

流式计算的背压问题
在流模型中,我们期待数据是像水流一样平滑的流过我们的引擎,但现实生活不会这么美好。数据的上游可能因为各种原因数据量暴增,远远超出了下游的瞬时处理能力(回忆一下98年大洪水),导致系统崩溃。
那么框架应该怎么应对呢?和人类处理自然灾害的方式类似,我们修建了三峡大坝,当洪水来临时把大量的水囤积在大坝里;对于Flink来说,就是在数据的接收端和发送端放置了缓存池,用以缓冲数据,并且设置闸门阻止数据向下流。
那么Flink又是如何处理背压的呢?答案也是靠这些缓冲池。
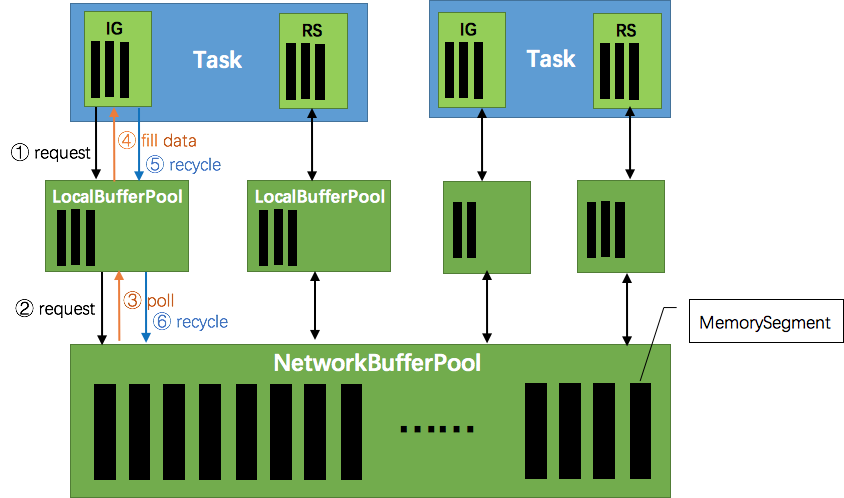
这张图说明了Flink在生产和消费数据时的大致情况。ResultPartition和InputGate在输出和输入数据时,都要向NetworkBufferPool申请一块MemorySegment作为缓存池。
接下来的情况和生产者消费者很类似。当数据发送太多,下游处理不过来了,那么首先InputChannel会被填满,然后是InputChannel能申请到的内存达到最大,于是下游停止读取数据,上游负责发送数据的nettyServer会得到响应,停止从ResultSubPartition读取缓存,那么ResultPartition很快也将存满数据不能被消费,从而生产数据的逻辑被阻塞在获取新buffer上,非常自然地形成背压的效果。
个人网站:shuoyizui.com
公众号:写个框架玩
近期在公众号会发布一系列文章,主要是想完成一个简化的MapReduce框架的编写。实现Mapreduce编程模型、任务远程提交、任务分配、任务执行等功能。设计到了动态代理、反射、网络通信、序列化、消息队列、netty、自定义类加载器、多线程、shell等技术点。
