大数据学习(一)
一、基本概念
1.大数据应用,一般涵盖数据采集、数据预处理、数据分析、最终为数据消费者提供各类应用(特别是可视化展示和操作)等过程。
2.大数据体系架构
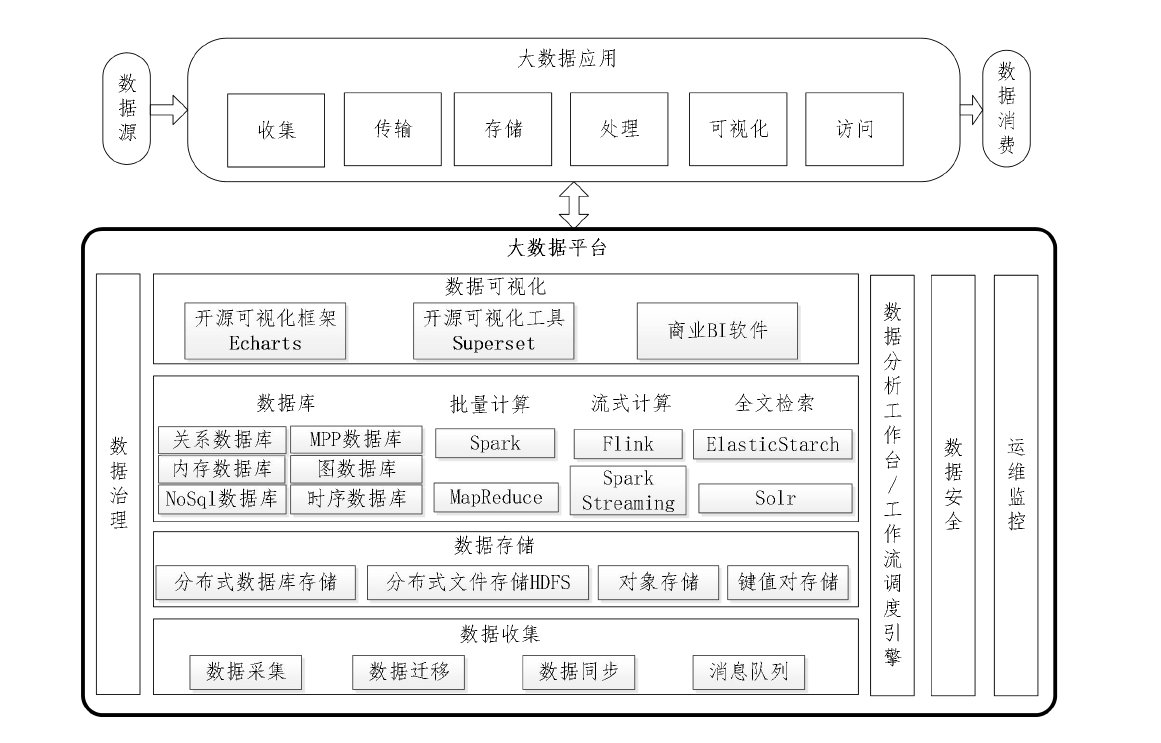
3.数据采集
(1)数据源:日志文件数据;数据库数据;网络数据(特指爬虫抓取数据);设备数据(通常指设备运行过程自身产生的、发生业务产生的数据。)
(2)采集工具:
a、Filebeat
b、Flume
c、KafkaAppender
d、Canal
e、Scrapy
4.数据传输
数据迁移工具有Sqoop、DataX等;数据传输消息队列有:Kafka、RabbitMQ等
(1)Sqoop是一个分布式的数据迁移工具,主要用于解决关系型数据库与Hadoop平台的数据交互。
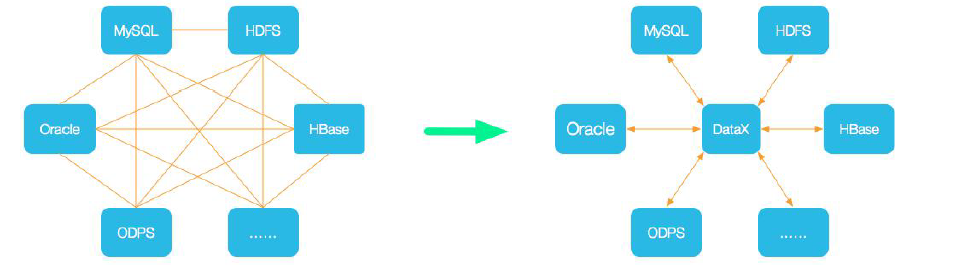
(2)DataX是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。主要利用datax实现同构数据源、异构数据源的抽取、数据转换、数据清洗。
(3)Kafka
Kafka是一种高吞吐量的分布式发布订阅消息系统,同时也是一个分布式流处理平台。
(4)RabbitMQ
是实现了高级消息队列协议的开源消息代理软件(亦称面向消息的中间件)
5.数据存储
(1)对于海量结构化的数据、文本数据,可以使用分布式文件存储hdfs和hive作为数据仓库
(2)对于海量非结构化数据,可以选择MongoDB、HBase;
(3)对海量文档数据,为快速查询,可以选择分布式文档搜索引擎Elasticsearch;
(4)为快速查询、更新键值数据,可以选择键值存储数据库Redis、Codis等
(5)为实体关系进行存储,可以选择分布式图数据库JanusGraph,ArangoDB
(6)为对海量对象数据进行存储,可以选择Ceph、Minio、FastDFS、SeaweedFS、HBase等;
(7)为对时序数据进行存储,可以选择Prometheus、Influxdb、opentsdb等。
5.2 相关产品和工具
5.2.1 HDFS 分布式文件存储系统
5.2.2 Hive 分布式关系数据仓库
5.2.3 Elasticsearch
5.2.4 Redis 键值存储数据库,主要用于高速缓存,通过key-value的方式实现数据的快速读写。
5.2.5 HBase 分布式列式存储数据库,能够实现在大量的数据中查询记录,也可以从中获得综合分析报告。
5.2.6 MongoDB是一个基于分布式文件存储的数据库,最大的特点是它支持的查询语言非常强大。
5.2.7 JanusGraph是一个图形数据库引擎
6.数据处理
数据处理方法:离线处理、实时处理、交互查询、实时检索等不同的数据处理方法。,通常大数据处理技术或工具主要有海量数据计算分析的Mapreduce、Spark、Greenplum、Hive SQL、Spark SQL、Spark Streaming、Flink
7.数据可视化
数据可视化是大数据技术在各行业应用中的关键技术,在大数据分析结果可视化需求较少时,可以基于开源的可视化组件Echart.js、d3.js来开发数据展示,也可以使用开源的可视化工具Superset、Saiku、metabase、Tableau public;而对于较多可视化展示、可以借助于商务BI软件,比如永洪BI、亿信华辰ABI数据展示工作。
7.2.1 Echarts
8.数据分析工作台
9.数据治理
对Hadoop生态系统数据流通的元数据管理,可以使用Apache Atlas;DataHub是一款源数据搜索与发现的工具。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号