermark是流经该算子的最小watermark,以容许来自不同的source的乱序数据到来。
关于事件时间模型,更多内容可以参考Stream 101 和谷歌的这篇论文:Dataflow Model paper
