


Hadoop生态圈学习-1(理论基础)
一.大数据技术产生的背景
1. 计算机和信息技术(尤其是移动互联网)的迅猛发展和普及,行业应用系统的规模迅速扩大(用户数量和应用场景,比如facebook、淘宝、微信、银联、12306等),行业应用所产生的数据呈爆炸式增长。
2. 动辄达数数百PB甚至EB(1EB=1024PB=1024*1024TB)规模的数据已远超出传统计算机和信息系统的处理能力。
3. 有效的大数据处理技术、方法和手段已成为迫切需求。
Google的三驾马车为大数据的发展奠定十分重要的基础.
Google的三驾马车(非常重要):三篇论文---> 思想、原理
1、GFS:google file system ---> HDFS:Hadoop Distributed File System
都是分布式文件系统,用于解决大数据的存储问题。
什么是倒排索引?Reverted Index
倒排索引:
假如要在搜索关键词"大数据",如果只有正向索引 , 那可能需要耗费非常多的时间全表扫描 ,然后关键词为"大数据"的记录 , 数据量庞大的情况下这个过程慢的无法让人发指,
所以有了倒排索引,搜索引擎会将正向索引重新构建为倒排索引,即把文件ID对应到关键词的映射转换为关键词到文件ID的映射,每个关键词都对应着一系列的文件,这些文件中都出现这个关键词。
通俗说:
通过数据,找地址
2、MapReduce计算模型:问题来源PageRank(先拆分成多个小任务计算 , 再合并计算)
3、BigTable大表 ----> NoSQL数据库:HBase(牺牲空间 , 来换取时间)
二.大数据的应用场景
百度春节人口迁徙,2014 年春节,百度推出了“百度迁徙”,其利用大数据技术,对其拥有 的 LBS(基于地理位置的服务)大数据进行计算分析,并采用创新的“可视化”呈现方式, 在业界首次实现了全程、动态、即时、直观地展现中国春节前后人口大迁徙的轨迹与特 征,如图 1-3所示。(查询网址:http://qianxi.baidu.com/。)

(1)数据的存储:分布式文件系统(GFS、HDFS等等)
(2)数据的计算:分布式计算模型(MapReduce、Spark RDD等等)
两个方向:离线计算:Hadoop MapReduce、Spark Core、Flink DataSet
实时计算:Storm、Spark Streaming、Flink DataStream
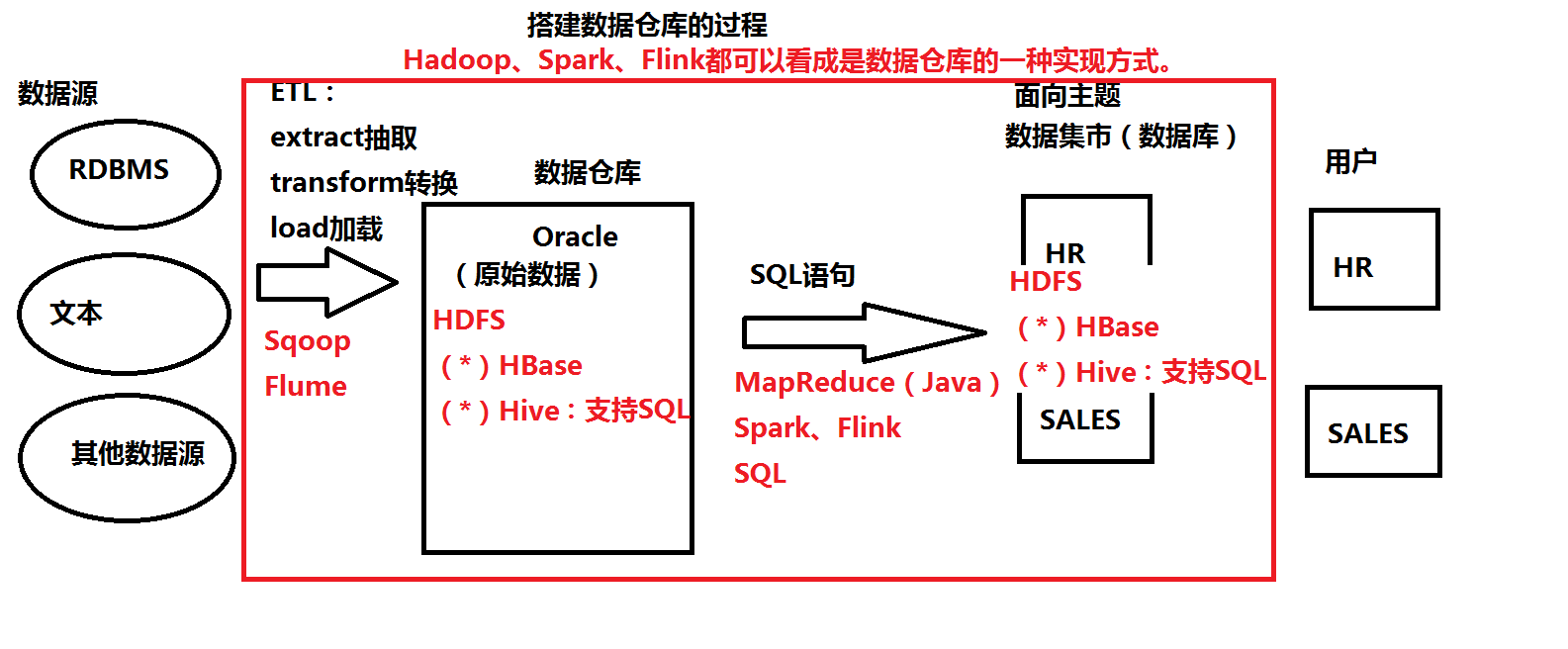
四.数据仓库
传统的数据仓库:Oracle、MySQL等
大数据:Hadoop、Spark、Flink都可以看成是数据仓库的一种实现方式
概念:OLTP与OLAP
数据仓库又是一种OLAP的系统
OLTP:online transaction processing 联机事务处理
insert update delete commit rollback
特点:ACID 原子性、一致性、持久性、隔离性 -----> 关系型数据库
OLAP:online analytic processing 联机分析处理
一般:select
不关心事务
五.Hadoop生态圈的体系机构(Apache 简单版)


